

Python学习笔记其四
Pytorch教程
搭建一个神经网络

PyTorch 常用层讲解与示例
本教程介绍 PyTorch 中一些核心神经网络层:Linear、Conv2d、LSTM,包括它们的数学公式和对应实现代码。
1. Linear 层 (全连接层)
数学公式:
输入向量 ,输出向量 :
解释:
- 每个输出节点是输入节点的加权和加上偏置
- 常用于全连接网络、MLP 等
示例代码:
import torchimport torch.nn as nn
class LinearExample(nn.Module): def __init__(self, d_in, d_out): super().__init__() self.linear = nn.Linear(d_in, d_out)
def forward(self, x): return self.linear(x)
# 示例x = torch.randn(4, 10)model_linear = LinearExample(10, 5)y = model_linear(x)print("Linear 输出形状:", y.shape)2. Conv2d 层 (二维卷积层)
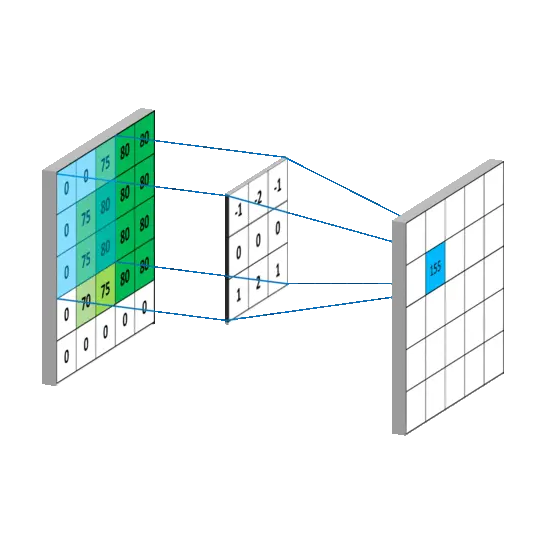
数学公式:
输入张量 ,卷积核 :
解释:
- 对每个输出通道,卷积核在输入各通道上进行加权求和,并加偏置
- 常用于图像特征提取、卷积神经网络
示例代码:
import torchimport torch.nn as nn
class Conv2dExample(nn.Module): def __init__(self, in_channels, out_channels, kernel_size): super().__init__() self.conv = nn.Conv2d(in_channels, out_channels, kernel_size)
def forward(self, x): return self.conv(x)
# 示例x_img = torch.randn(2, 3, 32, 32) # batch_size=2, 3通道, 32x32图像model_conv = Conv2dExample(3, 6, 5) # 输出6个通道, kernel 5x5y_img = model_conv(x_img)print("Conv2d 输出形状:", y_img.shape)PyTorch 激活函数详解
本教程介绍常用激活函数。
1. ReLU
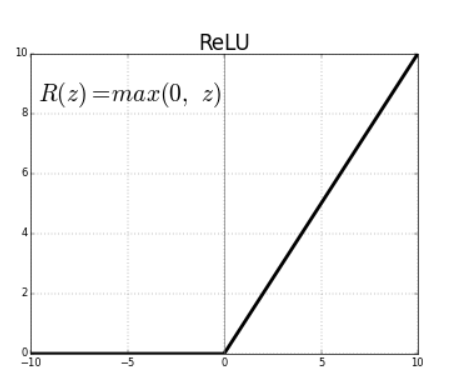
数学公式:
解释:
- 将小于0的输入置0,大于0保持不变
- 计算简单,常用于卷积层或全连接层后
import torchimport torch.nn as nn
relu = nn.ReLU()x = torch.tensor([[-1.0, 0.0, 2.0]])y = relu(x)print("ReLU 输出:\n", y)2. Sigmoid
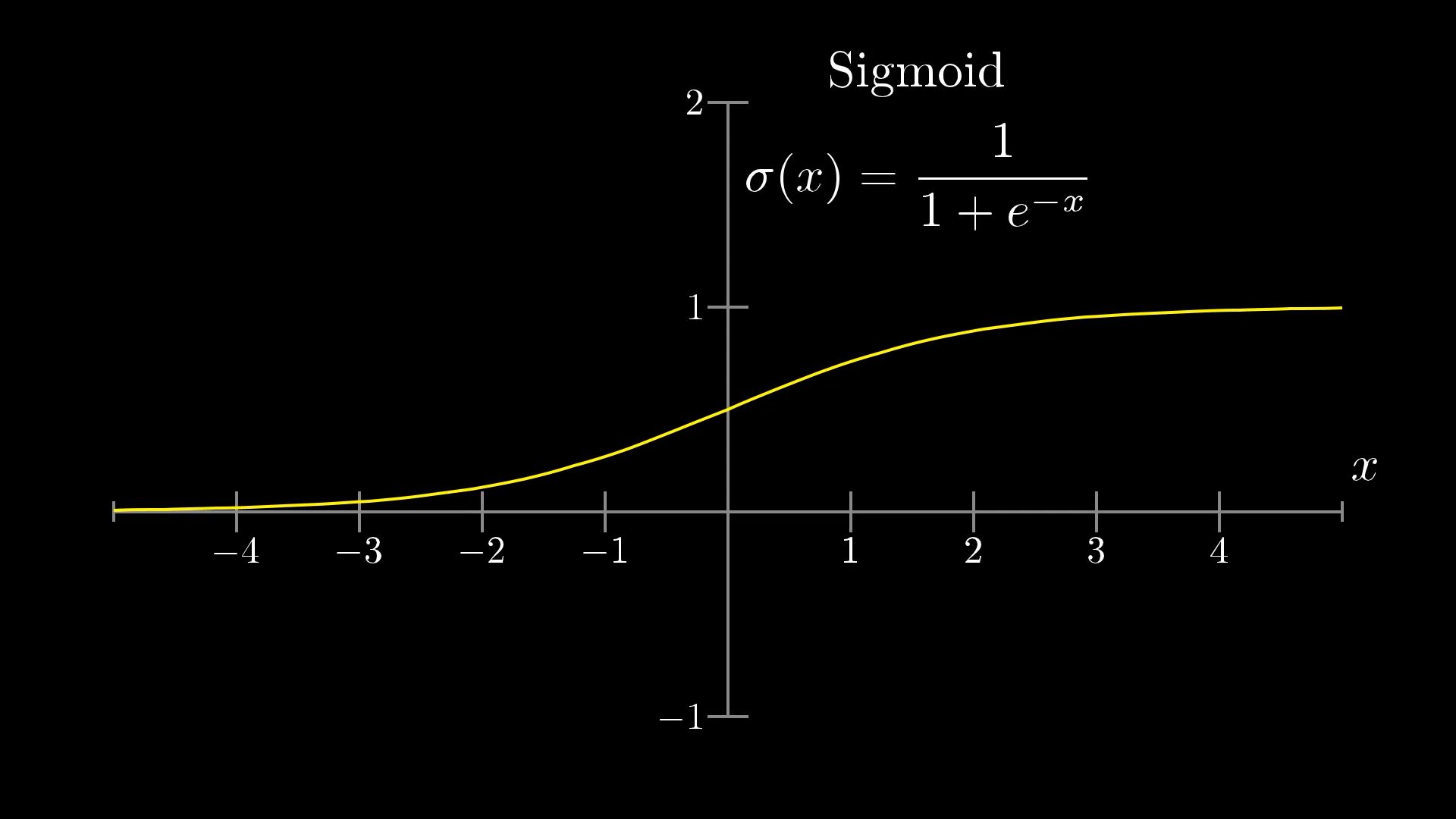
数学公式:
解释:
- 将输入映射到 (0,1)
- 常用于二分类输出层
import torchimport torch.nn as nn
sigmoid = nn.Sigmoid()x = torch.tensor([[-1.0, 0.0, 2.0]])y = sigmoid(x)print("Sigmoid 输出:\n", y)3. Tanh
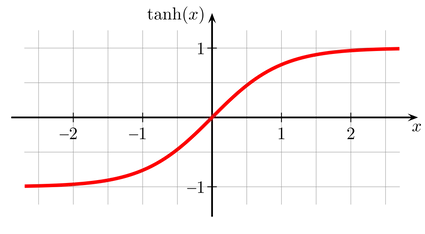
数学公式:
解释:
- 将输入映射到 (-1, 1)
- 均值为 0,有助于训练收敛
- 常用于序列模型或隐藏层激活函数
import torchimport torch.nn as nn
tanh = nn.Tanh()x = torch.tensor([[-1.0, 0.0, 2.0]])y = tanh(x)print("Tanh 输出:\n", y)4. LeakyReLU
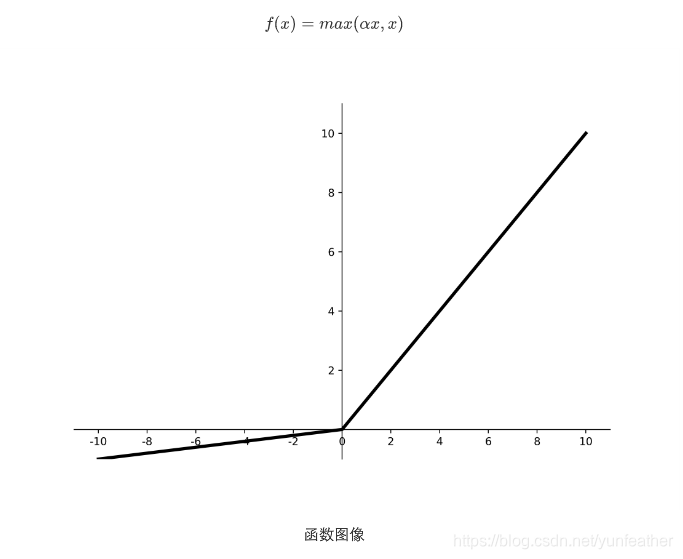
数学公式:
解释:
- 避免 ReLU 的“死亡神经元”问题
- 对负值仍保留小梯度,不完全置零
- 常用于卷积层或全连接层激活函数
import torchimport torch.nn as nn
leaky_relu = nn.LeakyReLU(negative_slope=0.01)x = torch.tensor([[-1.0, 0.0, 2.0]])y = leaky_relu(x)print("LeakyReLU 输出:\n", y)PyTorch 常见损失函数详解
本教程介绍 PyTorch 中常用的损失函数,包括均方误差损失、交叉熵损失和 KL 散度损失,包含数学公式、原理解释和示例代码。
1. MSELoss(均方误差损失)
数学公式:
解释:
- 用于回归任务
- 衡量预测值 与真实值 的平方差
- 对异常值较敏感
import torchimport torch.nn as nn
mse_loss = nn.MSELoss()y_pred = torch.tensor([0.5, 0.8, 1.2])y_true = torch.tensor([0.0, 1.0, 1.0])loss = mse_loss(y_pred, y_true)print("MSELoss:", loss.item())2. CrossEntropyLoss(交叉熵损失)
数学公式(多分类):
解释:
- 用于分类任务
- 是真实类别的 one-hot 编码,
是预测概率
- PyTorch 的
CrossEntropyLoss内部包含Softmax,不需要手动计算概率
示例代码:
import torchimport torch.nn as nn
cross_entropy = nn.CrossEntropyLoss()y_pred = torch.tensor([[2.0, 1.0, 0.1]]) # logitsy_true = torch.tensor([0]) # 类别索引loss = cross_entropy(y_pred, y_true)print("CrossEntropyLoss:", loss.item())3. KLDivLoss(KL 散度损失)
数学公式:
解释:
- 用于衡量两个概率分布 和 的差异
- 常用于知识蒸馏或概率分布拟合
- PyTorch 要求输入为 log 概率(
log_target=False时输入为 log 概率)
示例代码:
import torchimport torch.nn as nnimport torch.nn.functional as F
kl_div = nn.KLDivLoss(reduction='batchmean')p = F.log_softmax(torch.tensor([[0.2, 0.5, 0.3]]), dim=1)q = torch.tensor([[0.1, 0.6, 0.3]])loss = kl_div(p, q)print("KLDivLoss:", loss.item())PyTorch 容器(Container)详解
PyTorch 提供了一些容器类,用于组织和管理多个子模块,常用的有 Sequential、ModuleList、ModuleDict。
1. nn.Sequential
- 功能:将多个子模块按顺序组合成一个整体,前一个模块的输出作为下一个模块的输入
- 使用场景:简单的前向顺序网络,如 MLP 或简单 CNN
示例代码:
import torchimport torch.nn as nn
model_seq = nn.Sequential( nn.Linear(10, 20), nn.ReLU(), nn.Linear(20, 5))
x = torch.randn(2, 10)y = model_seq(x)print("Sequential 输出形状:", y.shape)2. nn.ModuleList
- 功能:保存任意数量的子模块的列表,但不会定义前向计算的顺序,需要在
forward中手动调用 - 使用场景:动态网络结构、多分支网络
import torchimport torch.nn as nn
layers = nn.ModuleList([nn.Linear(10, 10) for _ in range(3)])x = torch.randn(2, 10)for layer in layers: x = layer(x)print("ModuleList 输出形状:", x.shape)3. nn.ModuleDict
- 功能:以字典形式保存子模块,便于按名字访问
- 使用场景:多分支或命名网络结构
import torchimport torch.nn as nn
layer_dict = nn.ModuleDict({ 'fc1': nn.Linear(10, 20), 'relu': nn.ReLU(), 'fc2': nn.Linear(20, 5)})
x = torch.randn(2, 10)x = layer_dict['fc1'](x)x = layer_dict['relu'](x)y = layer_dict['fc2'](x)print("ModuleDict 输出形状:", y.shape)优化器模块
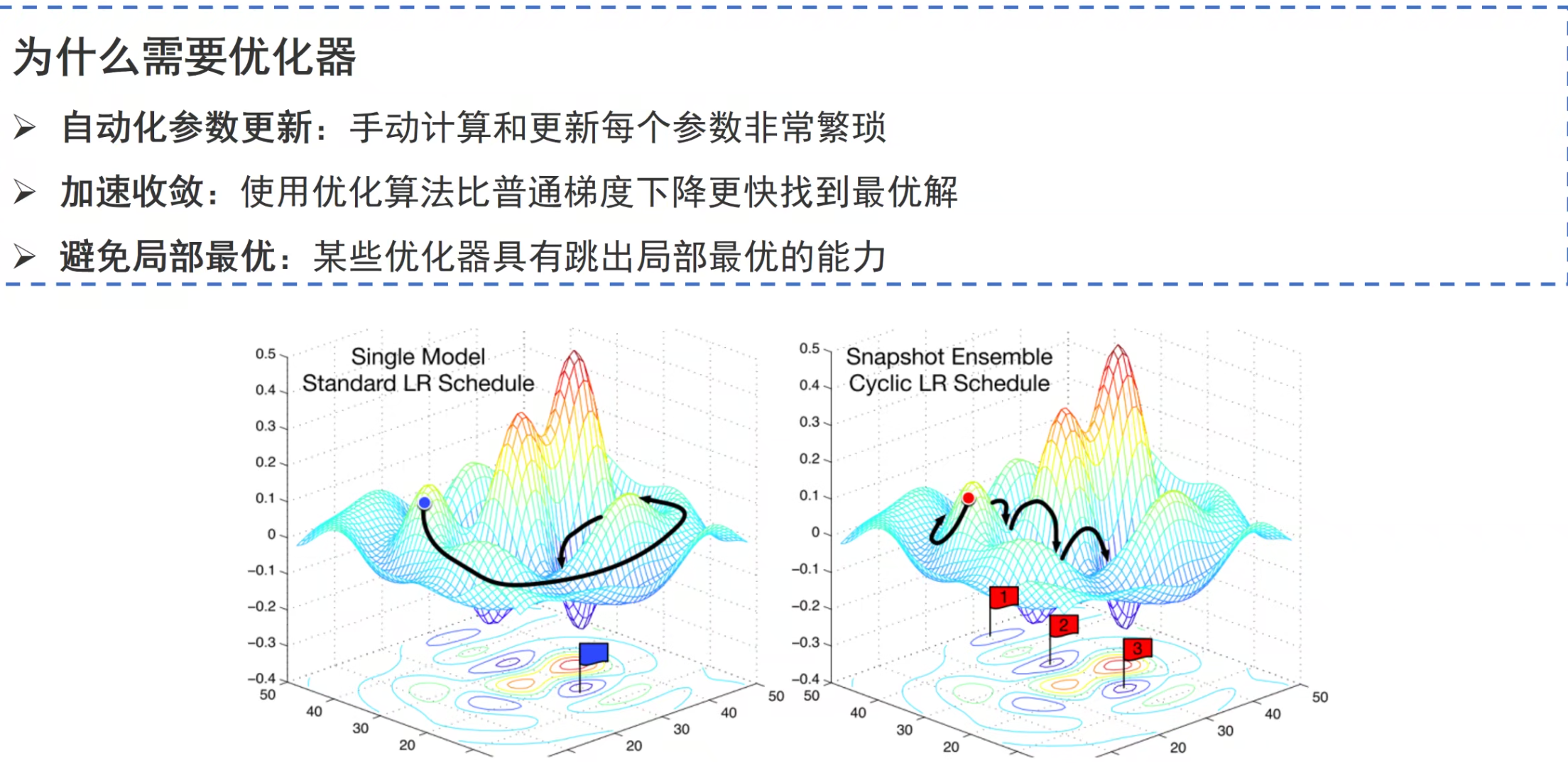

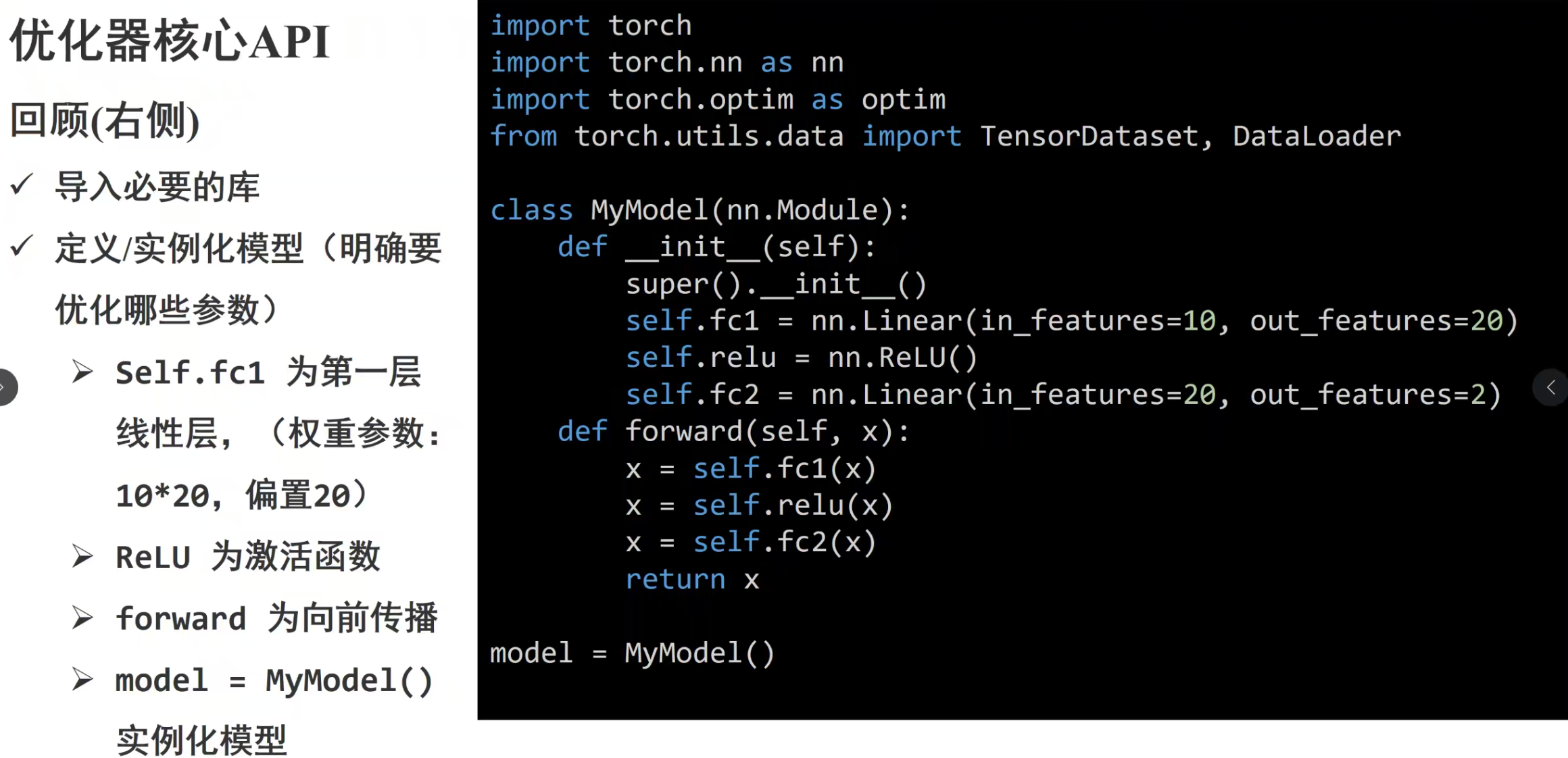
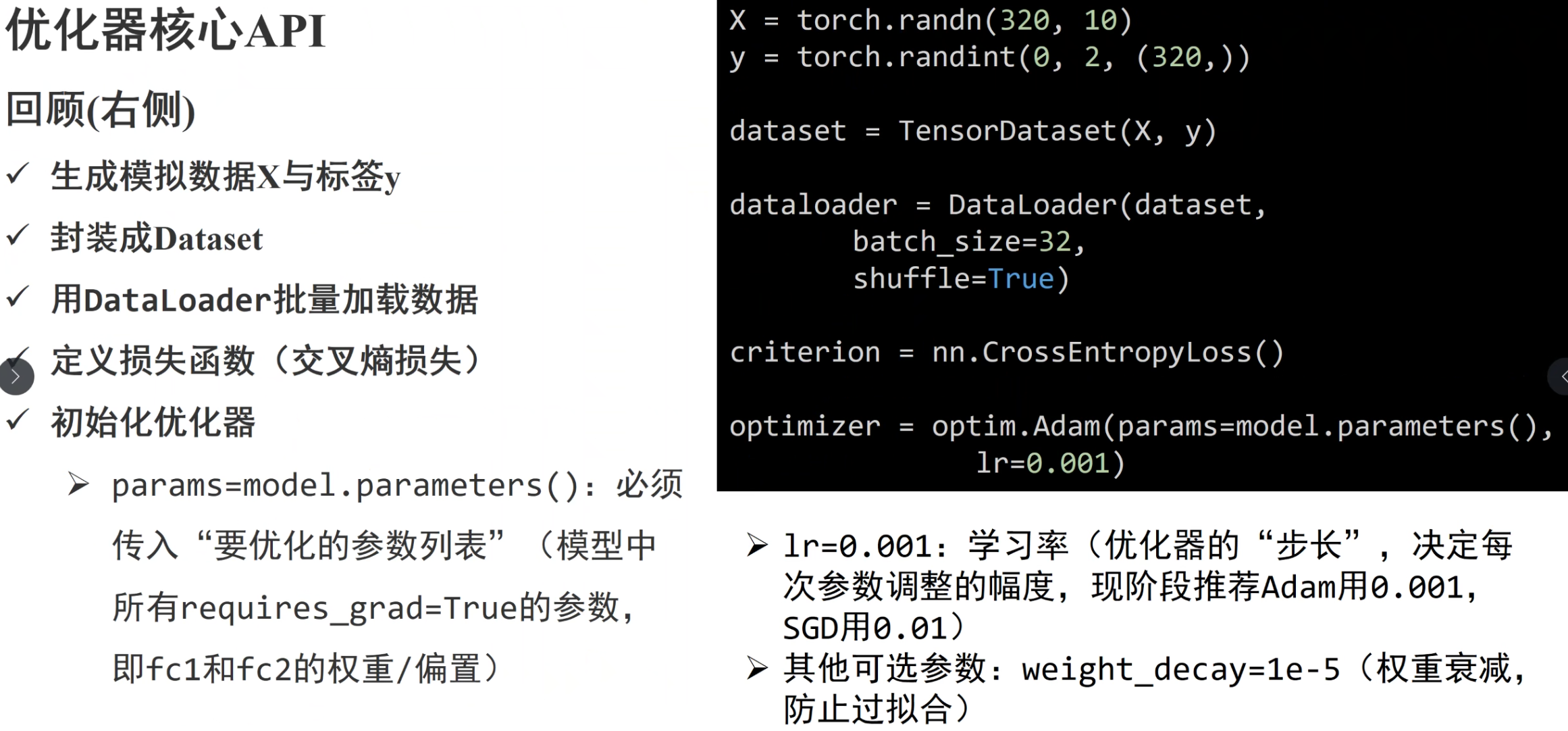

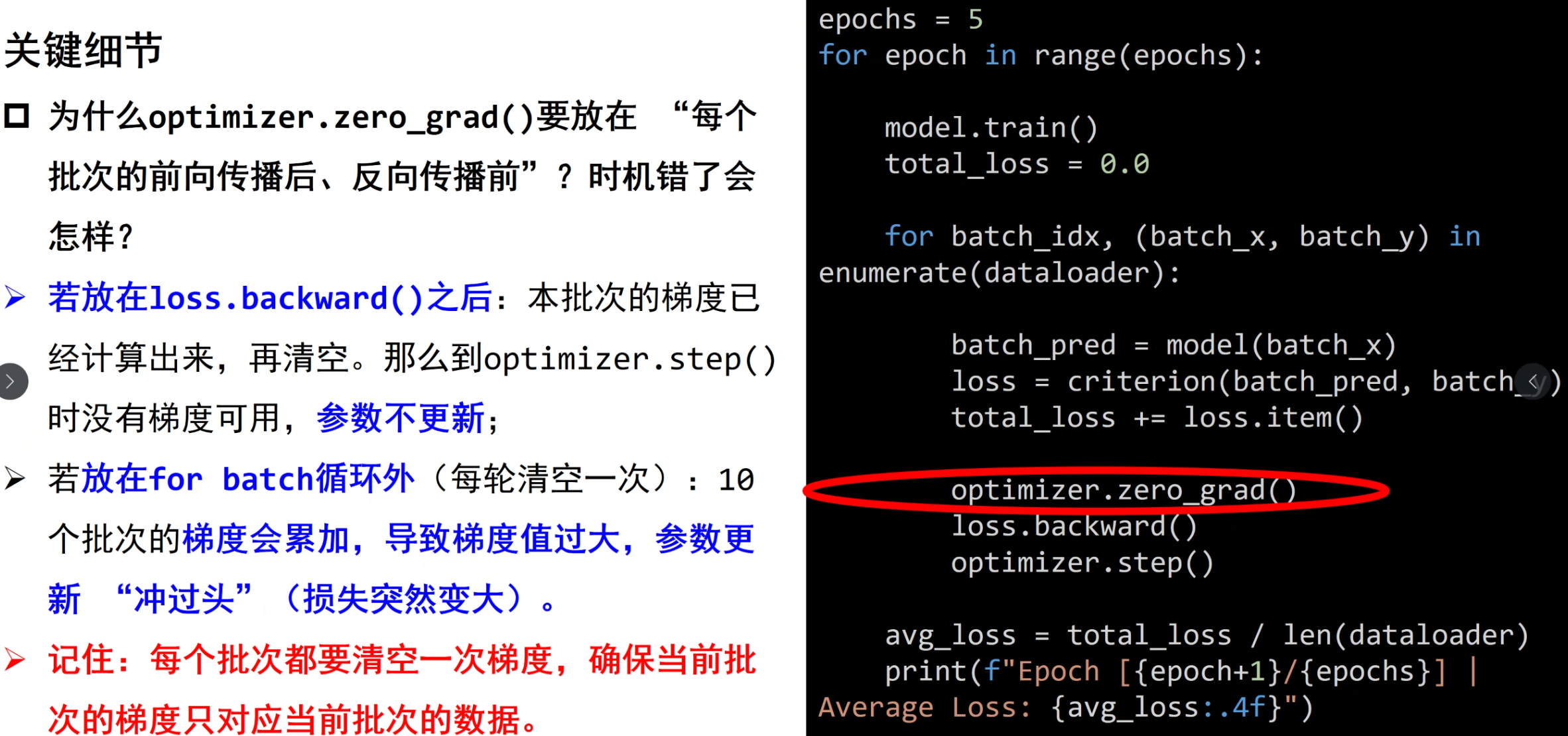
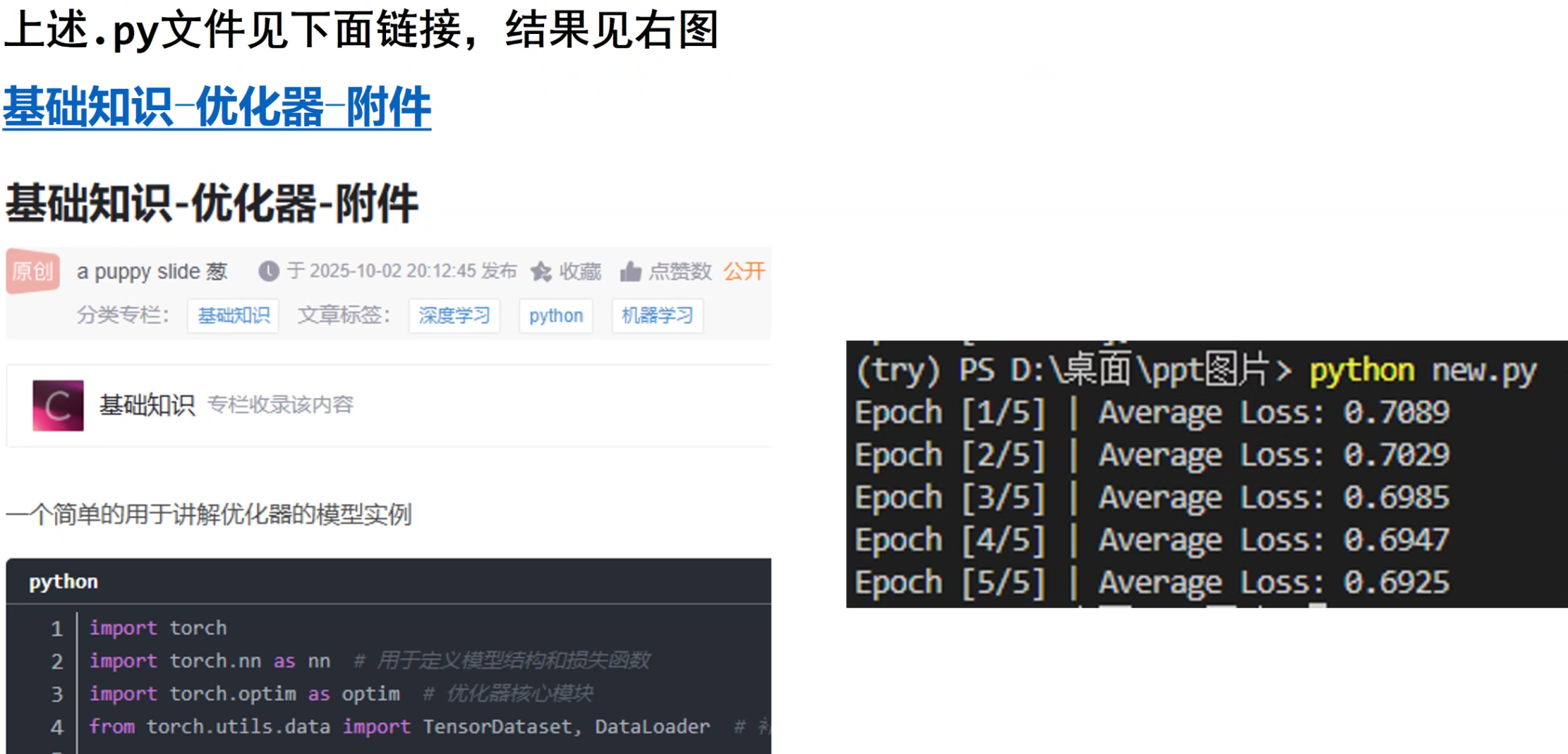
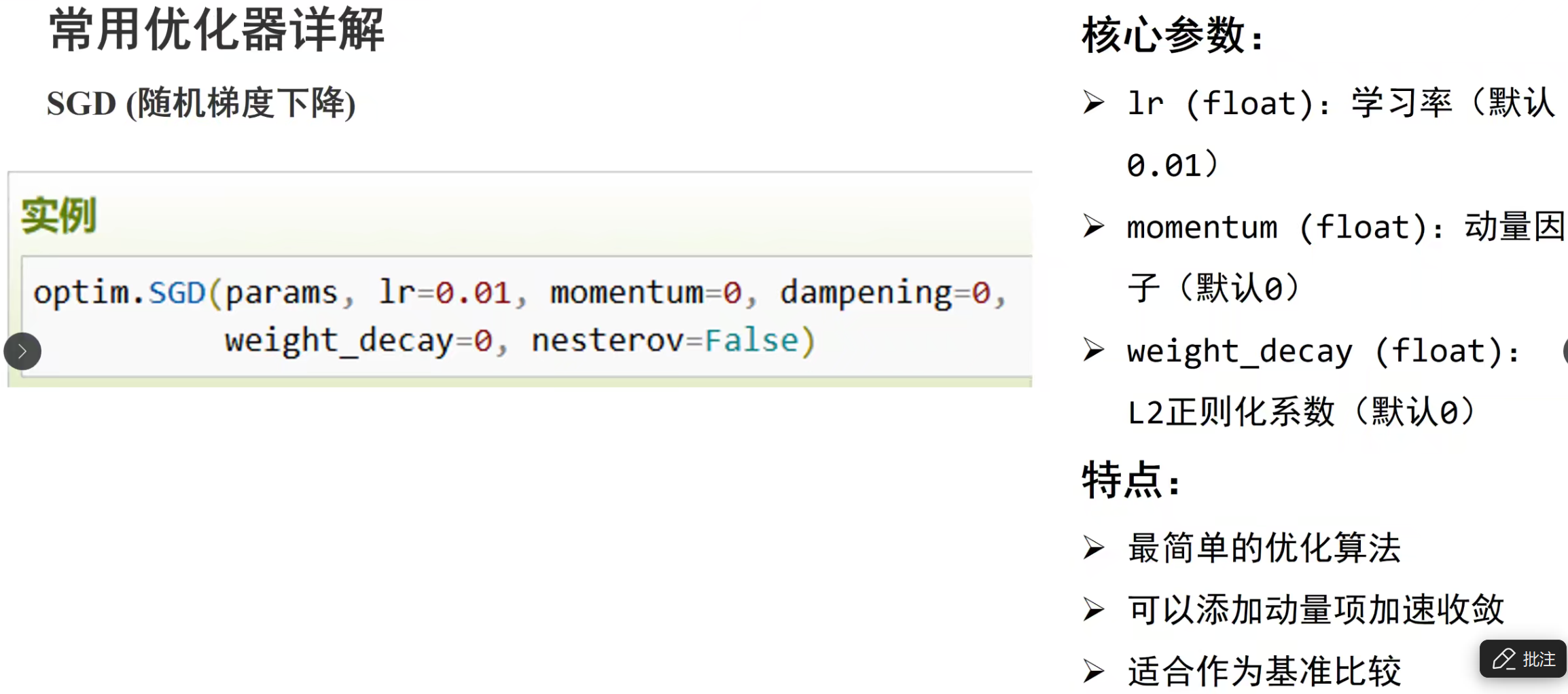

PyTorch 神经网络基础:__init__ 与 forward 方法详解
在 PyTorch 中,自定义神经网络类通常继承自 nn.Module,核心方法是 __init__ 和 forward。下面以一个简单的全连接网络为例进行讲解。
1. 模型代码示例
import torchimport torch.nn as nn
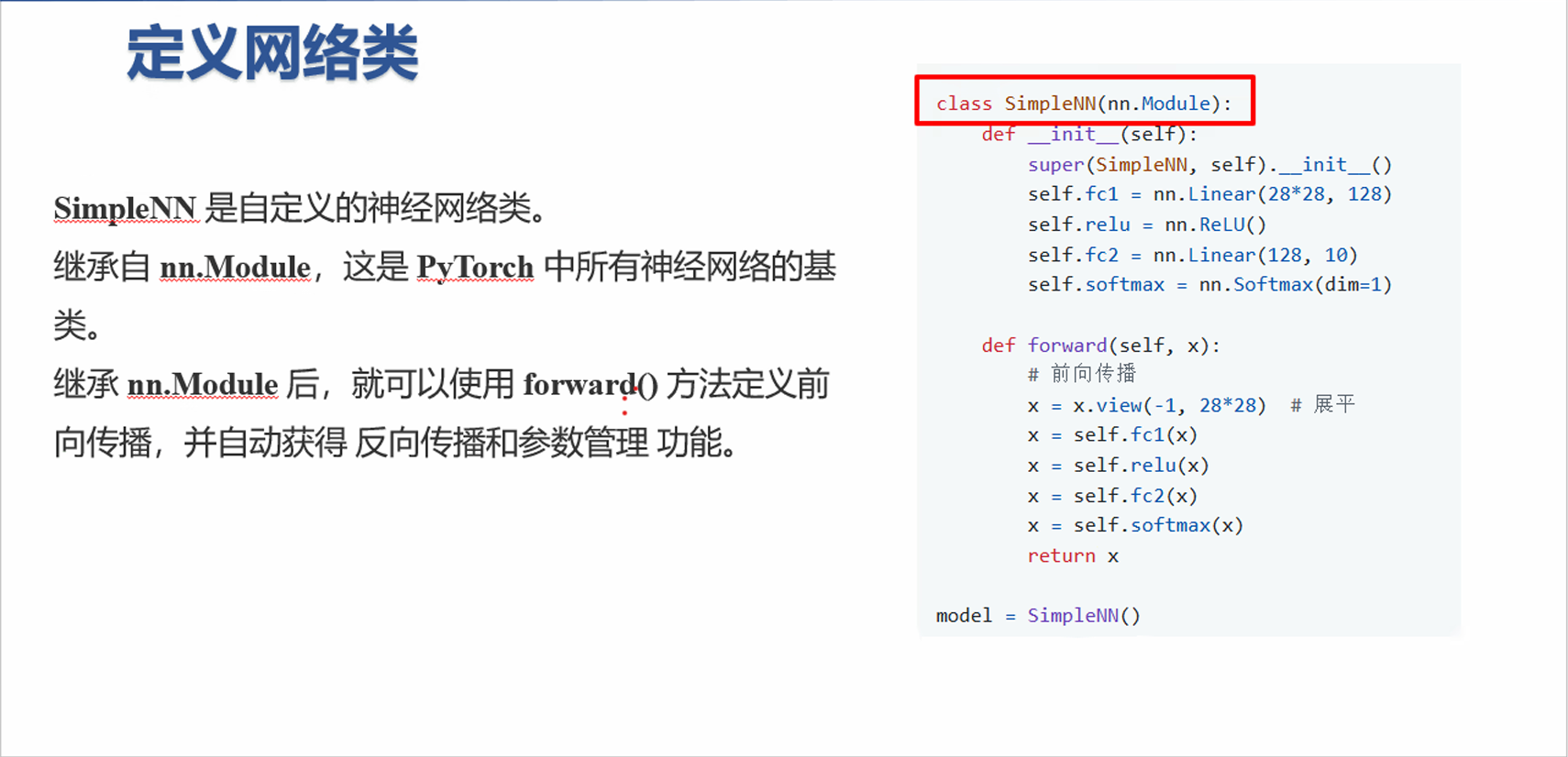
class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() # 定义网络结构 self.fc1 = nn.Linear(28*28, 128) # 全连接层1 self.relu = nn.ReLU() # 激活函数 self.fc2 = nn.Linear(128, 10) # 全连接层2 self.softmax = nn.Softmax(dim=1) # 输出概率归一化
def forward(self, x): # 前向计算流程 x = x.view(-1, 28*28) # 展平输入为 (batch_size, 784) x = self.fc1(x) # 第一个全连接层 x = self.relu(x) # ReLU 激活 x = self.fc2(x) # 第二个全连接层 x = self.softmax(x) # Softmax 转为概率分布 return x
# 创建模型实例model = SimpleNN()2. 方法详解
2.1 __init__ 方法
作用:定义网络的各层,包括线性层、卷积层、激活函数等。
特点:
- 仅声明网络结构,不进行前向计算。
- 注册子模块,便于 PyTorch 自动管理参数。
2.2 forward 方法
作用:定义数据的前向传播流程。
特点:
- 输入 会依次经过各个层,输出最终结果。
- PyTorch 自动重载
__call__方法,调用模型实例时会触发forward。
示例:
output = model(input_tensor)- 相当于执行:
model.forward(input_tensor)- 无需手动调用 forward 方法。
3. 数据流说明
- 输入图像张量 展平成 。
- 经过第一个全连接层
fc1,输出 。 - 通过 ReLU 激活函数,增加非线性。
- 经过第二个全连接层
fc2,输出 。 - 通过 Softmax 将输出转为概率分布,适合分类任务。
这种结构是典型的全连接神经网络(MLP)分类模型。
这种结构是典型的全连接神经网络(MLP)分类模型。
4. 补充说明
nn.Linear(in_features, out_features):创建全连接层,将输入特征维度 映射到输出维度 。nn.ReLU():激活函数,增加网络非线性能力。nn.Softmax(dim=1):对指定维度做归一化,使输出值可以看作概率分布。x.view(-1, 28*28):将输入张量展平成二维,-1表示自动计算 batch size。- 在 PyTorch 中,所有
nn.Module的子模块都会自动注册为模型参数,无需手动管理。
PyTorch 手写体图像识别教学
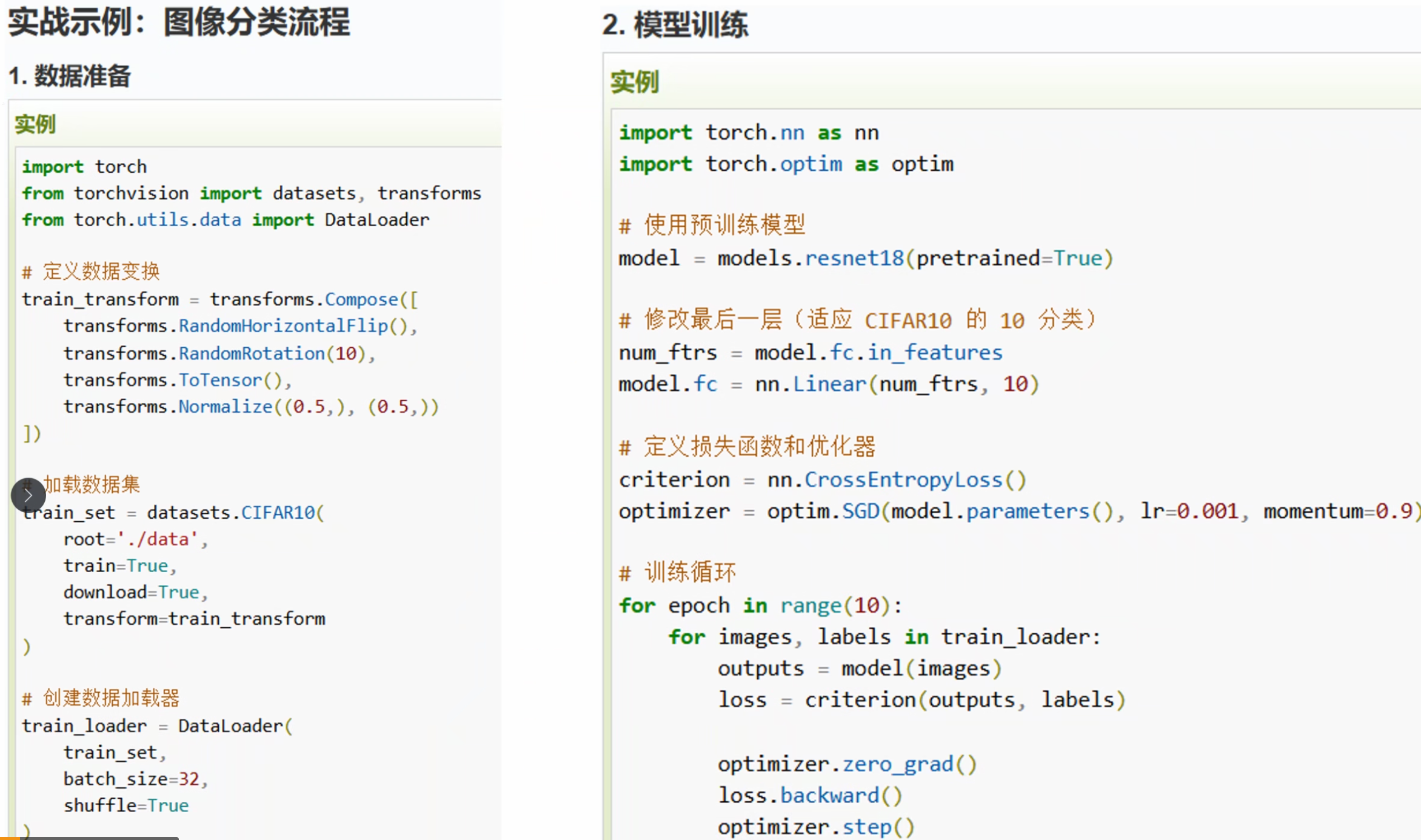
1. 导入必要库
# 本教程演示如何使用 PyTorch 实现 MNIST 手写数字识别任务# 包含数据加载、模型定义、训练和测试import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.utils.data import DataLoader#@ 2. 数据预处理与加载 MNIST 图片为 28x28 灰度图 需要将图片转换为张量并归一化到 [-1, 1] DataLoader 按批次加载数据,并支持 shuffle 功能
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)3. 定义前馈神经网络
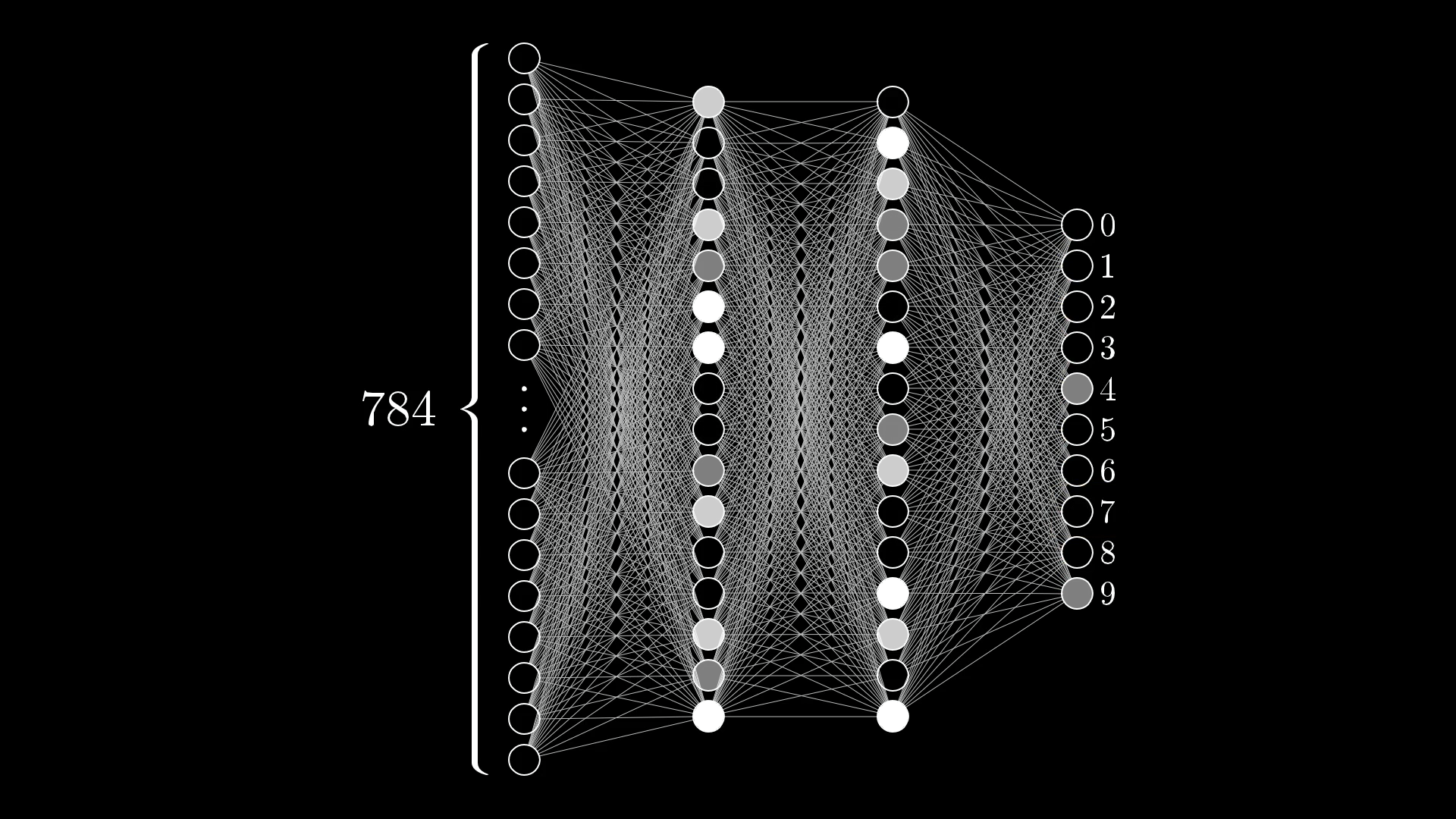
网络结构: 输入层: 28*28 = 784 个神经元 隐藏层: 128 个神经元, ReLU 激活 输出层: 10 个神经元, Softmax 输出概率
class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() self.fc1 = nn.Linear(28*28, 128) self.relu = nn.ReLU() self.fc2 = nn.Linear(128, 10) self.softmax = nn.Softmax(dim=1)
def forward(self, x): # 前向传播 x = x.view(-1, 28*28) # 展平 x = self.fc1(x) x = self.relu(x) x = self.fc2(x) x = self.softmax(x) return x
model = SimpleNN()4. 定义损失函数和优化器
多分类交叉熵损失 优化器: 随机梯度下降 (SGD)
criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01)5. 模型训练
训练流程:
1. 前向传播: 计算预测输出
2. 计算损失
3. 反向传播
4. 参数更新
num_epochs = 5for epoch in range(num_epochs): running_loss = 0.0 for images, labels in train_loader: outputs = model(images) loss = criterion(outputs, labels)
optimizer.zero_grad() loss.backward() optimizer.step()
running_loss += loss.item() print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}")6. 测试模型准确率
在测试集上评估模型性能
correct = 0total = 0with torch.no_grad(): for images, labels in test_loader: outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item()
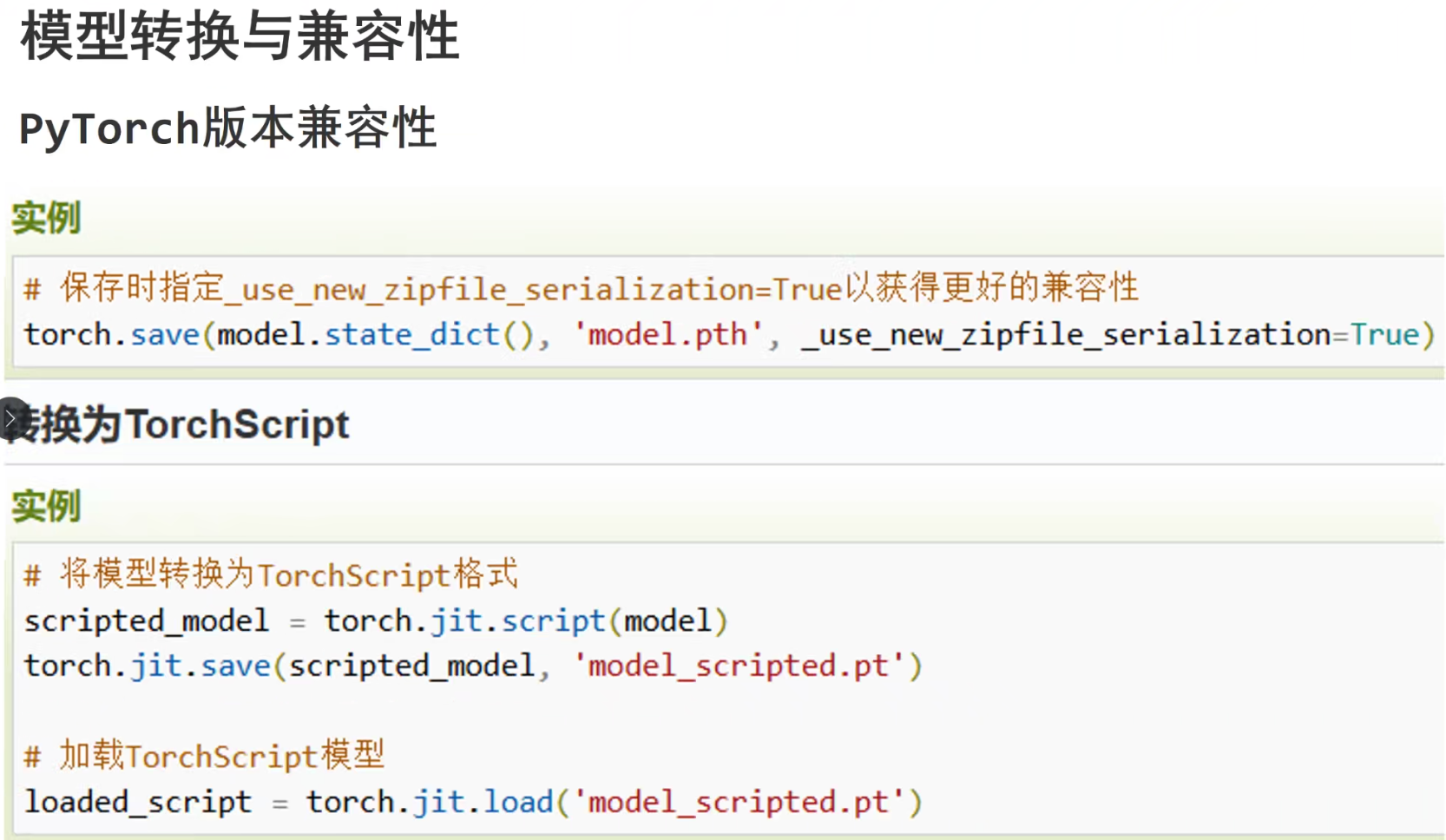
print(f'Test Accuracy: {100 * correct / total:.2f}%')模型保存和加载


优点:保存了模型的完整结构
缺点:模型文件体积大



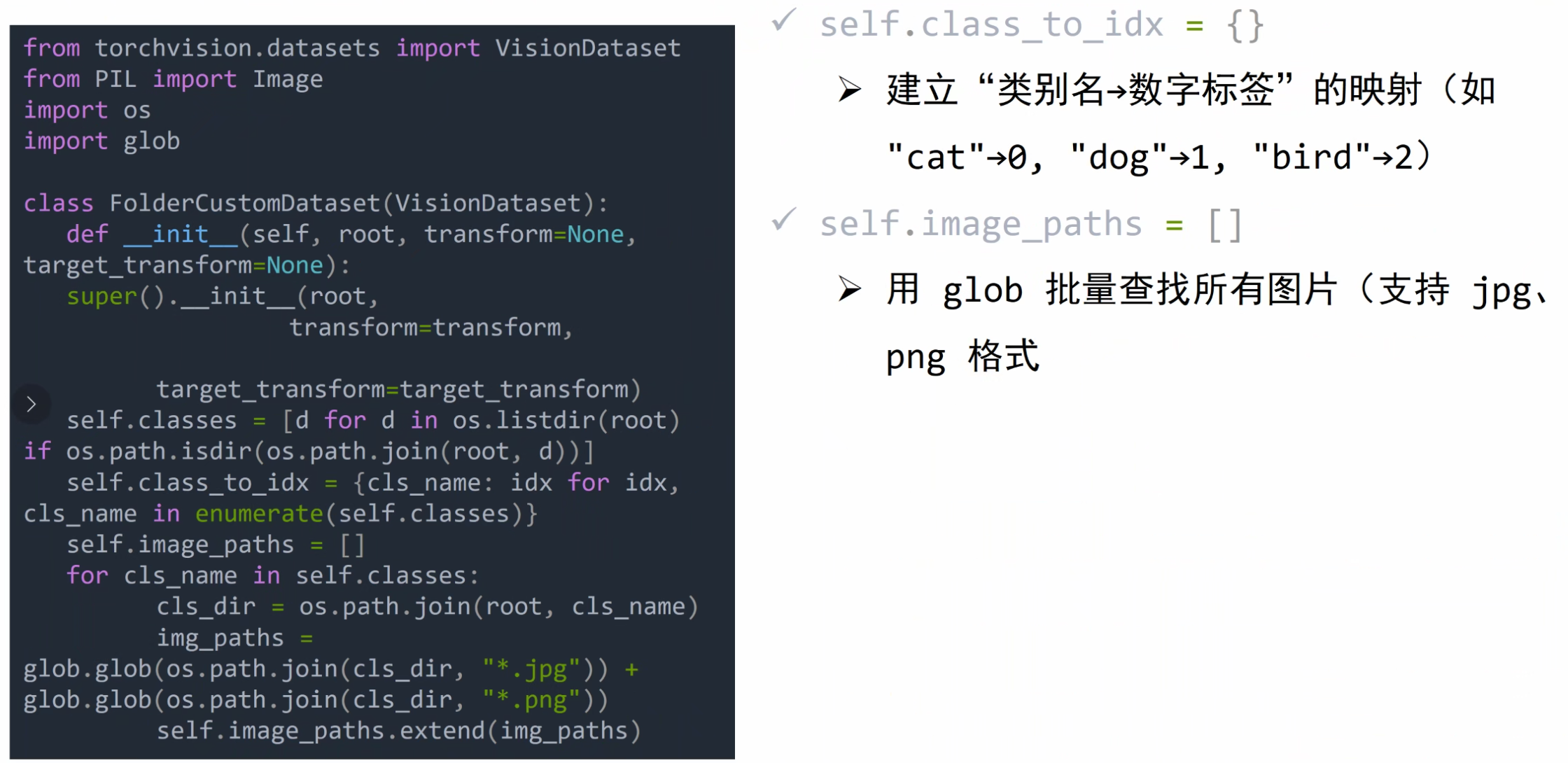
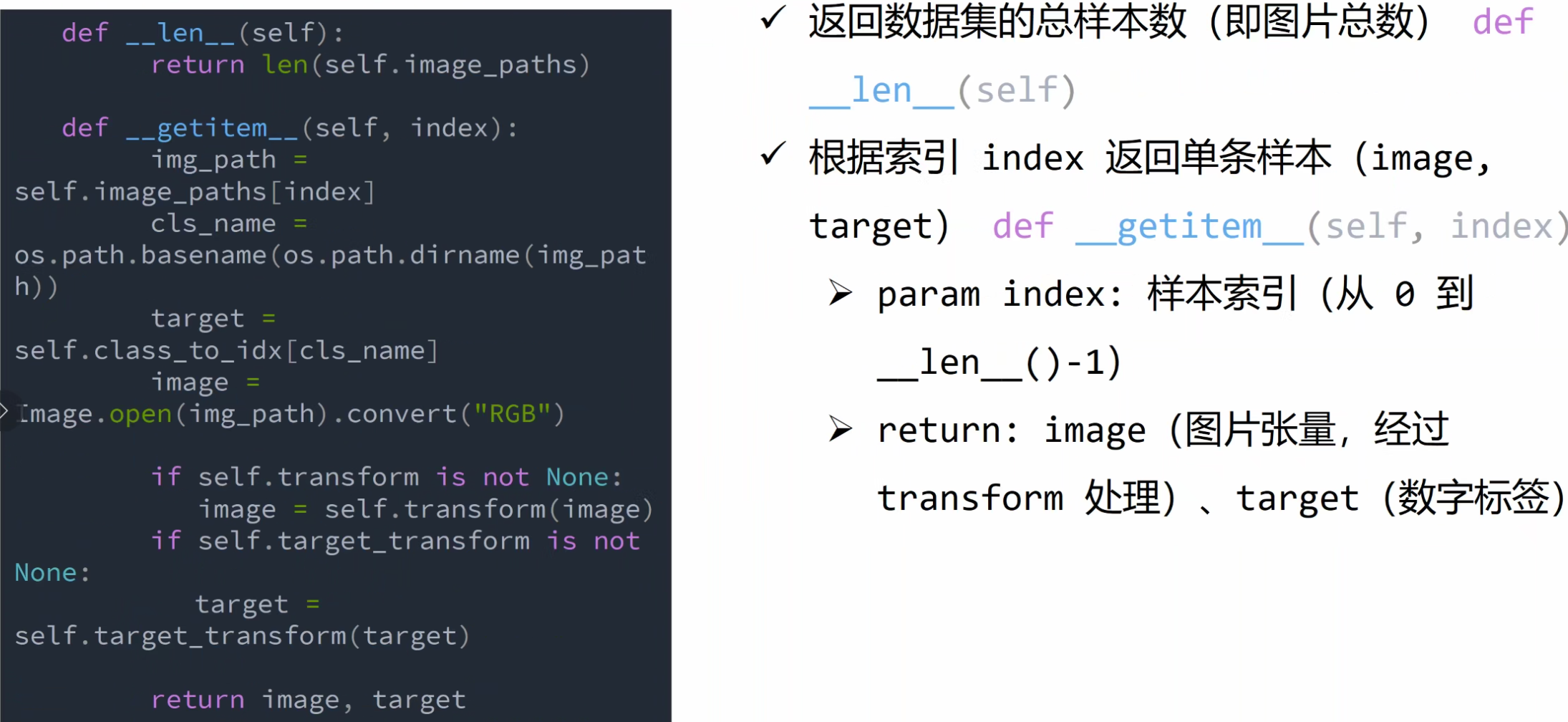
计算机视觉模块
torchvision — Torchvision 0.23 文档 - PyTorch 文档

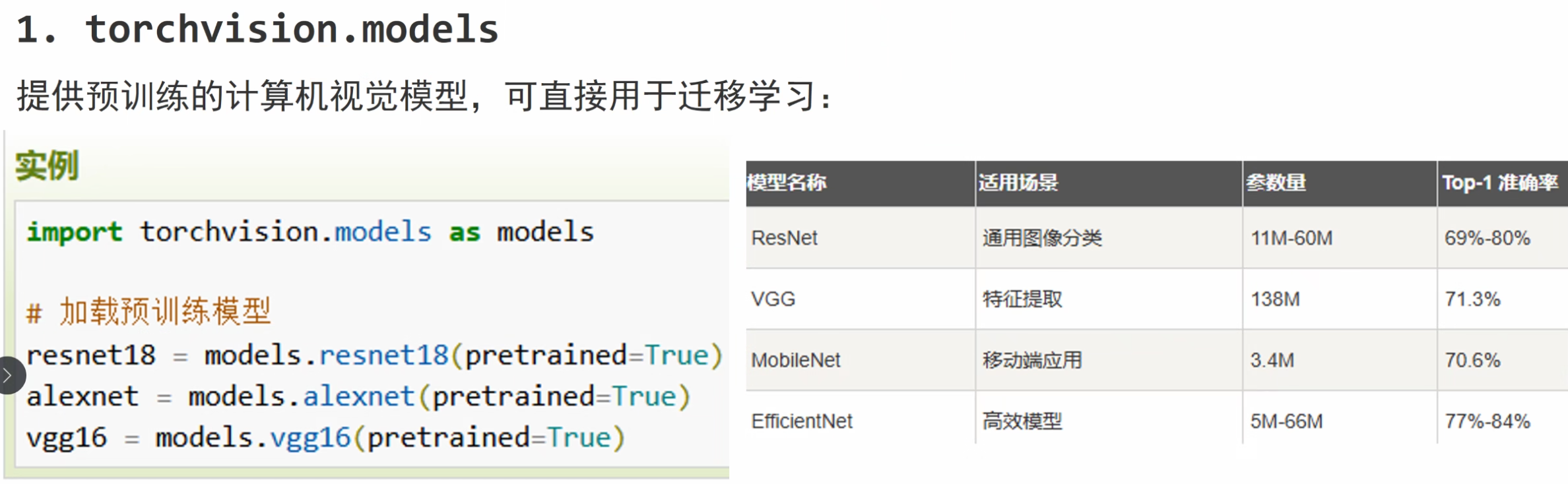


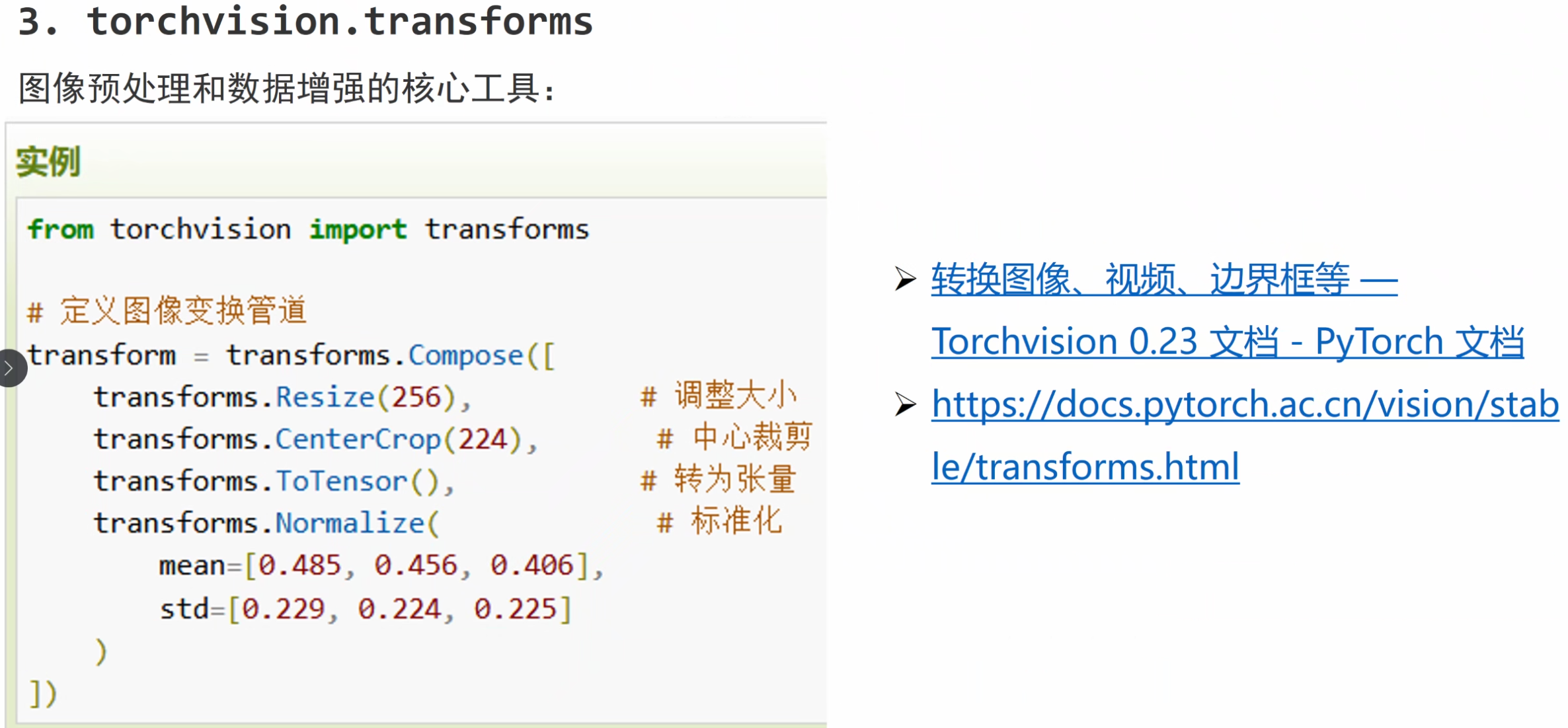
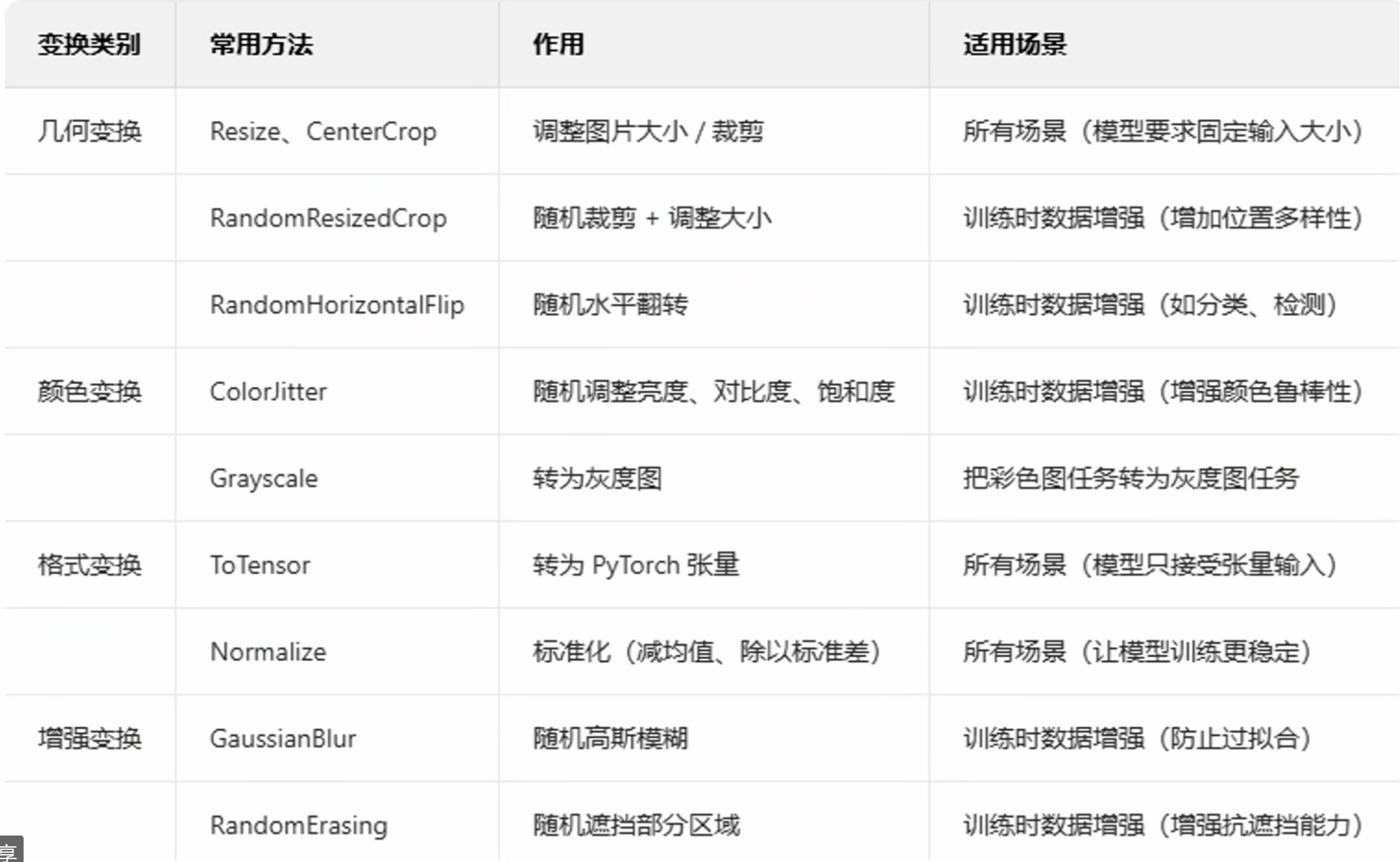
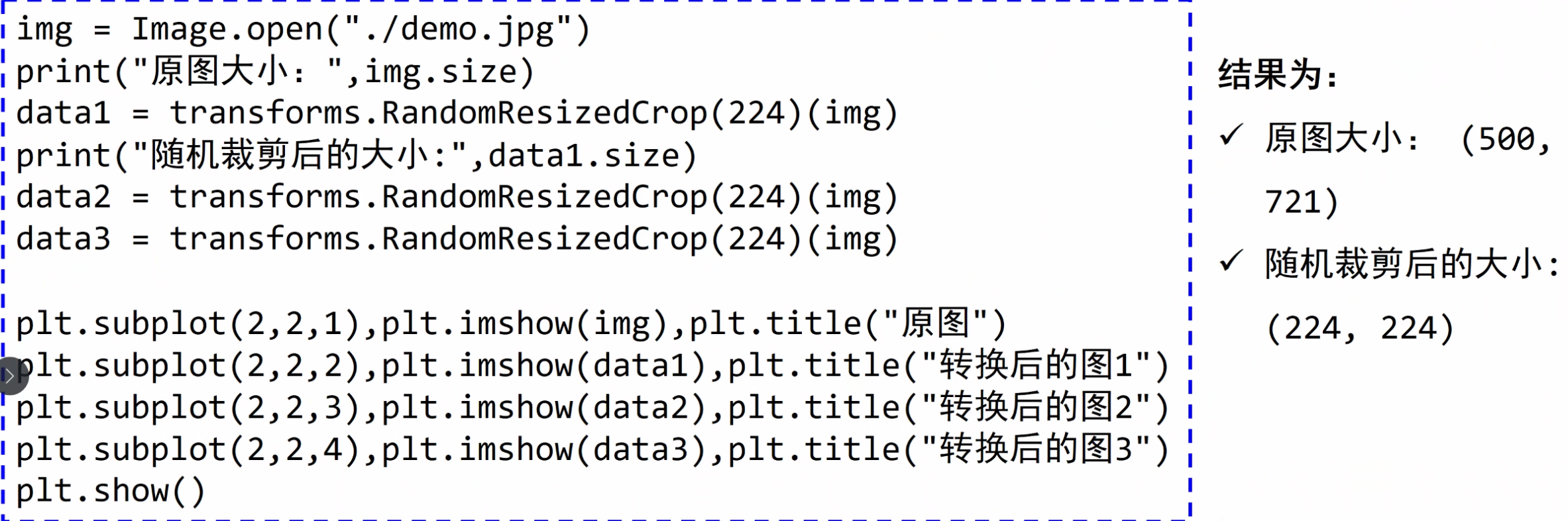
转换图像、视频、边界框等 — Torchvision 0.23 文档 - PyTorch 文档






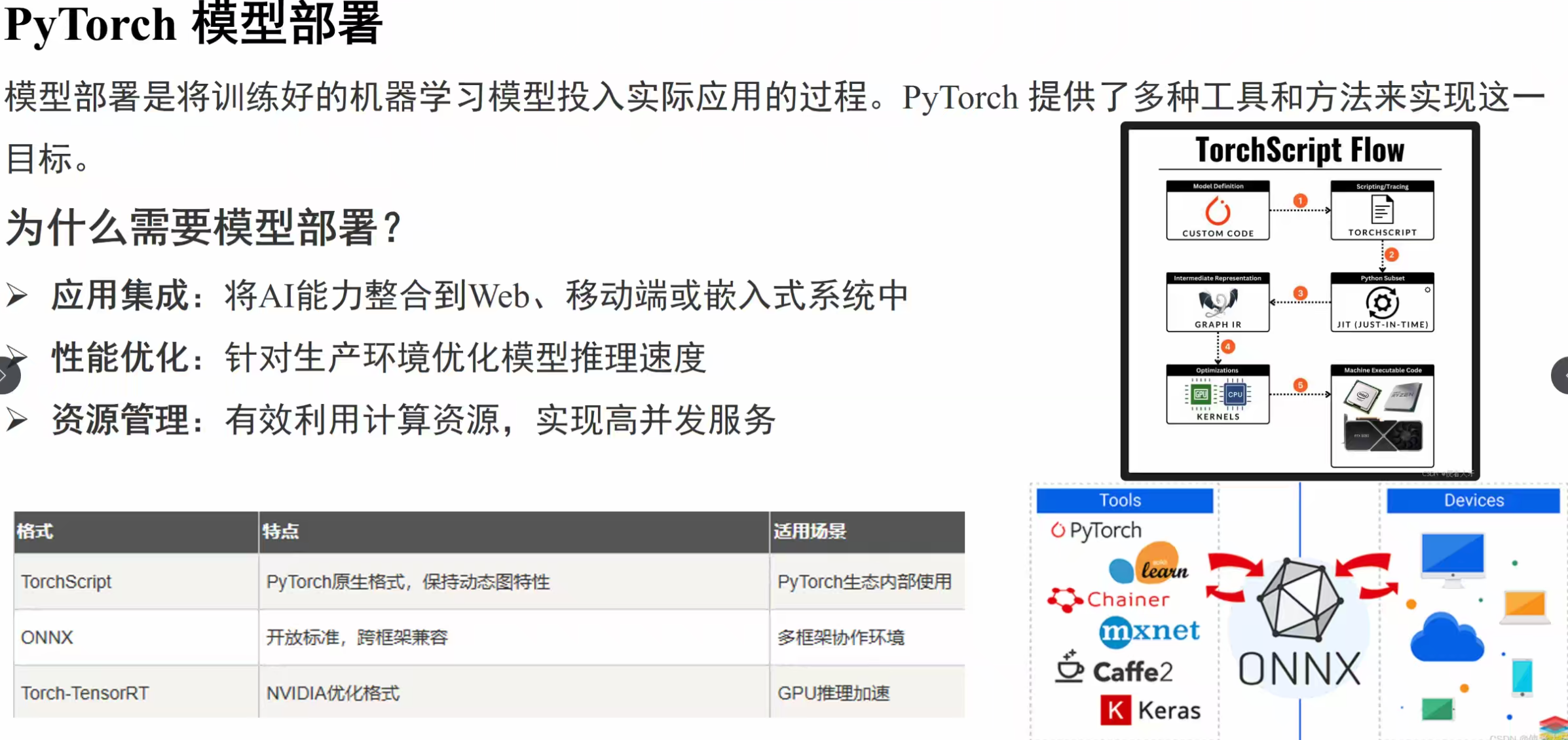
模型部署



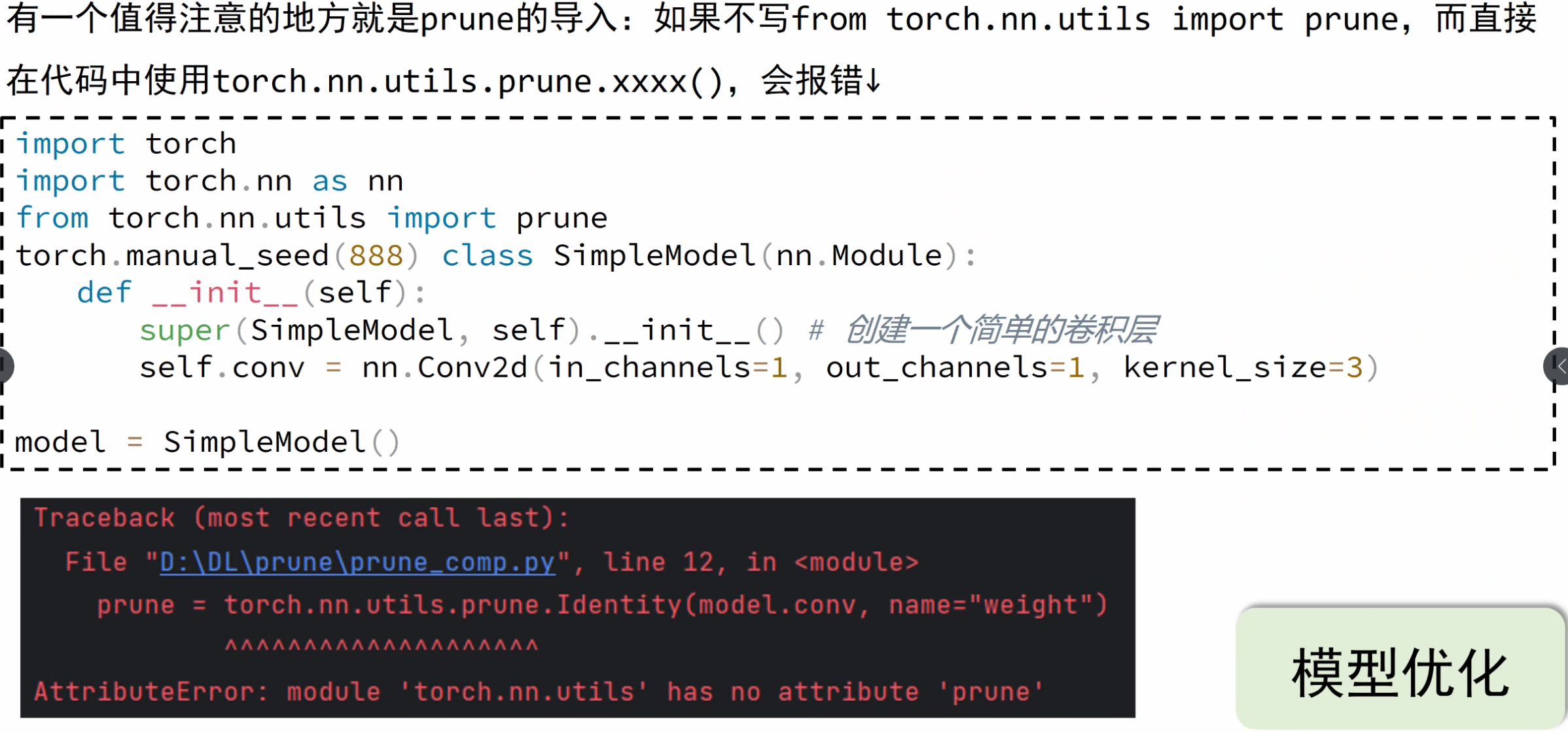



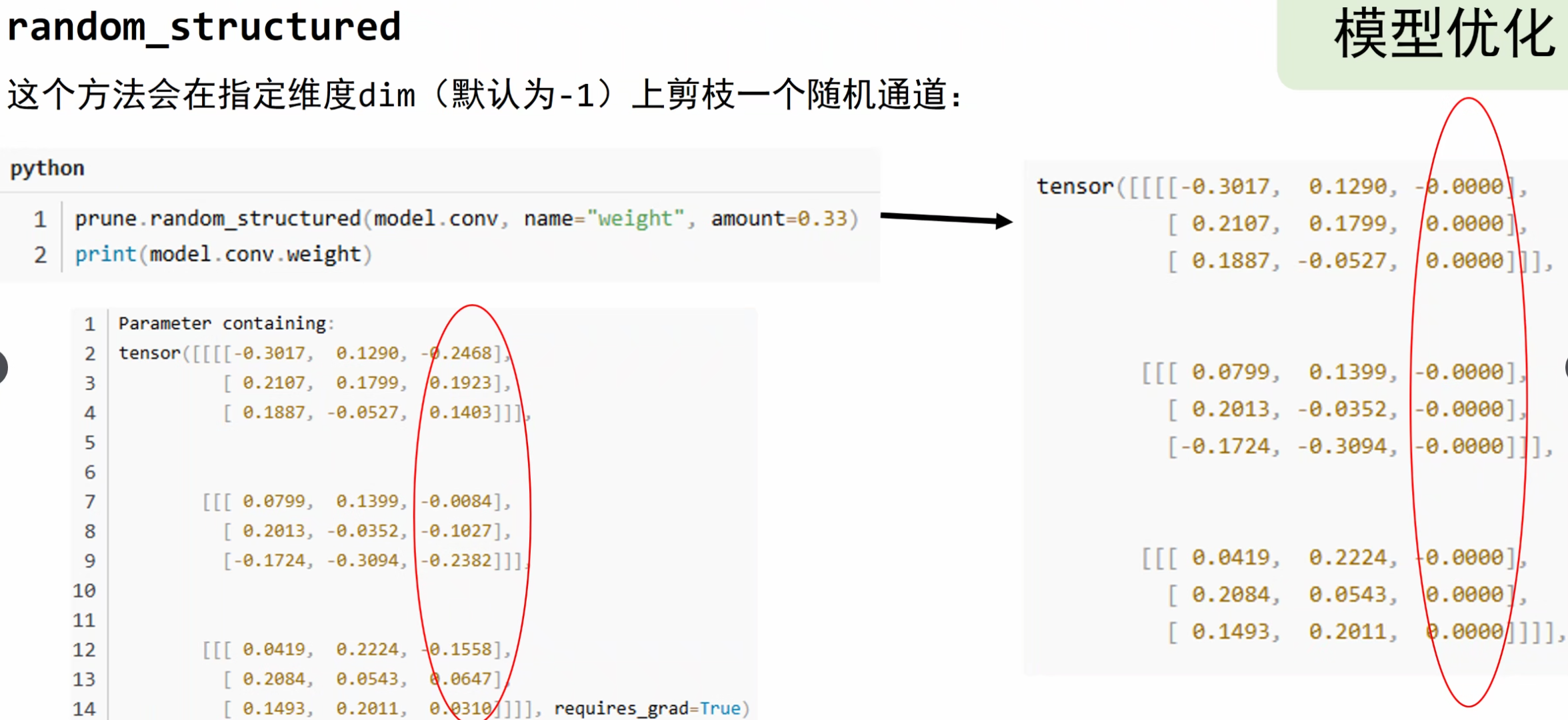
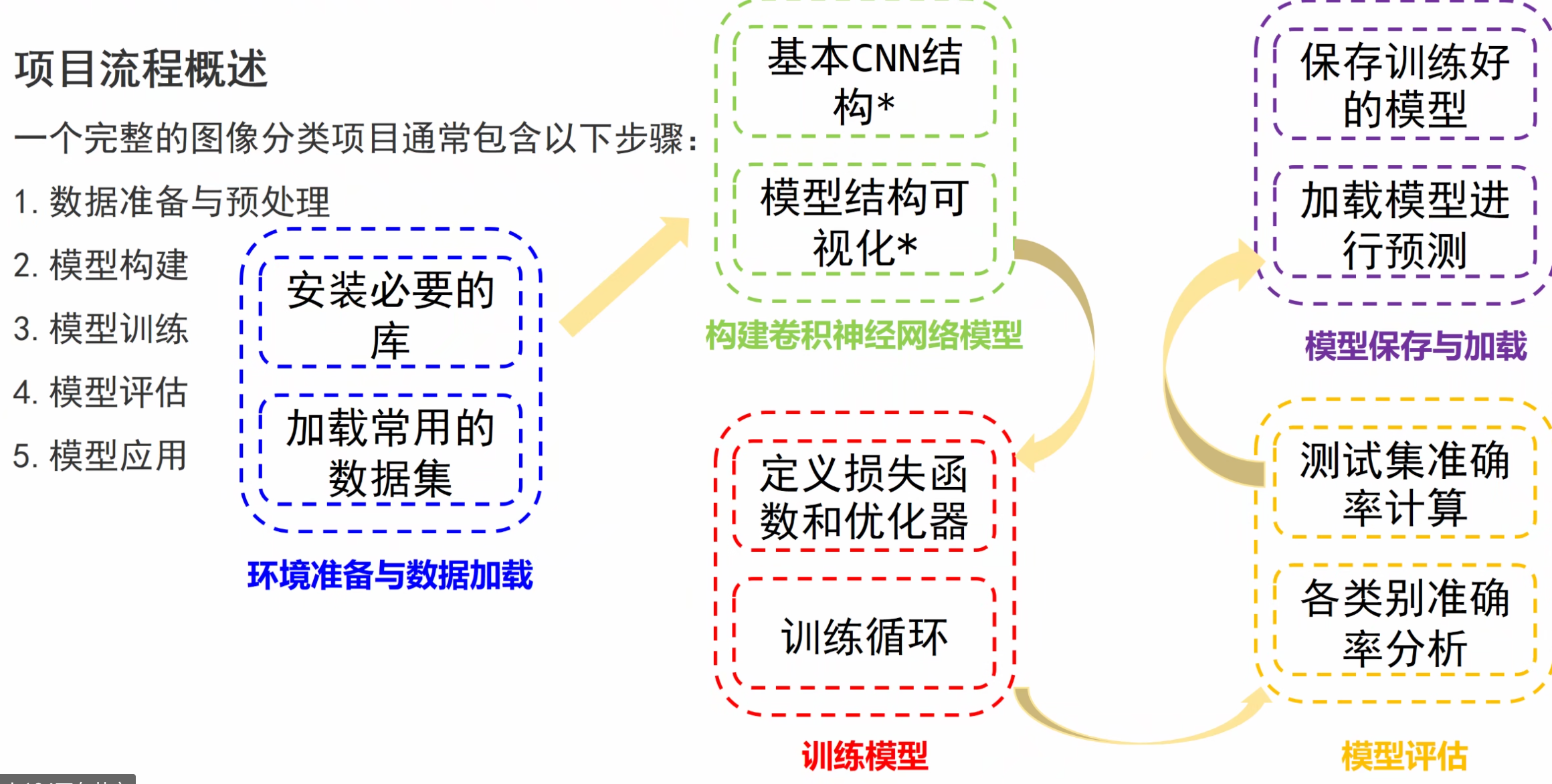
图像分类略讲

文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!