

【论文阅读 | TPAMI 2025 | RWKVFusion:利用统一语言与掩码引导的高效图像融合网络】
[TOC]
01 论文信息
- 论文题目: An Efficient Image Fusion Network Exploiting Unifying Language and Mask Guidance
- 论文作者: Zi-Han Cao, Yu-Jie Liang, Liang-Jian Deng, Gemine Vivone
- 发表单位:
- School of Mathematical Sciences, University of Electronic Science and Technology of China (UESTC), Chengdu, China
- Multi-Hazard Early Warning Key Laboratory of Sichuan Province, UESTC, Chengdu, China
- National Research Council, Institute of Methodologies for Environmental Analysis (CNR-IMAA), Tito, Italy
- National Biodiversity Future Center (NBFC), Palermo, Italy
- 发表会议\期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI, Vol.47, No.11, 2025)
- DOI:
10.1109/TPAMI.2025.3591930 - 论文状态:Received 2025-01-08 · Revised 2025-04-27 · Accepted 2025-07-12 · Published 2025-07-23
- 代码链接: https://github.com/294coder/RWKVFusion
02 论文主要贡献
2.1 关键判断
- 方法层判断: RWKVFusion 的贡献在于把“全局语义文本 + 对象掩码 ”直接写进融合定义 Eq.(5),并通过 MFM 在编码阶段持续注入。语义引导消融实验 Table VII 对此提供正面支持。
- 算子层判断: BRWKV 通过 WKV 的递推化表达 Eq.(12)-Eq.(14),把全局建模代价压到与 token 长度 线性相关;结合 ERF 结果 Fig.10 与算子替换消融 Table VI,在“感受野-复杂度”上找到了相对稳定的折中。
- 实证层判断: 六类融合任务主实验 Table II-V、机制消融实验 Table VI-VIII、下游迁移任务 Fig.11-Fig.13 + Table IX-X 形成闭环证据。说明此方法跨任务能力稳健领先,运行机制可解释,可迁移。
03 论文创新点
- 统一语义引导任务定义:将语言语义 与对象掩码 显式写入融合定义 Eq.(5),并通过 MFM 在编码阶段持续注入,实现“按语义意图融合”。
- 高效全局建模主干:提出 BRWKV + ESS 组合,以递推化 WKV 完成全局关系建模,将计算复杂度降为与 token 长度 线性相关,同时保持跨区域依赖能力。
- 完整可迁移验证:在六类融合任务上给出主实验、机制消融与下游迁移(分割/检测)闭环验证,证明方法效益来自结构协同。
04 方法
4.1 工作定位
本论文提出的工作解决是更具体的结构性矛盾: 如何在不依赖复杂先验(如 GAN、扩散或下游任务头)的前提下,把语义信息显式注入融合过程,同时保证高分辨率场景下的计算可承受性。因此本文提出了 RWKVFusion: 以 RWKV 为高效主干,以语言与语义掩码作为统一引导信号,在六类融合任务上给出主结果、消融和下游任务证据链。

4.1.1 传统融合定义与瓶颈
4.1.1.1 传统定义表达与语义缺口
经典图像融合任务可写为:
式(1)可以表达多模态输入到融合输出的映射关系,但没有给出“应优先保留哪些语义目标”的显式约束。结果是,网络通常只能依靠统计相关性去学习“哪里重要”,在低照、遮挡、烟雾与多目标等复杂场景下,容易出现目标弱化、边界漂移与结构失衡等问题。

4.1.2 既有融合框架的三类问题

从文中的视角看,既有方法主要面临三类现实问题:
- 语义信息注入依赖额外任务头,例如分割/检测联训,会带来标注成本与训练开销;
- 复杂先验链路带来系统复杂化,例如 GAN 双网络、扩散推理过程与深先验迭代;
- 高分辨率条件下算子代价偏高,传统注意力在 token 维度上存在二次梯度爆炸。
4.2 从注意力到 RWKV 理论过渡与计算动机
为了说明为何选择 RWKV 而不是直接继续改造 Transformer,文中先回到标准注意力形式:
按 token 写作:
进一步引入位置相关权重 后,得到可递推改写的形式:
文中先把注意力重写成更接近递推计算的表达,再引入 RWKV 的衰减记忆机制。这样可以在保留全局依赖建模能力的同时,避免标准自注意力在高分辨率场景中的高代价路径。
4.3 方法总览
RWKVFusion 的关键变化是把语义从“外部后验信息”提升为“前向过程中的条件变量”。文中将任务定义升级为:
其中 是文本语义编码, 是语义掩码。式(5)是全文最重要的任务层变化:网络不仅学习“怎么融合”,还要在训练和推理阶段始终回答“按什么语义意图融合”。


4.3.1 语义分支
语义分支由 Florence、DINO、SAM、T5 模型组成,其目标是构造可被主干使用的文本描述和语义掩膜。具体流程为:先由 Florence 生成 caption 候选,再经 DINO 做开放词汇检测,SAM 产出实例掩码,最后由 T5 编码文本并与 mask merging 后的掩码一起送入融合主干。
4.3.2 融合主干
融合分支以多尺度 BRWKV 为主干,并通过 MFM 在编码阶段执行语义条件注入。编码器负责语义调制和跨尺度表征建立,解码器负责结构恢复和纹理重建。特别的,不在解码端重复注入语义条件,目的是降低重建阶段被高层语义扰动的风险。
该设计可概括为:语义分支负责“提供条件”,融合分支负责“条件化融合”,两者在训练与推理阶段均处于统一前向图中,而非后处理型松耦合架构。
4.3.3 代码对照 主干前向入口与条件注入时序
def _foward_prior(self, inp, modal): # 定义函数 _foward_prior # fusion prior if self.fusion_prior == "max": # 按条件分支 prior = torch.max(inp, modal) # 调用 max 更新 prior if self.feature_prior: # 按条件分支 prior = self.prior_convs(prior) # 调用 prior_convs 更新 prior elif self.fusion_prior == "mean": # 分支判断 self.fusion_prior == "mean" prior = (inp + modal) / 2.0 # 更新变量 prior elif self.fusion_prior == "lr": # 分支判断 self.fusion_prior == "lr" prior = inp # 更新变量 prior if self.feature_prior: # 按条件分支 self.feature_prior prior = self.prior_convs(prior) # 调用 prior_convs 更新 prior elif self.fusion_prior.startswith("grad"): # 分支判断 self.fusion_prior.startswith("grad") inp_grad = sobel_op(inp, normalized=True) # 调用 sobel_op 更新 inp_grad modal_grad = sobel_op(modal, normalized=True) # 调用 sobel_op 更新 modal_grad prior = inp_grad.maximum(modal_grad) # 调用 maximum 更新 prior elif self.fusion_prior == "none": # 分支判断 self.fusion_prior == "none" prior = 0.0 # 更新变量 prior else: # 进入兜底分支 raise ValueError(f"Invalid fusion_prior: {self.fusion_prior}") # 执行 ValueError 调用
# if self.feature_prior: # prior = self.prior_convs(prior)
return prior # 返回 prior def _forward_recon(self, feature_out, prior, patch_embd_x=None): # 定义函数 _forward_recon if self.reconstruction_head == "sr": # 按条件分支 self.reconstruction_head == "sr" feature_out = self.conv_after_body(feature_out) # 调用 conv_after_body 更新 feature_out if self.feature_prior: # 按条件分支 self.feature_prior return self.fusion_head(feature_out + prior) # 返回 self.fusion_head(feature_out +... else: # 进入兜底分支 return self.fusion_head(feature_out) + prior # 返回 self.fusion_head(feature_out) ... elif self.reconstruction_head == "fusion": # 分支判断 self.reconstruction_head == "fusion" assert ( # 执行断言校验 patch_embd_x is not None # 执行当前语句 ), "patch_embd_x should be provided for fusion reconstruction" # 结束上一层表达式 feature_out = self.conv_after_body(feature_out) + patch_embd_x # 调用 conv_after_body 更新 feature_out if self.feature_prior: # 按条件分支 self.feature_prior return self.fusion_head(feature_out + prior) # 返回 self.fusion_head(feature_out +... else: # 进入兜底分支 return self.fusion_head(feature_out) + prior # 返回 self.fusion_head(feature_out) ... else: # 进入兜底分支 raise ValueError(f"Invalid reconstruction_head: {self.reconstruction_head}") # 执行 ValueError 调用 def _forward_implem(self, inp, modal, mask=None, llm_feature=None): # 定义函数 _forward_implem # inp: vi/over/far/SPECT/LRMS # modal: ir/under/near/MRI/PAN
# forward features feature_out, patch_embd_x = self._forward_features( # 调用 _forward_features 更新 feature_out, patch_embd_x inp, modal, mask, llm_feature # 执行当前语句 ) # 结束上一层表达式
# forward prior prior = self._foward_prior(inp, modal) # 调用 _foward_prior 更新 prior
# reconstruction outp = self._forward_recon(feature_out, prior, patch_embd_x) # 调用 _forward_recon 更新 outp
return outp # 返回 outp def _forward_features(self, inp, modal, mask=None, llm_feature=None): # 定义函数 _forward_features bs, _, H, W = inp.shape # 更新变量 bs, _, H, W
cat_x_modal = torch.cat([inp, modal], dim=1) # 调用 cat 更新 cat_x_modal patch_embd_x = self.patch_embd(cat_x_modal) # 调用 patch_embd 更新 patch_embd_x modal = self.modal_in(cat_x_modal) # 调用 modal_in 更新 modal
if self.if_abs_pos: # 按条件分支 self.if_abs_pos x = patch_embd_x + self.resize_pos_embd( # 调用 resize_pos_embd 更新 x self.abs_pos, inp_size=(H, W) # 更新变量 self.abs_pos, inp_size ).expand(bs, patch_embd_x.size(1), -1, -1) # 结束上一层表达式 else: # 进入兜底分支 x = patch_embd_x # 更新变量 x
if llm_feature is not None and self.llm_channel is not None: # 按条件分支 llm_feature is not None and self.llm... llm_feature = F.normalize(llm_feature, p=2, dim=1) # 调用 normalize 更新 llm_feature llm_feature = self.llm_embd(llm_feature) # 调用 llm_embd 更新 llm_feature llm_feature = (llm_feature + self.txt_sine_pe).float() # 调用 float 更新 llm_feature llm_feature = self.embd_drop(llm_feature) # 调用 embd_drop 更新 llm_feature
if mask is not None and hasattr(self, "mask_embd"): # 按条件分支 mask is not None and hasattr(self, "... mask = self.mask_embd(mask) # 调用 mask_embd 更新 mask
# init condition u_cond = ConditionInput(modal, llm_feature, mask) # 调用 ConditionInput 更新 u_cond
## encoder encs = [] # 更新变量 encs for encoder, down in zip(self.encoders, self.downs): # 遍历 encoder, down in zip(self.encoders, self.downs) u_cond.modalities = self.resize_conds( # 调用 resize_conds 更新 u_cond.modalities H, W, u_cond.modalities, resample_type="bilinear" # 更新变量 H, W, u_cond.modalities, res... ) # 结束上一层表达式 u_cond.mask_input = self.resize_conds( # 调用 resize_conds 更新 u_cond.mask_input H, W, u_cond.mask_input, resample_type="nearest" # 更新变量 H, W, u_cond.mask_input, res... ) # 结束上一层表达式 x, u_cond = encoder.enc_forward(x, u_cond, (H, W)) # 调用 enc_forward 更新 x, u_cond encs.append(x) # 执行 append 调用 x = down(x) # 调用 down 更新 x H = H // 2 # 更新变量 H W = W // 2 # 更新变量 W
## middle layer u_cond.modalities = self.resize_conds( # 调用 resize_conds 更新 u_cond.modalities H, W, u_cond.modalities, resample_type="bilinear" # 更新变量 H, W, u_cond.modalities, res... ) # 结束上一层表达式 u_cond.mask_input = self.resize_conds( # 调用 resize_conds 更新 u_cond.mask_input H, W, u_cond.mask_input, resample_type="nearest" # 更新变量 H, W, u_cond.mask_input, res... ) # 结束上一层表达式 x, _ = self.middle_blks.enc_forward(x, u_cond, (H, W)) # 调用 enc_forward 更新 x, _
## decoder for decoder, up, enc_skip, skip_scale in zip( # 遍历 decoder, up, enc_skip, skip_scale in zip( self.decoders, self.ups, encs[::-1], self.skip_scales # 执行当前语句 ): # 结束上一层表达式 x = up(x) # 调用 up 更新 x H = H * 2 # 更新变量 H W = W * 2 # 更新变量 W u_cond.modalities = self.resize_conds( # 调用 resize_conds 更新 u_cond.modalities H, W, u_cond.modalities, resample_type="bilinear" # 更新变量 H, W, u_cond.modalities, res... ) # 结束上一层表达式 u_cond.mask_input = self.resize_conds( # 调用 resize_conds 更新 u_cond.mask_input H, W, u_cond.mask_input, resample_type="nearest" # 更新变量 H, W, u_cond.mask_input, res... ) # 结束上一层表达式 x = torch.cat([x, enc_skip * skip_scale.view(1, -1, 1, 1)], dim=1) # 调用 cat 更新 x x = decoder.dec_forward(x, u_cond, (H, W)) # 调用 dec_forward 更新 x
return x, patch_embd_x # 返回 x, patch_embd_x这段实现表明,“语义引导并非后处理补丁”在工程上由 ConditionInput 的层级传递机制保障,并最终作用于融合特征形成过程。
4.4 融合主干 BRWKV 机制拆解 空间混合、通道混合与递推化
4.4.1 空间混合 Spatial Mixing
在 BRWKV 的空间分支中,输入序列先经线性投影:
随后通过 WKV 进行全局聚合:
最后由门控得到空间输出:
式(7)中的两个参数含义非常关键: 控制通道级空间衰减, 控制当前位置 bonus。其机制本质为“位置衰减记忆 + 当前 token 增益”。与显式输出 attention map 的标准注意力不同,WKV 可视为先将历史 token 压缩到递推状态,再执行状态读取。
4.4.2 通道混合 Channel Mixing
空间输出先做归一化:
再做通道域投影与非线性:
门控后得到通道输出:
这一段可以理解为“先在空间域做全局关系聚合,再在通道域做非线性重标定”。它对应 Transformer 块中 attention + FFN 的角色分工,但实现路径和复杂度结构不同。
4.4.3 递推化改写与复杂度来源
文中将式(7)进一步改写为隐藏状态递推形式。定义:
对应地:
WKV 的 FLOPs 记为:
式(14)对应文中关于效率的论据:开销与 token 长度 线性相关,而不是标准注意力常见的二次关系。对图像融合这类高分辨率、像素级任务,该差异是能否落地部署的关键。
4.4.4 BRWKV 的机制优势
仅以“线性复杂度”概括 BRWKV 并不充分。更关键的是,RWKV 在保持全局交互能力时,将“显式两两相关矩阵”替换为“可递推的衰减记忆状态”,从而把全局建模与状态压缩放在同一步中完成。这意味着:
- 该机制是对信息组织方式的重构;
- 对低层视觉任务,递推状态可减少高分辨率输入下的显存突增;
- 与仅依赖局部窗口的方案相比,它在跨区域结构一致性上更具理论优势。
因此,RWKVFusion 的效率收益与结构收益是耦合产生的:前者来自递推化,后者来自全局关系保留,而非二者择一。
4.4.5 代码对照 BRWKV 的空间混合与通道混合
文中在式(6)-式(14)给出数学形式,仓库中对应实现主要落在 DoubleStreamRWKVBlock.BRWKV_img_forward 与 VRWKV_SpatialMix_wkv5.forward 两处。
def BRWKV_img_forward( # 定义函数 BRWKV_img_forward self, # 执行当前语句 x: torch.Tensor, # 执行当前语句 MIMF_modals: torch.Tensor = None, # 更新变量 MIMF_modals: torch.Tensor MIFM_mm: torch.Tensor = None, # 更新变量 MIFM_mm: torch.Tensor llm_feat: torch.Tensor = None, # 更新变量 llm_feat: torch.Tensor patch_resolution=None, # 更新变量 patch_resolution ): # 结束上一层表达式 """ # 文档字符串边界 ##! 1. Image-only attention with clipping windows w_img = window_partition(img, window_size) # 调用 window_partition 更新 w_img w_img = scan(img) # 调用 scan 更新 w_img w_img = only_img_attention(img) # 调用 only_img_attention 更新 w_img
##! 2. Multi-modal attention with txt feature # solution 1 (downsample image) img = window_reverse(w_img, window_size, H, W) # 调用 window_reverse 更新 img ds_img = downsample_scanned_img(img) # 调用 downsample_scanned_img 更新 ds_img ds_img, txt = multi_modal_attention(ds_img, txt) # 调用 multi_modal_attention 更新 ds_img, txt upsample_img = upsample_scanned_img(ds_img) # 调用 upsample_scanned_img 更新 upsample_img img = (upsample_img + img) / 2 # 更新变量 img
# solution 2 (repeat txt feature on bs-dim) rep_bs_txt = repeat(txt, 'bs d l -> (bs n_winds) d l') # 调用 repeat 更新 rep_bs_txt w_img, rep_bs_txt = multi_modal_attention(w_img, rep_bs_txt) # 调用 multi_modal_attention 更新 w_img, rep_bs_txt img = window_reverse(w_img, window_size, H, W) # 调用 window_reverse 更新 img txt = rearrange(rep_bs_txt, '(bs n_winds) d l -> bs n_winds d l', bs=B) # 调用 rearrange 更新 txt txt = txt.mean(dim=1) # 调用 mean 更新 txt
##! 3. Multi-modal FFN #! Flux.1 says we should have two FFNs, one for image and one for txt img = FFN(img, txt) # 调用 FFN 更新 img
""" # 文档字符串边界
B, C, H, W = x.shape # 更新变量 B, C, H, W # has_llm = (llm_feat is not None) and self.has_llm
# pre-fusion previous (non-downsampled) image and MIFM image # x = x + MIFM_img
# ver 3 # MIFM_mm = MIFM_mm * self.lerp_factor.view(1, -1, 1, 1) # x = self.mm_proj_in(torch.cat([x, MIFM_mm], dim=1)) x = self.mm_proj_in( # 调用 mm_proj_in 更新 x torch.cat( # 执行 cat 调用 [x, MIFM_mm * self.lerp_factor.view(1, -1, 1, 1), MIMF_modals], dim=1 # 更新变量 [x, MIFM_mm * self.lerp_fact... ) # 结束上一层表达式 ) # 结束上一层表达式
# we perform scanning first and then window partition # different from v11 where we perform window partition first
# window partition # (bs, c, h * w) -> (bs x n_winds, c, window_size, window_size) h, w, x = self.partition_img_by_window(H, W, x) # 调用 partition_img_by_window 更新 h, w, x
# ESS x = ( # 更新变量 x self.scan(x).view(x.size(0) * self.K, -1, h * w).transpose(1, 2) # 执行 scan 调用 ) # [b*k, l, c]
######################## Image-only Attention ##########################
# Image spatial mixing x = self.only_img_attn_ln(x) # 调用 only_img_attn_ln 更新 x sc1, sh1, ga1 = self.modulator1(x) # 调用 modulator1 更新 sc1, sh1, ga1 prenorm_x = (1 + sc1) * x + sh1 # modulated img x_attn = self.drop_path(self.att_img(prenorm_x, None, (h, w))) # 调用 drop_path 更新 x_attn x = ga1 * x_attn + x # 更新变量 x
# merge ESS # (bs, c * K, H * W) -> (bs, c, H, W) x = rearrange(x, "(b k) (h w) d -> b k d h w", k=self.K, h=h, w=w) # 调用 rearrange 更新 x x = self.merge(x) / self.K # 调用 merge 更新 x
# window reverse # (bs x n_winds, c, wind x wind) -> (bs, c, h x w) x = self.reverse_img_by_window(H, W, x) # 调用 reverse_img_by_window 更新 x x = x.view(B, C, H * W).transpose(1, 2) # 调用 view 更新 x
########################################################################
######################## Image-modality FFN ############################
# Channel mixing x = self.fusion_img_llm_ln(x) # 调用 fusion_img_llm_ln 更新 x sc2, sh2, ga2 = self.modulator2(x) # 调用 modulator2 更新 sc2, sh2, ga2 prenorm_x = (1 + sc2) * x + sh2 # 更新变量 prenorm_x
# 2. pure image FFN x_ffn = self.drop_path(self.ffn_fusion(prenorm_x, None, (H, W))) # 调用 drop_path 更新 x_ffn x = ga2 * x_ffn + x # 更新变量 x
x = x.transpose(1, 2).view(B, C, H, W) # 调用 transpose 更新 x
#########################################################################
# txt reduced channel if (not self.last_enc_block) and self.has_llm and llm_feat is not None: # 按条件分支 (not self.last_enc_block) and self.h... llm_feat = self.txt_chan_reduce(llm_feat) # 调用 txt_chan_reduce 更新 llm_feat
return x, llm_feat # 返回 x, llm_feat def forward( # 定义函数 forward self, # 执行当前语句 x, # 执行当前语句 txt=None, # 更新变量 txt patch_resolution=None, # 更新变量 patch_resolution mm_tokens: "tuple[torch.Tensor] | None" = None, # 更新变量 mm_tokens: "tuple[torch.Tens... ): # 结束上一层表达式 def _inner_forward(x, txt, patch_resolution, mm_tokens): # 定义函数 _inner_forward B, T, C = x.size() # 调用 size 更新 B, T, C # sr, k, v, T = self.jit_func(x, txt, patch_resolution, mm_tokens) r, k, v, g, T = self.jit_func(x, txt, patch_resolution, mm_tokens) # 调用 jit_func 更新 r, k, v, g, T # x = RUN_CUDA_RWKV5(B, T, C, self.spatial_decay / T, self.spatial_first / T, k, v) x = RUN_CUDA_RWKV5_2( # 调用 RUN_CUDA_RWKV5_2 更新 x B, T, C, self.n_head, r, k, v, w=self.time_decay, u=self.time_faaaa # 更新变量 B, T, C, self.n_head, r, k, ... ) # 结束上一层表达式 # print(f'Spatial mix - x max: {x.abs().max()}, x norm: {x.norm()}') x = self.key_norm(x) # 调用 key_norm 更新 x # x = sr * x # x = self.output(x) x = self.jit_func_2(x, g) # 调用 jit_func_2 更新 x
return x # 返回 x
if self.with_cp and x.requires_grad: # 按条件分支 self.with_cp and x.requires_grad x = cp.checkpoint( # 调用 checkpoint 更新 x _inner_forward, x, txt, patch_resolution, mm_tokens, use_reentrant=False # 更新变量 _inner_forward, x, txt, patc... ) # 结束上一层表达式 else: # 进入兜底分支 x = _inner_forward(x, txt, patch_resolution, mm_tokens) # 调用 _inner_forward 更新 x return x # 返回 xatt_img 对应式(6)-式(14)的空间混合,ffn_fusion 对应式(9)-式(11)的通道混合。
4.5 ESS 把二维图像转成可递推序列
BRWKV 原生更接近序列建模,因此文中引入 ESS,即 Efficient Scanning Strategy,实现二维到一维的桥接。其扫描配置包括:
- 横/纵交替 + 翻转,2 scans;
- 横纵全量 + 翻转,4 scans;
- 在 4 scans 基础上加入对角扫描,8 scans。
ESS 的目标并非提升扫描方向数量本身,而是在空间覆盖率与 FLOPs 之间取得平衡。后续消融表 VI 显示,8 scans 在部分指标可略增,但代价上升明显;默认策略在综合性能与效率之间更平衡。
4.5.1 代码对照 CrossScan / CrossMerge 的多方向扫描
代码实现中,ESS 的核心不在高层 scan_mode 字符串,而在 CrossScan 与 CrossMerge 的真实张量重排逻辑。
class CrossScan(torch.autograd.Function): # 定义类 CrossScan # ZSJ 这里是把图像按照特定方向展平的地方,改变扫描方向可以在这里修改 @staticmethod # 装饰器声明 def forward(ctx, x: torch.Tensor): # 定义函数 forward B, C, H, W = x.shape # 更新变量 B, C, H, W ctx.shape = (B, C, H, W) # 更新变量 ctx.shape # xs = x.new_empty((B, 4, C, H * W)) xs = x.new_empty((B, 8, C, H * W)) # 调用 new_empty 更新 xs # 添加横向和竖向的扫描 xs[:, 0] = x.flatten(2, 3) # 调用 flatten 更新 xs[:, 0] xs[:, 1] = x.transpose(dim0=2, dim1=3).flatten(2, 3) # 调用 transpose 更新 xs[:, 1] xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1]) # 调用 flip 更新 xs[:, 2:4]
# 提供斜向和反斜向的扫描 xs[:, 4] = diagonal_gather(x) # 调用 diagonal_gather 更新 xs[:, 4] xs[:, 5] = antidiagonal_gather(x) # 调用 antidiagonal_gather 更新 xs[:, 5] xs[:, 6:8] = torch.flip(xs[:, 4:6], dims=[-1]) # 调用 flip 更新 xs[:, 6:8]
return xs # 返回 xs
@staticmethod # 装饰器声明 def backward(ctx, ys: torch.Tensor): # 定义函数 backward # out: (b, k, d, l) B, C, H, W = ctx.shape # 更新变量 B, C, H, W L = H * W # 更新变量 L # 把横向和竖向的反向部分再反向回来,并和原来的横向和竖向相加 # ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L) y_rb = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L) # 调用 flip 更新 y_rb # 把竖向的部分转成横向,然后再相加,再转回最初是的矩阵形式 # y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L) y_rb = y_rb[:, 0] + y_rb[:, 1].view(B, -1, W, H).transpose( # 调用 view 更新 y_rb dim0=2, dim1=3 # 更新变量 dim0 ).contiguous().view(B, -1, L) # 结束上一层表达式 y_rb = y_rb.view(B, -1, H, W) # 调用 view 更新 y_rb
# 把斜向和反斜向的反向部分再反向回来,并和原来的斜向和反斜向相加 y_da = ys[:, 4:6] + ys[:, 6:8].flip(dims=[-1]).view(B, 2, -1, L) # 调用 flip 更新 y_da # 把斜向和反斜向的部分都转成原来的最初的矩阵形式,再相加 y_da = diagonal_scatter(y_da[:, 0], (B, C, H, W)) + antidiagonal_scatter( # 调用 diagonal_scatter 更新 y_da y_da[:, 1], (B, C, H, W) # 执行当前语句 ) # 结束上一层表达式
y_res = y_rb + y_da # 更新变量 y_res # return y.view(B, -1, H, W) return y_res # 返回 y_resclass CrossMerge(torch.autograd.Function): # 定义类 CrossMerge @staticmethod # 装饰器声明 def forward(ctx, ys: torch.Tensor): # 定义函数 forward B, K, D, H, W = ys.shape # 更新变量 B, K, D, H, W ctx.shape = (H, W) # 更新变量 ctx.shape ys = ys.view(B, K, D, -1) # 调用 view 更新 ys # ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, D, -1) # y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, D, -1)
y_rb = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, D, -1) # 调用 flip 更新 y_rb # 把竖向的部分转成横向,然后再相加,再转回最初是的矩阵形式 y_rb = y_rb[:, 0] + y_rb[:, 1].view(B, -1, W, H).transpose( # 调用 view 更新 y_rb dim0=2, dim1=3 # 更新变量 dim0 ).contiguous().view(B, D, -1) # 结束上一层表达式 y_rb = y_rb.view(B, -1, H, W) # 调用 view 更新 y_rb
# 把斜向和反斜向的反向部分再反向回来,并和原来的斜向和反斜向相加 y_da = ys[:, 4:6] + ys[:, 6:8].flip(dims=[-1]).view(B, 2, D, -1) # 调用 flip 更新 y_da # 把斜向和反斜向的部分都转成原来的最初的矩阵形式,再相加 y_da = diagonal_scatter(y_da[:, 0], (B, D, H, W)) + antidiagonal_scatter( # 调用 diagonal_scatter 更新 y_da y_da[:, 1], (B, D, H, W) # 执行当前语句 ) # 结束上一层表达式
y_res = y_rb + y_da # 更新变量 y_res return y_res.view(B, D, -1) # 返回 y_res.view(B, D, -1) # return y
@staticmethod # 装饰器声明 def backward(ctx, x: torch.Tensor): # 定义函数 backward # B, D, L = x.shape # out: (b, k, d, l) H, W = ctx.shape # 更新变量 H, W B, C, L = x.shape # 更新变量 B, C, L # xs = x.new_empty((B, 4, C, L)) xs = x.new_empty((B, 8, C, L)) # 调用 new_empty 更新 xs
# 横向和竖向扫描 xs[:, 0] = x # 更新变量 xs[:, 0] xs[:, 1] = x.view(B, C, H, W).transpose(dim0=2, dim1=3).flatten(2, 3) # 调用 view 更新 xs[:, 1] xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1]) # 调用 flip 更新 xs[:, 2:4] # xs = xs.view(B, 4, C, H, W)
# 提供斜向和反斜向的扫描 xs[:, 4] = diagonal_gather(x.view(B, C, H, W)) # 调用 diagonal_gather 更新 xs[:, 4] xs[:, 5] = antidiagonal_gather(x.view(B, C, H, W)) # 调用 antidiagonal_gather 更新 xs[:, 5] xs[:, 6:8] = torch.flip(xs[:, 4:6], dims=[-1]) # 调用 flip 更新 xs[:, 6:8]
# return xs return xs.view(B, 8, C, H, W) # 返回 xs.view(B, 8, C, H, W)
############### K = 4 ################由此可见,“2/4/8 scans”是可追踪的扫描方向组合与逆向重排过程。
4.6 MFM 语言、掩码与模态特征的三路径融合

MFM,即 Multi-Modal Fusion Module,是语义分支与融合主干的接口层。其设计并非简单拼接层,而是由原始模态补偿、掩码引导与文本调制构成的三路径机制。
首先,原始模态与上一层特征通过门控形成主路径:
随后注入掩码:
合并图像特征:
并通过奇偶层交替拼接文本:
式(18)中的交替拼接并非形式性操作,其目的在于避免文本长期位于固定序列端点造成的信息偏置。文中后续的模块替换消融中,MLP/cross-attention 对照显示 MFM 默认设计优于替代结构,说明三路径耦合提供了可测收益。
4.6.1 代码对照 MFM 的门控、掩码注入与文本交互
下面给出对应式(15)-式(18)的逐行注释代码切块。
def forward(self, img_feat: torch.Tensor, cond_input: ConditionInput): # 定义函数 forward modals = cond_input.modalities # 更新变量 modals mask = cond_input.mask_input # 更新变量 mask llm_feat = cond_input.llm_feature # 更新变量 llm_feat
# modalities encoder modals = self.modal_convs(modals) # 调用 modal_convs 更新 modals modals = self.modal_norm(modals) # 调用 modal_norm 更新 modals
# feature encoder img_feat = self.feat_drop(self.feat_convs(img_feat)) # 调用 feat_drop 更新 img_feat
# feature gate img_gate = self.feat_norm(img_feat + modals) # 调用 feat_norm 更新 img_gate feat_pool = self.adap_pool(img_gate) # 调用 adap_pool 更新 feat_pool feat_mul = self.act_conv(feat_pool) # to gate # m1, m2 = feat_mul.chunk(2, dim=1)
# gate img_feat_gate = img_feat * feat_mul # + img_feat modals_gate = modals * feat_mul # + modals img_feat_gate = img_feat_gate + modals_gate # 更新变量 img_feat_gate # img_feat_gate = img_feat * m1 + modals * m2
# fusion mask in feat and modals # then needs to be normalized if mask is not None and self.with_mask: # 按条件分支 mask is not None and self.with_mask mask = self.mask_convs(mask) # 调用 mask_convs 更新 mask img_feat_mask = img_feat * mask # + img_feat modals_mask = modals * mask # + modals img_feat = img_feat_gate + img_feat_mask + modals_mask # 更新变量 img_feat # img_feat = img_feat_gate + img_feat_mask * m1 + modals_mask * m2 else: # 进入兜底分支 img_feat = img_feat_gate # 更新变量 img_feat
# fusion feat and modals img_feat = self.fusion_proj(img_feat) # 调用 fusion_proj 更新 img_feat # img_feat_modals = self.modals_out_ln(img_feat) img_feat_modals = img_feat # 更新变量 img_feat_modals
################################# LLM text and image attention ########################### # fusion image and llm features if llm_feat is not None and self.with_llm_feat: # 按条件分支 llm_feat is not None and self.with_l... llm_feat = self.llm_drop(self.llm_dense(llm_feat)) # 调用 llm_drop 更新 llm_feat llm_feat = self.add_llm_pe(llm_feat) # 调用 add_llm_pe 更新 llm_feat
# downsample image img_feat, full_size = self.downsample_img_by_llm(img_feat) # 调用 downsample_img_by_llm 更新 img_feat, full_size
# ESS bs, C, H, W = img_feat.shape # 更新变量 bs, C, H, W img_feat = self.scan(img_feat).view(bs * self.K, C, H * W).transpose(1, 2) # 调用 scan 更新 img_feat img_feat = self.add_img_pe(img_feat, H, W) # 调用 add_img_pe 更新 img_feat
# multi-modal RWKV attention img_feat = self.multi_modal_img_ln(img_feat) # 调用 multi_modal_img_ln 更新 img_feat llm_feat = self.multi_modal_txt_ln(llm_feat) # 调用 multi_modal_txt_ln 更新 llm_feat # llm_feat: [bs, llm_len, c], img_feat: [bs, img_len, c]
if self.add_mm_tokens: # 按条件分支 self.add_mm_tokens multi_modal_attn_out = self.multi_modal_attn( # 调用 multi_modal_attn 更新 multi_modal_attn_out img_feat, # 执行当前语句 llm_feat.repeat(self.K, 1, 1), # 执行 repeat 调用 (H, W), # 执行当前语句 (self.img_token, self.txt_token), # 执行当前语句 ) # 结束上一层表达式 else: # 进入兜底分支 multi_modal_attn_out = self.multi_modal_attn( # 调用 multi_modal_attn 更新 multi_modal_attn_out img_feat, llm_feat.repeat(self.K, 1, 1), (H, W) # 执行 repeat 调用 ) # 结束上一层表达式
# extract img and llm feat img_feat_out, llm_feat_out = self.extract_img_and_llm_feat( # 调用 extract_img_and_llm_feat 更新 img_feat_out, llm_feat_out H, W, multi_modal_attn_out, self.with_llm_feat # 执行当前语句 ) # 结束上一层表达式
# residual img_feat = img_feat + img_feat_out # 更新变量 img_feat llm_feat = llm_feat + llm_feat_out.view(self.K, bs, -1, C).mean(dim=0) # 调用 view 更新 llm_feat
# merge ESS img_feat = rearrange( # 调用 rearrange 更新 img_feat img_feat, "(b k) (h w) d -> b k d h w", k=self.K, h=H, w=W # 更新变量 img_feat, "(b k) (h w) d -> ... ) # 结束上一层表达式 img_feat = self.merge(img_feat) / self.K # 调用 merge 更新 img_feat
# upsample image img_feat = self.upsample_img_by_llm(img_feat, full_size) # 调用 upsample_img_by_llm 更新 img_feat
# mlps img_feat = self.img_mlp(img_feat) + img_feat # 调用 img_mlp 更新 img_feat if not self.last_enc_block: # 按条件分支 not self.last_enc_block llm_feat = self.txt_mlp(llm_feat) + llm_feat # 调用 txt_mlp 更新 llm_feat
# img_feat_llm = self.llm_out_ln(img_feat) img_feat_llm = img_feat # 更新变量 img_feat_llm
return img_feat_modals, img_feat_llm, modals, llm_feat # 返回 img_feat_modals, img_feat_llm,... ###########################################################################################
return img_feat_modals, modals, llm_feat # 返回 img_feat_modals, modals, llm_f...从代码实现可见,MFM 并非“先拼接再卷积”的浅层融合,而是门控、掩码与文本交互的串联机制;文本交互发生在下采样后的序列域,以控制计算开销。
4.7 语义分支细化 掩码生成与 mask merging

在语义链路中,文中采用 Florence 生成描述、DINO 开集检测、SAM 分割实例,再将结果送入 mask merging。这个设计的必要性来自一个常被忽视的问题:不同模态对同一对象的响应强度并不一致,导致“同 prompt 下的掩码质量差异”。
文中在主文给出流程,在补充材料中给出算法细节。就主文信息而言,mask merging 的作用可归纳为:
- 抑制重复实例,即 duplicate objects;
- 缓解漏检导致的语义空洞;
- 减少错位掩码对主干更新的误导。
就结果解释而言,表 VII 中“caption + merged mask”优于“caption + unmerged mask”,可以直接视为 mask merging 的实证支持。
4.7.1 代码对照 掩码输入规范化与训练入口
主文强调 mask merging 的算法细节在补充材料中;仓库主干训练代码中可直接看到“掩码输入规范化 + one-hot 化 + 进入融合训练”的路径。
def check_multi_value_mask_to_one_hot(self, mask: torch.Tensor | None): # 定义函数 check_multi_value_mask_to_one_hot if mask is not None and self.has_mask: # 按条件分支 mask is not None and self.has_mask if self.multi_value_mask_max_classes is not None and mask.ndim == 3: # 按条件分支 self.multi_value_mask_max_classes is... # * if mask is dtype float, must be careful about its values, must be in [0, multi_value_mask_max_classes] # * if float value in it, the code will raise CUDA error by `scatter_` without clear hint.
mask[mask >= self.multi_value_mask_max_classes] = ( # 执行当前语句 0.0 # larger than max classes are set to background ) # 结束上一层表达式 new_mask = torch.zeros( # 调用 zeros 更新 new_mask mask.size(0), # 执行 size 调用 self.multi_value_mask_max_classes, # 执行当前语句 *mask.shape[-2:], # 执行当前语句 device=mask.device, # 更新变量 device dtype=torch.float32, # 更新变量 dtype ) # 结束上一层表达式 new_mask.scatter_(1, mask.long()[:, None], 1.0) # 执行 scatter_ 调用 elif mask.ndim == 4: # 分支判断 mask.ndim == 4 new_mask = mask # 更新变量 new_mask else: # 进入兜底分支 raise ValueError( # 执行 ValueError 调用 f"Invalid mask shape: {mask.shape} when `multi_value_mask_max_classes` is {self.multi_value_mask_max_classes}", # 执行当前语句 "or model has `has_mask` as True. Input mask should be 3D or 4D tensor", # 执行当前语句 "such as [Bs, 1, H, W] or [Bs, *, H, W] (to be one-hot encoded in this case).", # 执行当前语句 ) # 结束上一层表达式 else: # 进入兜底分支 new_mask = None # 更新变量 new_mask
return new_mask # 返回 new_mask def fusion_train_step( # 定义函数 fusion_train_step self, # 执行当前语句 vi: "torch.Tensor", # 执行当前语句 ir: "torch.Tensor", # 执行当前语句 mask: "torch.Tensor | None" = None, # 更新变量 mask: "torch.Tensor | None" gt: "torch.Tensor | None" = None, # 更新变量 gt: "torch.Tensor | None" txt: "torch.Tensor | None" = None, # 更新变量 txt: "torch.Tensor | None" fusion_criterion: "Callable | None" = None, # 更新变量 fusion_criterion: "Callable ... to_rgb_fn: "Callable | None" = None, # 更新变量 to_rgb_fn: "Callable | None" has_gt: bool = False, # 更新变量 has_gt: bool **_kwargs, # 执行当前语句 ): # 结束上一层表达式 vi, ir, mask, txt = self.check_multi_modal_inputs( # 调用 check_multi_modal_inputs 更新 vi, ir, mask, txt vi, ir, mask, txt, vi.device, vi.dtype # 执行当前语句 ) # 结束上一层表达式 txt = self.drop_txt(txt) # 调用 drop_txt 更新 txt
mask = self.check_multi_value_mask_to_one_hot(mask) # 调用 check_multi_value_mask_to_one_hot 更新 mask
fused_outp = self.only_fusion_step(vi, ir, mask, txt) # 调用 only_fusion_step 更新 fused_outp
# mask for loss, should be detached if mask is not None: # 按条件分支 mask is not None mask_for_loss = mask.clone().detach() # 调用 clone 更新 mask_for_loss else: # 进入兜底分支 mask_for_loss = None # 更新变量 mask_for_loss
fused_for_loss = to_rgb_fn(fused_outp) if to_rgb_fn is not None else fused_outp # 调用 to_rgb_fn 更新 fused_for_loss if ( # 按条件分支 ( has_gt or gt.size(1) == 3 # 执行 size 调用 ): # TODO: find more robust way to check if gt is available # if we have supervised GT, we use it to compute the supervised loss # sometimes, for MEF fusion task, we can access the GTs fusion_gt = gt # 更新变量 fusion_gt # two different modalities for GT to compute the unsupervised loss boundary_gt = (vi, ir) # 更新变量 boundary_gt else: # 进入兜底分支 fusion_gt = None # 更新变量 fusion_gt boundary_gt = (vi, ir) # 更新变量 boundary_gt
# compute supervised and unsupervised losses assert fusion_criterion is not None, "fusion_criterion should be provided" # 执行断言校验 loss = list( # 调用 list 更新 loss fusion_criterion( # 执行 fusion_criterion 调用 fused_for_loss, # 执行当前语句 boundary_gt=boundary_gt, # 更新变量 boundary_gt fusion_gt=fusion_gt, # 更新变量 fusion_gt mask=mask_for_loss, # 更新变量 mask ) # 结束上一层表达式 ) # 结束上一层表达式
return fused_for_loss.clip(0, 1), loss # 返回 fused_for_loss.clip(0, 1), los...
@torch.no_grad() # 装饰器声明这表明 mask 引导在工程实现中属于训练闭环的必要输入路径。
4.8 损失函数设计 监督场景分流
文中按任务监督属性划分损失函数。
4.8.1 有监督 HMIF / Pansharpening
式(19)由像素一致性与结构一致性共同约束。其意义是避免单纯 L1 导致结构退化,也避免单纯结构项造成光谱/亮度偏移。
4.8.2 无监督 VIF / MIF / MEF / MFF
式(20)–式(23)对应典型的“强度-结构-边缘”三约束配比。对于无 GT 的融合任务,这是可解释性较强、工程上较稳定的选择:强度项控制内容保留,SSIM 项控制结构一致,梯度项控制细节锐度。
4.8.3 代码对照 损失实现与文中公式映射
损失实现位于 utils/loss_utils.py 的 DRMFFusionLoss.forward。该实现是“文中损失族”的通用化版本,支持有监督/无监督、多任务权重与可选掩码约束。
def forward( # 定义函数 forward self, # 执行当前语句 img_fusion: Tensor, # 执行当前语句 boundary_gt: "Tensor | tuple", # cat([vi, ir]) or tuple(vi, ir) fusion_gt: "Tensor" = None, # ground truth provided in dataset mask: "Tensor | None" = None, # 更新变量 mask: "Tensor | None" ) -> tuple[torch.Tensor, dict[str, torch.Tensor]]: # 结束上一层表达式 if mask is not None and self.mask_loss: # 按条件分支 mask is not None and self.mask_loss self.check_dtype_and_device(img_fusion, boundary_gt, mask) # 执行 check_dtype_and_device 调用 with torch.no_grad(): # 进入上下文 torch.no_grad() if self.reduce_label: # 按条件分支 self.reduce_label mask2 = mask.detach().clone() # 调用 detach 更新 mask2 mask2[mask2 > 1.0] = 1.0 # 更新变量 mask2[mask2 > 1.0] else: # 进入兜底分支 mask2 = mask # 更新变量 mask2
## TODO: consider this case # mask.size(1) == 2, two boundaries all have masks if mask2.size(1) == 2: # 按条件分支 mask2.size(1) == 2 assert False, "mask.size(1) == 2, two boundaries all have masks" # 执行断言校验 mask_B, mask_A = mask2.chunk(2, dim=1) # 调用 chunk 更新 mask_B, mask_A else: # 进入兜底分支 mask_B, mask_A = mask2, mask2 # 更新变量 mask_B, mask_A elif not self.mask_loss: # 分支判断 not self.mask_loss mask2 = None # cast to None
self.check_dtype_and_device(img_fusion, boundary_gt) # 执行 check_dtype_and_device 调用
wd = self.weight_dict # 更新变量 wd loss_intensity = 0 # 更新变量 loss_intensity loss_color = 0 # 更新变量 loss_color loss_grad = 0 # 更新变量 loss_grad loss_fusion = 0 # 更新变量 loss_fusion loss = {} # 更新变量 loss
# split boundary gt no_batch_ndim = img_fusion.ndim - 1 # 更新变量 no_batch_ndim broadcast_fn = lambda x: x.reshape(-1, *[1] * no_batch_ndim) # noqa: py3.11 supported
# img_A: ir/under/MRI, img_B: vi/over/spect if isinstance(boundary_gt, (tuple, list)): # 按条件分支 isinstance(boundary_gt, (tuple, list... img_B, img_A = boundary_gt # 更新变量 img_B, img_A else: # 进入兜底分支 img_B, img_A = self.split_boundary_gt_tensor(boundary_gt) # 调用 split_boundary_gt_tensor 更新 img_B, img_A
# if has gt (e.g., when we train model on multi-exposure image fusion task) if exist_gt := exists(fusion_gt): # 按条件分支 exist_gt := exists(fusion_gt) gt_loss = wd["fusion_gt"] * self.loss_func(img_fusion, fusion_gt).nanmean() # 调用 loss_func 更新 gt_loss loss["gt_loss"] = gt_loss # 更新变量 loss["gt_loss"] loss_fusion += gt_loss # 更新变量 loss_fusion +
if self.grad_norm: # 按条件分支 self.grad_norm img_fusion = grad_norm(img_fusion) # 调用 grad_norm 更新 img_fusion
# ir, vi (detached in this function) (img_A, A_is_color), (img_B, B_is_color) = ( # 更新变量 (img_A, A_is_color), (img_B,... self.check_rgb(img_A), # 执行 check_rgb 调用 self.check_rgb(img_B), # 执行 check_rgb 调用 ) # 结束上一层表达式
## vgg latent weights # the latent weights comes from U2Fusion paper if self.latent_weighted: # 按条件分支 self.latent_weighted vi_w, ir_w = self.dynamic_weight(img_A, img_B) # 调用 dynamic_weight 更新 vi_w, ir_w vi_w = broadcast_fn(vi_w) # 调用 broadcast_fn 更新 vi_w ir_w = broadcast_fn(ir_w) # 调用 broadcast_fn 更新 ir_w else: # 进入兜底分支 vi_w, ir_w = 1.0, 1.0 # 更新变量 vi_w, ir_w
# YCbCr decomposition # use for intensity, color, and gradient loss Y_fusion, Cb_fusion, Cr_fusion = kornia.color.rgb_to_ycbcr(img_fusion).chunk( # 调用 rgb_to_ycbcr 更新 Y_fusion, Cb_fusion, Cr_fusi... 3, dim=1 # 更新变量 3, dim ) # 结束上一层表达式 Y_A, Cb_A, Cr_A = kornia.color.rgb_to_ycbcr(img_A).chunk(3, dim=1) # ir Y_B, Cb_B, Cr_B = kornia.color.rgb_to_ycbcr(img_B).chunk(3, dim=1) # vi
## intensity and color loss # * compute boundary intensity and color loss when GT is not provided # * or we omit computing the loss # * in this case, we can say intensity and color are supervised by the GT # * we do not need to use the unsupervised loss # * `still_boundary_loss_when_gt` is to keep the boundary loss when GT is provided (optional) if (not exist_gt) or self.still_boundary_loss_when_gt: # 按条件分支 (not exist_gt) or self.still_boundar... if self.prior == "max": # 按条件分支 self.prior == "max" Y_joint = torch.max(Y_A, Y_B) # 调用 max 更新 Y_joint elif self.prior == "mean": # 分支判断 self.prior == "mean" Y_joint = (Y_A + Y_B) / 2 # 更新变量 Y_joint
if self.grad_norm: # 按条件分支 self.grad_norm Y_fusion = grad_norm(Y_fusion) # 调用 grad_norm 更新 Y_fusion Cb_fusion = grad_norm(Cb_fusion) # 调用 grad_norm 更新 Cb_fusion Cr_fusion = grad_norm(Cr_fusion) # 调用 grad_norm 更新 Cr_fusion
if mask2 is not None: # 按条件分支 mask2 is not None # * intensity loss # 1. || fusion - max(vi, ir) || max fusion # 2. || mask * fusion - mask * ir || ir loss (pedistrain) # 3. || (1 - mask) * fusion - (1 - mask) * vi || vi loss (background)
loss_intensity = ( # 更新变量 loss_intensity ( # 执行当前语句 wd["inten_f_joint"] * self.loss_func(Y_fusion, Y_joint) # 执行 loss_func 调用 if self.use_prior # 按条件分支 self.use_prior else 0.0 # 执行当前语句 ) # 结束上一层表达式 + ( # 执行当前语句 wd["inten_f_ir"] # 执行当前语句 * ir_w # 执行当前语句 * self.loss_func(mask2 * Y_fusion, mask2 * Y_A) # 执行 loss_func 调用 if self.boundary # 按条件分支 self.boundary else 0.0 # 执行当前语句 ) # 结束上一层表达式 + ( # 执行当前语句 wd["inten_f_vi"] # 执行当前语句 * vi_w # 执行当前语句 * self.loss_func(Y_fusion * (1 - mask2), Y_B * (1 - mask2)) # 执行 loss_func 调用 if self.boundary # 按条件分支 self.boundary else 0.0 # 执行当前语句 ) # 结束上一层表达式 ) # 结束上一层表达式 # * color loss # 1. || (1-mask) * fusion_Cb - (1-mask) * ir_Cb || ir_Cb loss # 2. || (1-mask) * fusion_Cr - (1-mask) * ir_Cr || ir_Cr loss if self.color_loss_bg_masked: # 按条件分支 self.color_loss_bg_masked bg_mask = 1.0 - mask2 # 更新变量 bg_mask else: # 进入兜底分支 bg_mask = torch.ones_like(mask2) # 调用 ones_like 更新 bg_mask if self.color_loss: # 按条件分支 self.color_loss loss_color = 0.0 # 更新变量 loss_color if B_is_color: # 按条件分支 B_is_color loss_color += wd["color_f_cb"] * vi_w * self.loss_func( # 调用 loss_func 更新 loss_color + Cb_fusion * bg_mask, Cb_B * bg_mask # 执行当前语句 ) + wd["color_f_cr"] * ir_w * self.loss_func( # 结束上一层表达式 Cr_fusion * bg_mask, Cr_B * bg_mask # 执行当前语句 ) # 结束上一层表达式 if A_is_color: # 按条件分支 A_is_color loss_color += wd["color_f_cb"] * ir_w * self.loss_func( # 调用 loss_func 更新 loss_color + Cb_fusion * bg_mask, Cb_A * bg_mask # 执行当前语句 ) + wd["color_f_cr"] * vi_w * self.loss_func( # 结束上一层表达式 Cr_fusion * bg_mask, Cr_A * bg_mask # 执行当前语句 ) # 结束上一层表达式 else: # 进入兜底分支 loss_intensity = ( # 更新变量 loss_intensity ( # 执行当前语句 wd["inten_f_joint"] * self.loss_func(Y_fusion, Y_joint) # 执行 loss_func 调用 if self.use_prior # 按条件分支 self.use_prior else 0.0 # 执行当前语句 ) # 结束上一层表达式 + ( # 执行当前语句 wd["inten_f_ir"] * ir_w * self.loss_func(Y_fusion, Y_A) # 执行 loss_func 调用 if self.boundary # 按条件分支 self.boundary else 0.0 # 执行当前语句 ) # 结束上一层表达式 + ( # 执行当前语句 wd["inten_f_vi"] * vi_w * self.loss_func(Y_fusion, Y_B) # 执行 loss_func 调用 if self.boundary # 按条件分支 self.boundary else 0.0 # 执行当前语句 ) # 结束上一层表达式 ) # 结束上一层表达式
if self.color_loss: # 按条件分支 self.color_loss loss_color = 0.0 # 更新变量 loss_color if B_is_color: # 按条件分支 B_is_color loss_color += wd["color_f_cb"] * self.loss_func( # 调用 loss_func 更新 loss_color + Cb_fusion, Cb_B # 执行当前语句 ) + wd["color_f_cr"] * self.loss_func(Cr_fusion, Cr_B) # 结束上一层表达式 if A_is_color: # 按条件分支 A_is_color loss_color += wd["color_f_cb"] * self.loss_func( # 调用 loss_func 更新 loss_color + Cb_fusion, Cb_A # 执行当前语句 ) + wd["color_f_cr"] * self.loss_func(Cr_fusion, Cr_A) # 结束上一层表达式
loss_intensity = loss_intensity.nanmean() # 调用 nanmean 更新 loss_intensity loss_fusion += loss_intensity # 更新变量 loss_fusion + loss["intensity_loss"] = loss_intensity # 更新变量 loss["intensity_loss"] if self.color_loss: # 按条件分支 self.color_loss loss_color = loss_color.nanmean() # 调用 nanmean 更新 loss_color loss_fusion += loss_color # 更新变量 loss_fusion + loss["loss_color"] = loss_color # 更新变量 loss["loss_color"]
## lpips loss # * lpips loss is to enhance perceptual visuality if self.lpips: # 按条件分支 self.lpips lpips_loss = 0.0 # 更新变量 lpips_loss if exist_gt: # 按条件分支 exist_gt lpips_loss += self.lpips_loss(img_fusion, fusion_gt) * wd["lpips_f_gt"] # 调用 lpips_loss 更新 lpips_loss +
# if self.still_boundary_loss_when_gt or (not exist_gt): # lpips_loss += self.lpips_loss(img_fusion, img_A) * wd['lpips_f_ir'] + \ # self.lpips_loss(img_fusion, img_B) * wd['lpips_f_vi'] # if self.use_prior: # if self.prior == 'max': # img_joint = torch.max(img_A, img_B) # elif self.prior == 'mean': # img_joint = (img_A + img_B) / 2 # lpips_loss += self.lpips_loss(img_fusion, img_joint) * wd['lpips_f_joint']
loss_fusion += lpips_loss # 更新变量 loss_fusion + loss["lpips_loss"] = lpips_loss # 更新变量 loss["lpips_loss"]
## grad loss # * gradient loss is to enhance the fused image # * keep it although the GT is provided if self.grad: # 按条件分支 self.grad if self.grad_only_on_Y: # 按条件分支 self.grad_only_on_Y grad_A = self.grad_op(Y_A) # 调用 grad_op 更新 grad_A grad_B = self.grad_op(Y_B) # 调用 grad_op 更新 grad_B grad_fusion = self.grad_op(Y_fusion) # 调用 grad_op 更新 grad_fusion else: # 进入兜底分支 grad_A = self.grad_op(img_A) # 调用 grad_op 更新 grad_A grad_B = self.grad_op(img_B) # 调用 grad_op 更新 grad_B grad_fusion = self.grad_op(img_fusion) # 调用 grad_op 更新 grad_fusion
if self.grad_norm: # 按条件分支 self.grad_norm grad_fusion = grad_norm(grad_fusion) # 调用 grad_norm 更新 grad_fusion
grad_joint = torch.max(grad_A, grad_B) # 调用 max 更新 grad_joint loss_grad += wd["grad_f_joint"] * self.loss_func(grad_fusion, grad_joint) # 调用 loss_func 更新 loss_grad + # if mask is not None: # mask_expand = mask # if grad_fusion.ndim > 4: # mask_expand = mask_expand.unsqueeze(1) # loss_grad += wd['grad_f_ir'] * self.loss_func(grad_fusion * mask_expand, grad_A * mask_expand)
# loss_grad += wd['grad_f_ir'] * self.loss_func(grad_fusion, grad_A) + \ # wd['grad_f_vi'] * self.loss_func(grad_fusion, grad_B)
loss_grad = loss_grad.nanmean() # 调用 nanmean 更新 loss_grad
loss_fusion += loss_grad # 更新变量 loss_fusion + loss.update({"loss_grad": loss_grad}) # 执行 update 调用
## ssim loss # * ssim loss is to enhance the fused image # * keep it although the GT is provided if self.ssim: # 按条件分支 self.ssim w_A = grad_A.norm() # 调用 norm 更新 w_A w_B = grad_B.norm() # 调用 norm 更新 w_B Z = w_A + w_B # 更新变量 Z w_A /= Z # 更新变量 w_A / w_B /= Z # 更新变量 w_B /
if self.grad_only_on_Y: # 按条件分支 self.grad_only_on_Y ssim_A = self.ssim_func(Y_fusion, Y_A) # 调用 ssim_func 更新 ssim_A ssim_B = self.ssim_func(Y_fusion, Y_B) # 调用 ssim_func 更新 ssim_B else: # 进入兜底分支 ssim_A = self.ssim_func(img_fusion, img_A) # 调用 ssim_func 更新 ssim_A ssim_B = self.ssim_func(img_fusion, img_B) # 调用 ssim_func 更新 ssim_B loss_ssim = wd["ssim_f_joint"] * (w_A * ssim_A + w_B * ssim_B) # 更新变量 loss_ssim loss_fusion += loss_ssim # 更新变量 loss_fusion + loss.update({"loss_ssim": loss_ssim}) # 执行 update 调用
## tv loss if self.tv: # 按条件分支 self.tv img_fusion_tv = img_fusion # 更新变量 img_fusion_tv if self.grad_norm: # 按条件分支 self.grad_norm img_fusion_tv = grad_norm(img_fusion_tv) # 调用 grad_norm 更新 img_fusion_tv tv_loss = wd["tv_f"] * self.tv_loss(img_fusion_tv).nanmean() # 调用 tv_loss 更新 tv_loss loss_fusion += tv_loss # 更新变量 loss_fusion + loss.update({"tv_loss": tv_loss}) # 执行 update 调用
## correlation loss if self.correlation: # 按条件分支 self.correlation img_fusion_tv = img_fusion # 更新变量 img_fusion_tv if self.grad_norm: # 按条件分支 self.grad_norm img_fusion_tv = grad_norm(img_fusion_tv) # 调用 grad_norm 更新 img_fusion_tv loss_corr = wd["crr_f"] * self.cc_loss(img_A, img_B, img_fusion_tv) # 调用 cc_loss 更新 loss_corr loss_fusion += loss_corr # 更新变量 loss_fusion + loss.update({"loss_corr": loss_corr}) # 执行 update 调用
loss.update({"loss_fusion": loss_fusion}) # 执行 update 调用
return loss_fusion, loss # 返回 loss_fusion, loss
##### 4.8.3.1 EMMA stage two fusion training lossloss_cfg: # 配置项 loss_cfg drmffusion: # 配置项 drmffusion latent_weighted: no # 配置项 latent_weighted grad_loss: yes # 配置项 grad_loss color_loss: no # VIF: yes, others: no ssim_loss: yes # 配置项 ssim_loss prior: null # 配置项 prior boundary_loss: yes # 配置项 boundary_loss mask_loss: no # VIF: yes, others: no lpips_loss: no # 配置项 lpips_loss color_loss_bg_masked: yes # 配置项 color_loss_bg_masked tv_loss: no # 配置项 tv_loss pseudo_l1_const: 0. # [0.002, 0.] correlation_loss: no # 配置项 correlation_loss reduce_label: no # VIF: no grad_only_on_Y: no # 配置项 grad_only_on_Y grad_op: "sobel_add" # 配置项 grad_op still_boundary_loss_when_gt: yes # 配置项 still_boundary_loss_when_gt grad_norm: no # 配置项 grad_norm ssim_implm_by: torch # 配置项 ssim_implm_by ssim_window_size: 5 # 配置项 ssim_window_size weight_dict: # 配置项 weight_dict fusion_gt: 5. # 配置项 fusion_gt
inten_f_joint: 10. # prior used inten_f_ir: 10. # 配置项 inten_f_ir inten_f_vi: 10. # 配置项 inten_f_vi
color_f_cb: 2. # 配置项 color_f_cb color_f_cr: 2. # 配置项 color_f_cr
grad_f_joint: 20. # [5, 40] for VIF and MEF ssim_f_joint: 2. # 配置项 ssim_f_joint
lpips_f_gt: 1. # 配置项 lpips_f_gt
tv_f: 0.1 # 配置项 tv_f crr_f: 0.02 # 配置项 crr_f
# unused lpips_f_joint: 0.2 # 配置项 lpips_f_joint lpips_f_ir: 0.2 # 配置项 lpips_f_ir lpips_f_vi: 0.2 # 配置项 lpips_f_vi
filmfusion: # 配置项 filmfusion prior: mean # 配置项 prior weight_grad: 1000 # 配置项 weight_grad weight_ssim: 1. # 配置项 weight_ssim ssim_window_size: 5 # 配置项 ssim_window_size
l1ssim: # 配置项 l1ssim weighted_r: [1.0, 0.1] # 配置项 weighted_r implem_by: torch # 配置项 implem_by window_size: 5 # 配置项 window_size grad_norm: no # 配置项 grad_norm因此,式(19)-式(23)在仓库中并未采用逐式静态硬编码,而是通过统一损失框架按任务配置激活并加权;这也是其可迁移覆盖 VIF/MEF/MFF/MIF/HMIF/Pansharpening 多任务训练流程的工程基础。
05 实验分析
主要分析 SOTA 对比表以及消融实验。
5.1 实验设置与评测协议
5.1.1 任务覆盖与数据集
文中覆盖六类融合任务:
- VIF:MSRS、M3FD、TNO;
- MIF:Medical Harvard;
- MEF:SICE、MEFB;
- MFF:MFI-WHU、RealMFF;
- Pansharpening:WV3、GF2、QB;
- HMIF:Chikusei、Pavia。
这一覆盖范围保证结论不局限于单任务分布。尤其是同时包含跨传感器融合,如 VIF、Pansharpening、HMIF,以及同传感器参数差异融合,如 MEF、MFF,使方法泛化判断更可信。
5.1.2 基线与指标
文中基线覆盖 decomposition、task-designed、prior-based、architecture-designed、modality-guided 等多类方法。指标体系包含 MI、VIF、SF、Qcb、Qy、Qcv、Qabf、LPIPS,以及 SAM、ERGAS、Q2n、HQNR、PSNR、SSIM 等。
从评估逻辑看,这套指标组合同时约束了信息量、结构质量、感知一致性与遥感光谱质量,避免“单指标最优”误导。
5.1.3 语义输入配置与任务差异化处理
文中在语义输入上并非“一套配置跑全部任务”,而是根据任务属性做了条件化策略,这一点对复现实验非常关键:
- 在 VIF 场景中,M3FD 采用固定 prompt:People、Car、Bus、Lamp、Motorcycle、Truck,并执行 mask merging;
- MSRS 直接使用数据集给出的人工掩码;
- MEF/MFF/MIF 由于场景对象差异较大,采用 Florence 自动提取 prompt 以支持开集语义;
- Pansharpening 与 HMIF 因训练样本常用 64×64 小块,文中设置为仅保留语言引导,不使用 mask 引导。
这个配置策略背后有明确原则:当空间尺寸较小、对象边界不稳定或掩码噪声可能压过有效信息时,强行注入 mask 反而可能引入误导;而在目标显著、语义对象明确的场景,如 VIF,mask 的收益更容易释放。换言之,RWKVFusion 并非在所有任务中执行等强度语义注入,而是依据数据形态进行可解释的注入强度调度。
5.1.4 指标解释的组织顺序
文中指标较多,若不做层次化组织,容易出现“指标堆叠但结论模糊”的问题。本文采用如下解释顺序:
- 先看任务核心指标,如遥感任务的 SAM/ERGAS/Q2n/HQNR,VIF 的 MI/VIF/Q 系列;
- 再看感知相关指标,如 LPIPS 与结构保持,判断是否存在“分数上升但视觉退化”;
- 最后结合可视化图 Fig.8、Fig.9,验证指标变化是否对应可解释的视觉差异。
按这个顺序,RWKVFusion 的优势会更清晰:它在多数任务上不是单一指标尖峰,而是在“信息量、结构一致、下游可用性”三条轴上同时保持稳定。这也是图1 雷达图呈现外扩包络的根本原因。
5.2 主实验结果 结论与证据链
5.2.1 VIF 与 MIF
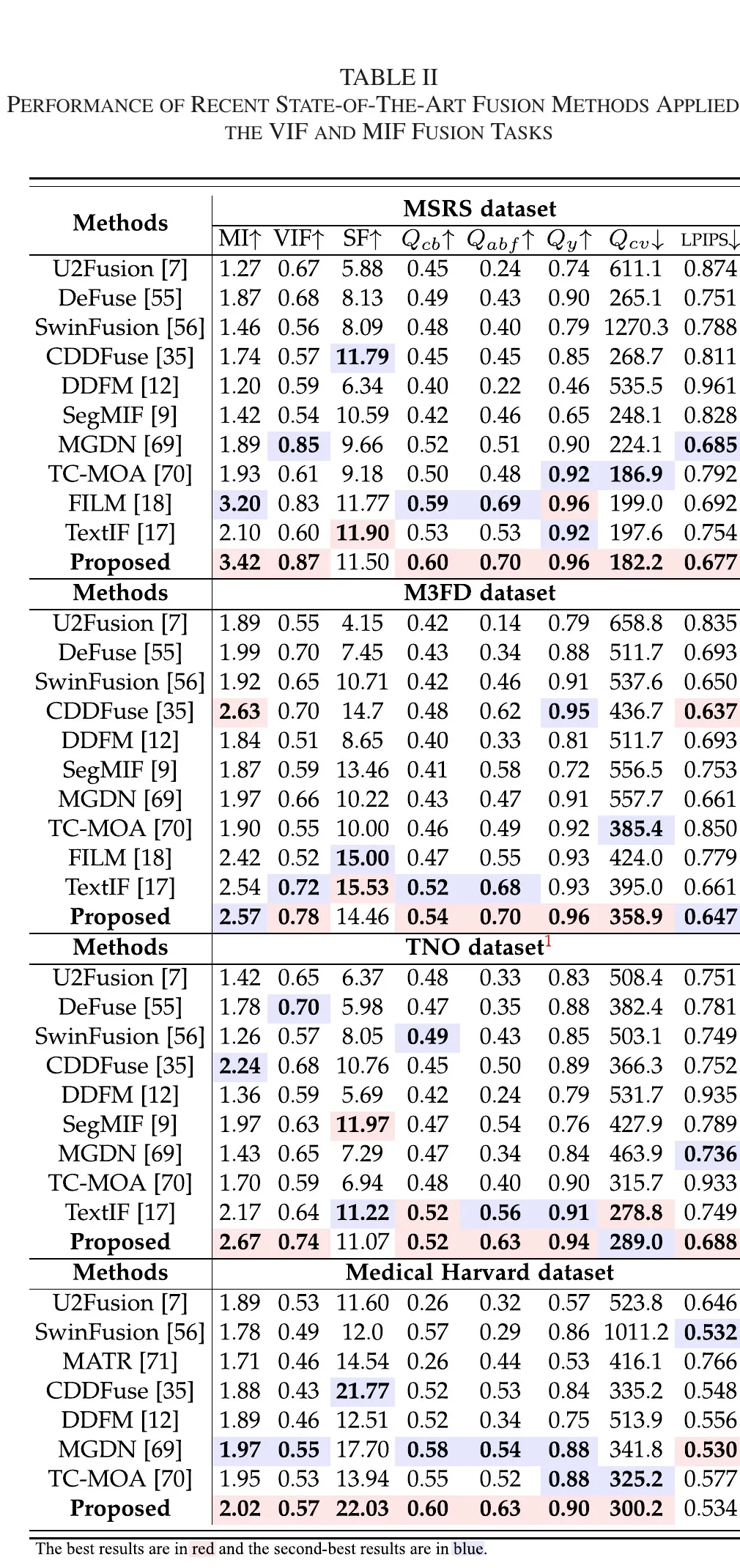
文中对 VIF 的报告显示:
- 在 MSRS 上,8 项指标中 7 项最优;
- 在 M3FD、TNO 上,多数指标第一或第二;
- 在 Medical Harvard 数据集 MIF 上,除 LPIPS 外其余指标领先。
文中节选值包括:M3FD 上 MI 2.57、VIF 0.78、Qabf 0.70、Qy 0.96;Medical Harvard 上 MI 2.02、VIF 0.57、SF 22.03、Qy 0.90。该证据链支持一个关键结论:语义引导并没有以牺牲纹理/结构指标为代价,而是在目标保持与视觉一致性之间取得了联合收益。
5.2.2 MEF 与 MFF
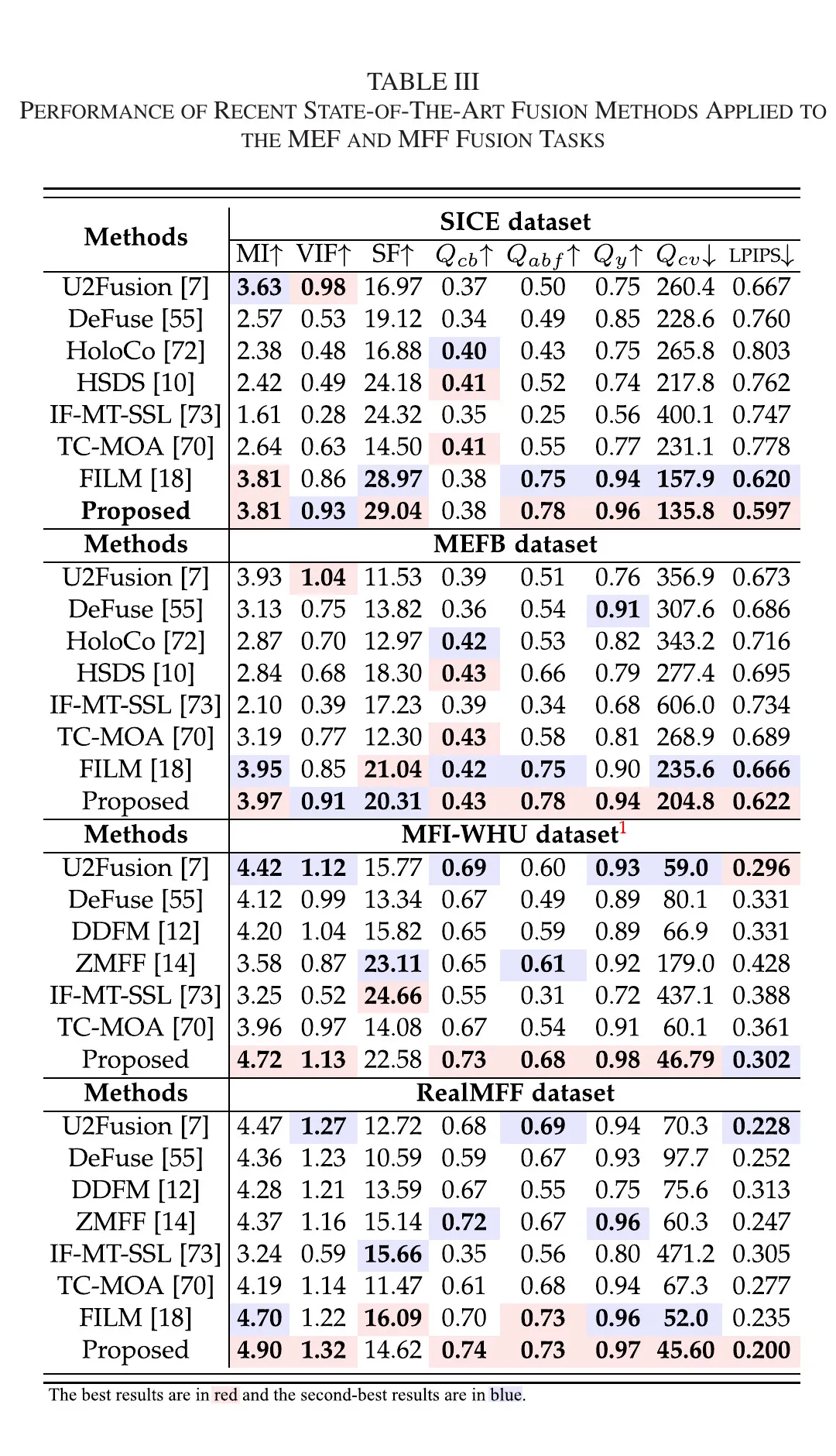

结合 Table III 与图8 :
- 定量上,RWKVFusion 在 SICE、MEFB、MFI-WHU、RealMFF 的多数指标中处于领先;
- 定性上,方法在高亮区和暗区之间维持更一致的曝光平衡,并在焦内/焦外边界处保留更完整纹理。
5.2.3 Pansharpening 与 HMIF
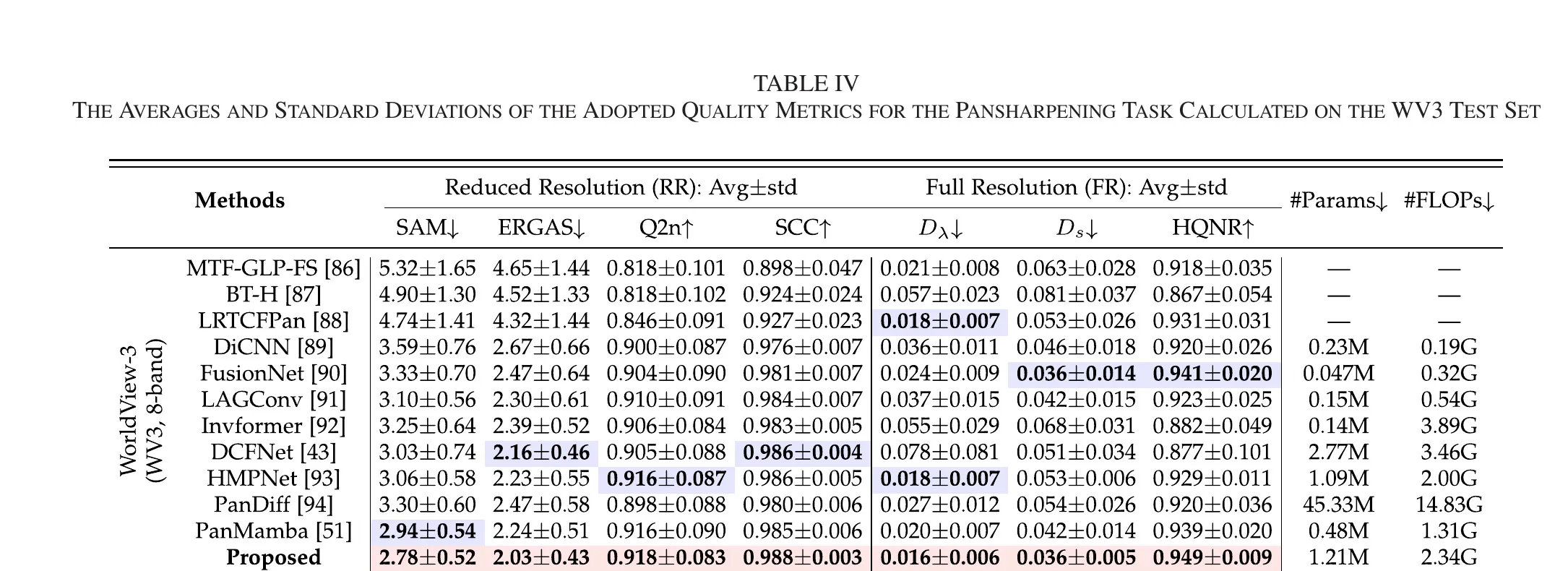
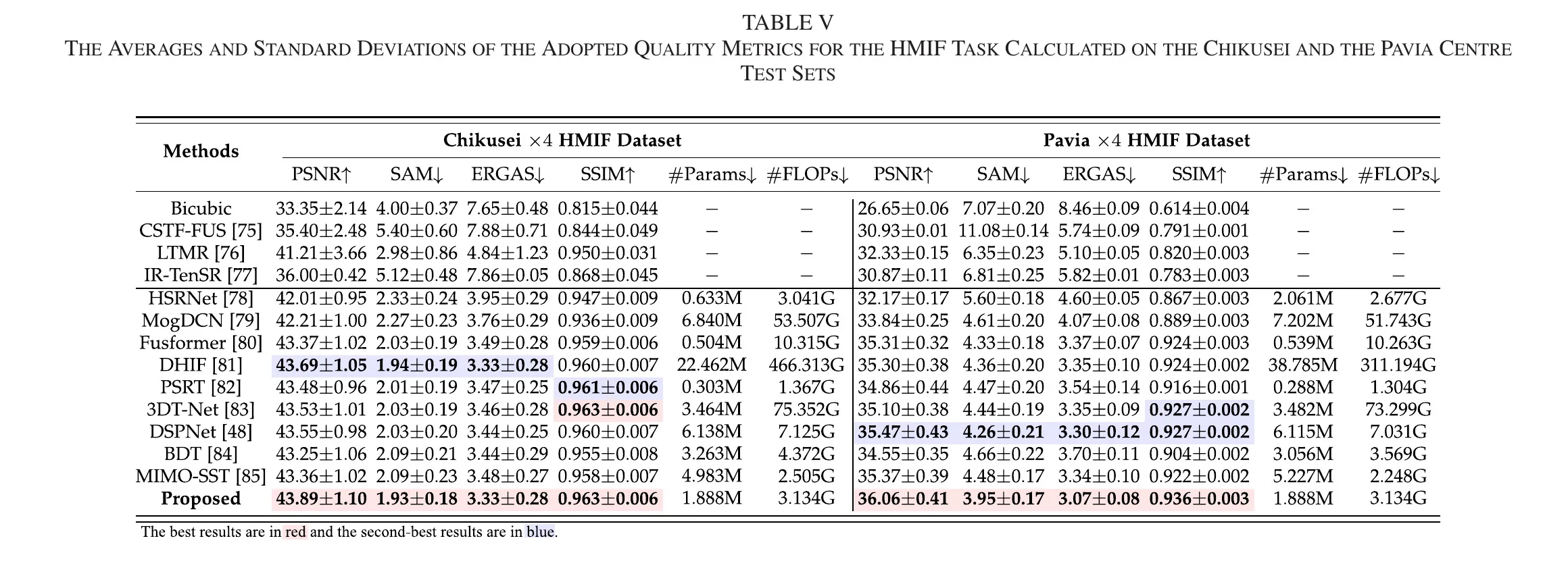

文中给出的关键数值包括:
- WV3:SAM 2.78、ERGAS 2.03、Q2n 0.918、SCC 0.988、 0.016、 0.036、HQNR 0.949;
- Chikusei:PSNR 43.89、SAM 1.93、ERGAS 3.33、SSIM 0.963;
- Pavia:PSNR 36.06、SAM 3.95、ERGAS 3.07、SSIM 0.936。
文中同时指出,在 HMIF 对比中,RWKVFusion 相对 DHIF 仅使用约 8.41% 参数量和 0.67% FLOPs。该“性能 + 复杂度”联合结果,是其方法价值的重要支撑。
5.2.4 跨任务一致性与结果边界
把 VIF/MIF/MEF/MFF 与 Pansharpening/HMIF 放在一起看,可以观察到 RWKVFusion 的一个鲜明特征: 优势不依赖单一模态组合或单一退化类型。前四类任务主要考察自然图像层面的纹理与目标保留,后两类任务强调光谱一致性与空间细节重建;RWKVFusion 在这两类评价体系中都能给出正向结果,说明其主干设计并未绑定于某一任务先验。
但该一致性并不意味着“无条件全胜”。从文中呈现可见,个别指标上仍可能出现次优,这与任务差异、上游语义质量和评价指标偏好有关。这里应避免把文中结论简化成“全指标第一”,更准确的表述是:RWKVFusion 在跨任务综合表现和性能-复杂度平衡上具备显著优势。
5.3 消融实验
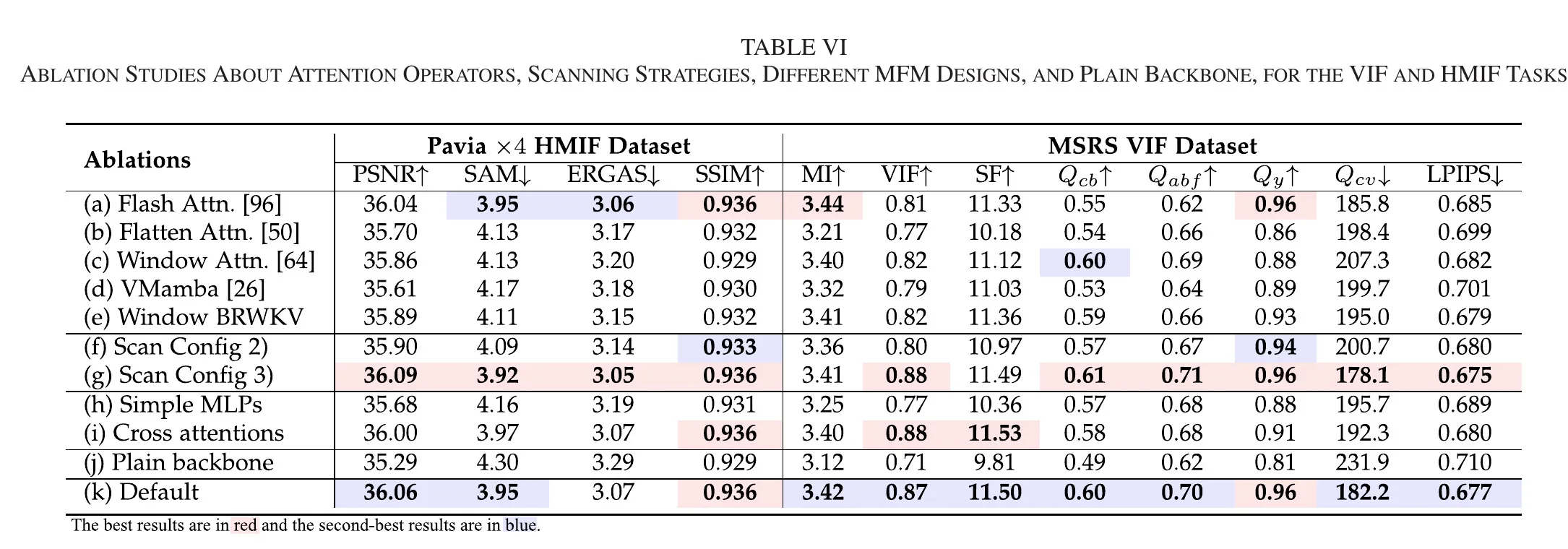
5.3.1 BRWKV 与替代算子
文中将 BRWKV 替换为 flash attention、flatten attention、window attention、VMamba。结果显示 BRWKV 在大多数指标上更稳。该结论说明性能提升并非来自“简单扩大参数规模”,而是来自 WKV 机制与融合任务需求匹配。
5.3.2 ESS 扫描策略
消融显示:4 scans 并未稳定优于默认配置;8 scans 在部分指标略好但计算代价增大。结论是默认 ESS 在效率-性能之间达到更优折中。
5.3.3 MFM 结构替换
将 MFM 替换为简单 MLP 或 cross-attention 变体后,指标下降。该结果与图6 可视化一致,说明三路径语义注入 raw/modality + mask + text 具有不可替代的机制价值。
5.3.4 语义引导与 mask merging
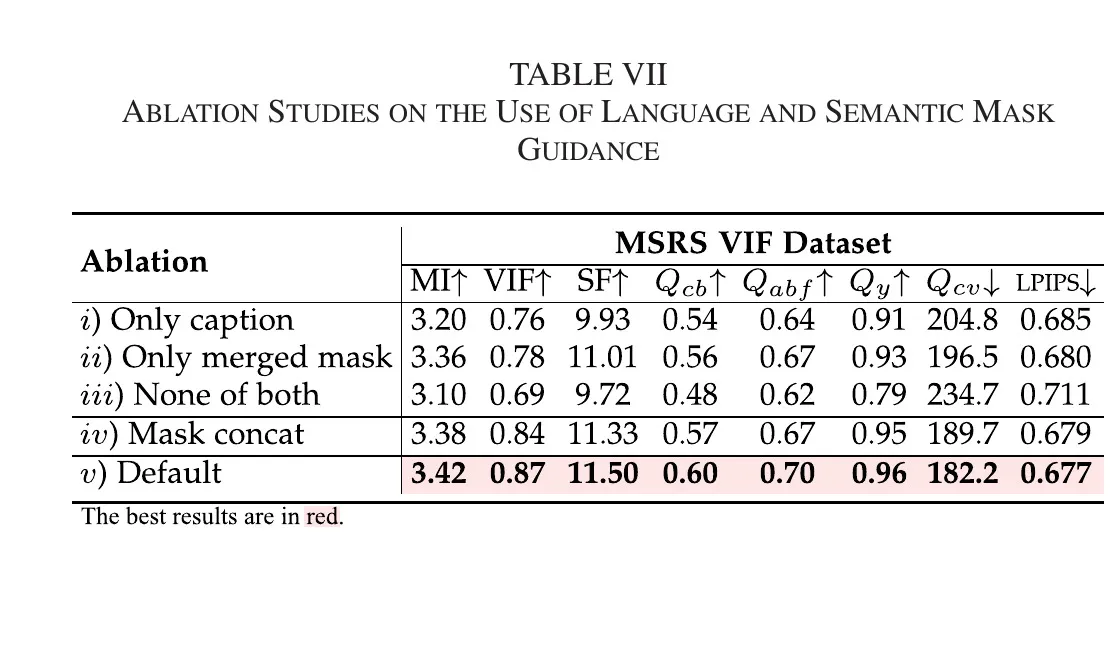
在 MSRS 上,文中报告:
- only caption:MI 3.20、VIF 0.76;
- only merged mask:MI 3.36、VIF 0.78;
- no guidance:MI 3.10、VIF 0.69;
- caption + unmerged mask:MI 3.38、VIF 0.84;
- caption + merged mask,默认设置:MI 3.42、VIF 0.87。
该组结果支持以下两条因果判断:
- caption 与 mask 是互补信号,不是冗余信号;
- mask merging 的收益是独立可验证的,不是与 caption 强绑定后的偶然增益。
5.3.5 Prompt 设定
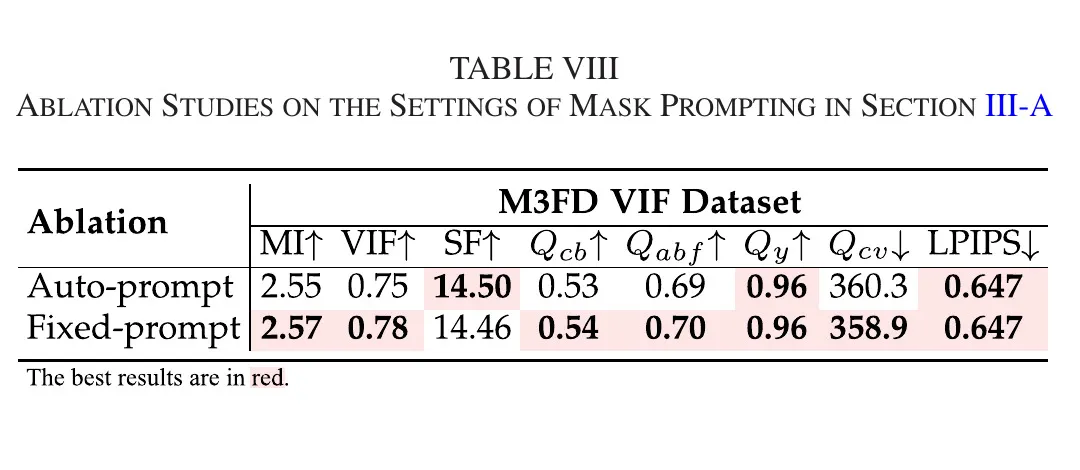
fixed-prompt 略优于 auto-prompt,但二者均优于多数对比方法。该现象说明:开放式语义引导是可行的,但上游提示词质量仍会影响最终融合上限。
5.3.6 Plain 与 Multi-scale
文中在 plain backbone 对照下显示多尺度结构更优,且参数量同量级。对于像素级融合任务,这说明“跨尺度上下文传递”仍是必要条件,而非可随意替代的结构装饰。
5.3.7 ERF 证据

5.4 下游任务验证 融合质量是否可迁移
下游任务部分的关键问题是:融合结果是否真正提升感知模型表现,而不仅是视觉观感更“清晰”。这里分别给出 Table IX 语义分割与 Table X 目标检测,并在对应小节逐项解读。
5.4.1 单目深度估计

该部分文中给出的是可视化证据。统一量化深度指标,如 Abs Rel、RMSE,文中未给出/未报告。
5.4.2 语义分割

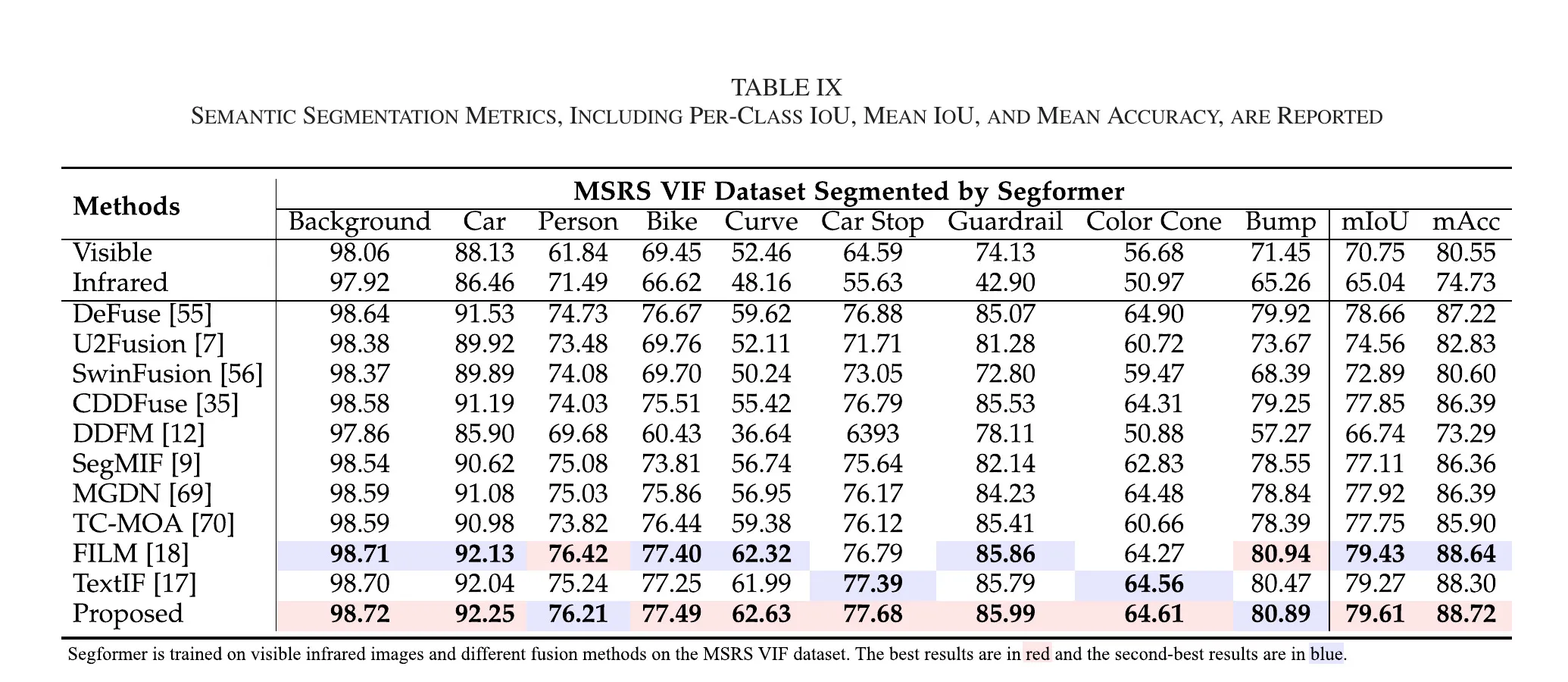
文中表格结果显示:Proposed 的 mIoU 为 79.61、mAcc 为 88.72,高于 FILM 79.43/88.64 与 TextIF 79.27/88.30。这说明语义增强的融合结果并非仅提升视觉观感,而是能够实质性提升语义任务表现。
5.4.3 目标检测

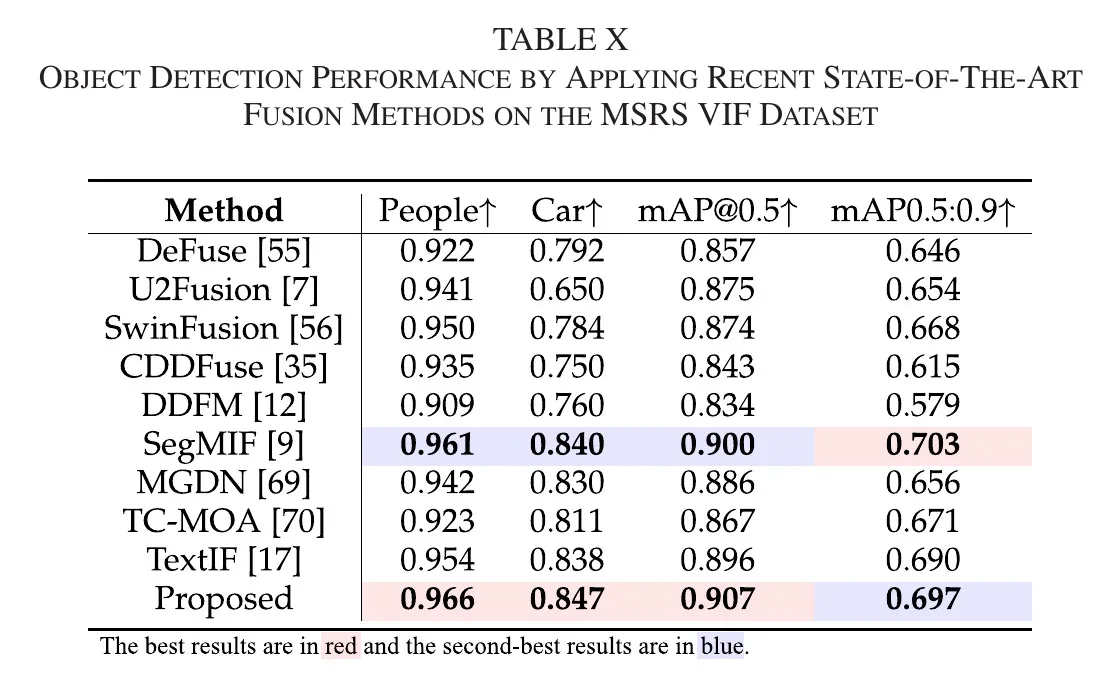
文中给出关键数值:Proposed 在 People 0.966、Car 0.847、mAP@0.5 0.907、mAP0.5:0.9 0.697。需要如实指出,SegMIF 在 mAP0.5:0.9 上为 0.703,高于 RWKVFusion。即 RWKVFusion 不是“所有检测指标绝对第一”,而是多数指标上的更优综合表现。
5.5 局限性与进一步思考
基于主文与结果呈现方式,可以归纳出以下边界条件:
- 上游语义链路误差传导:caption、检测框、掩码质量会直接影响融合效果;
- 主干高效不等于全链路高效:主文重点报告主干复杂度优势,但包含 Florence/DINO/SAM 的统一端到端时延,文中未给出/未报告;
- 小尺寸遥感训练块中弱化掩码分支:在 pansharpening 与 HMIF 中,因训练块尺寸较小,文中给出的尺寸为 64×64,实践上省略 mask,仅保留语言引导;
- 深度任务量化不完整:深度估计仅给出可视化,统一数值指标文中未给出/未报告。
这些限制并不削弱文中主结论,但提示后续方向应聚焦于:更轻量的语义生成链路、端到端系统级时延评估、任务自适应的语义注入策略,以及更完整的跨任务量化协议。
5.5.1 面向复现与改进的具体启示
如果以“可复现可扩展”为目标,这项工作给出的直接启示至少有三点。第一,语义分支应被视为可替换部件,而不是固定实现。主文证明了“语言 + 掩码”这类条件本身有效,但并未限定必须使用 Florence/DINO/SAM 这一组合,因此后续工作可以在不改动主干的前提下,用更轻量的语义生成器替换上游链路。第二,mask 不是越多越好,关键是质量控制。文中通过 merged 与 unmerged 对照已经说明,不受控的掩码输入会稀释语义收益,甚至向主干注入噪声。第三,融合研究不应只停留在融合指标,必须绑定下游任务检验。本文在检测和分割上的结果提示我们:真正高价值的融合表示,应该在“视觉可读性”和“机器可判别性”两端同时成立。
从研究方法论看,RWKVFusion 也提供了一个可迁移范式:先在任务定义层明确缺口,再在结构层给出针对性设计,最后用主结果、消融、下游三层证据闭环验证。这个范式对于后续多模态低层视觉任务,不仅限于图像融合,同样具有参考意义。
5.6 从输入到输出的一次完整前向
为系统梳理本文的方法逻辑,可沿一次前向传播完整追踪信息流。这样做的价值在于,不少解读停留在模块名词罗列,如 RWKV、MFM、mask,但未回答“这些模块在计算图中的时序作用与相互约束关系”。RWKVFusion 的设计恰恰依赖严格时序:语义先生成、再注入、再跨尺度传播、最后重建。
5.6.1 输入阶段 多模态图像与语义条件的并行准备
在输入端,图像模态 进入融合分支;caption 与 mask 进入语义分支。两条分支虽为并行结构,但并不独立:语义分支输出是后续编码层的必需条件,因此在系统上属于前置条件准备,而非可选附加通道。这个设计与许多把语义当作后验打分器的融合方法有本质区别。
需要强调,文中没有把语义条件定义成单一向量,而是拆分为文本条件 与空间条件 。这种拆分背后的假设是:全局语义一致性和局部目标定位是两个不同层面的约束,不能由单一信号替代。后续表 VII 的结果也验证了这一点:只用 caption 或只用 merged mask 都弱于二者联合。
5.6.2 编码阶段 语义条件在多尺度主干中的层内注入
进入编码端后,RWKVFusion 并非“先完成融合再叠加语义”,而是在每个编码层通过 MFM 执行条件注入。其关键效果是把语义约束从输出端前移到特征形成端,减少后期补偿式修正造成的信息损失。
更具体地说,MFM 在每层做三件事:
- 保留并重校准原始模态信息,避免语义引导导致低层纹理被过度抑制;
- 利用掩码路径在空间上强化对象响应,把“哪里重要”显式落到特征图上;
- 通过文本交替拼接给出全局语义方向,把“该保留何种语义关系”加入序列建模。
这三步存在先后依赖:先有图像主路径,掩码对其进行空间约束,文本再做全局语义调制。若把顺序打乱,低层信息与高层语义的耦合稳定性会下降,这也能解释为何简单 MLP 或双 cross-attention 替代不能达到默认 MFM 的效果。
5.6.3 核心算子阶段 BRWKV 负责“全局关系建模 + 线性代价”
在编码层内部,BRWKV 分为空间混合和通道混合两部分。空间混合阶段通过 WKV 聚合全局信息,通道混合阶段进行非线性重标定。该结构与 Transformer block 的功能映射相似,但实现机制不同:RWKV 不显式构造完整注意力矩阵,而是依赖衰减记忆与递推读取。
从任务角度看,这一点对图像融合非常关键。融合任务不是高层语义分类,而是像素级重建;输入常是高分辨率图像,token 长度大,显存和 FLOPs 都更敏感。
5.6.4 解码与重建阶段 语义不再重复注入的原因
主文中解码器不再继续注入 caption/mask,该设计具有明确针对性。解码器职责是将融合特征恢复到像素域并保留细节连续性;如果在该阶段继续强语义注入,容易把重建过程变成语义重写过程,导致纹理不自然或边缘伪影。
因此,语义主要在编码端“定向”,解码端主要“还原”。这是本文设计中一个容易忽略但非常重要的工程细节: 语义引导与图像重建分阶段治理,而不是在每个阶段都做同强度语义干预。
5.6.5 系统层视角 主干高效与全链路开销的关系
文中在主文中清晰给出了 BRWKV 主干的复杂度优势,并在遥感任务中给出参数/FLOPs 对比。但在系统层面仍应区分两件事:
- 主干前向开销,RWKVFusion 网络本体;
- 语义准备开销,Florence、DINO、SAM、T5。
前者文中报告充分,后者主文没有统一端到端时延统计。也就是说,“主干高效”这个结论是成立的,但“整链路总时延最优”在主文证据范围内尚不能直接推出。这一点在工程复现时尤其要注意。
5.7 证据链交叉验证
从研究设计角度,本文结论建立在三层证据的相互支撑上。
- 主实验层 Table II 至 Table V 证明方法在六类融合任务中的综合性能优势。
- 机制层 Table VI 至 Table VIII 说明收益来源于 BRWKV、ESS、MFM 与语义注入的结构协同,而非单一技巧。
- 迁移层 Fig.11 至 Fig.13 与 Table IX 至 Table X 验证融合结果可向分割与检测任务迁移。
三层证据共同指向同一判断 RWKVFusion 的改进具有可解释性、可复核性与跨任务可迁移性。即便在个别指标出现次优,整体证据链仍支持其方法有效性。
5.8 总结
RWKVFusion 的学术价值不在于“又一个融合网络”,而在于其把三个长期分离的问题放进了同一证据闭环:
- 在任务定义层面,用式(5)把语言与掩码变为融合前向条件;
- 在网络算子层面,用 BRWKV + ESS 构建线性主开销的全局建模路径;
- 在实证层面,用跨任务主实验、结构消融与下游验证证明收益来源。
进一步看,这篇工作真正值得借鉴的是方法论:先明确任务缺口,再给出结构设计,再用消融和下游任务建立因果与迁移证据。对后续研究而言,可延展方向包括:更轻量的语义生成链路、更完整的端到端时延评估、以及面向任务差异的自适应语义注入机制。
若将该工作置于近两年的融合研究脉络中考察,其关键贡献并不止于“语言引导”标签,而在于语义条件、主干效率与跨任务验证的同步落地。许多方法只在其中一维突出,而 RWKVFusion 的价值在于让三维同时成立并可复核。由此可见,评价重点不应停留在单一指标增量,而应落在研究设计是否形成可迁移、可解释、可工程化的完整闭环。该视角也有助于后续选题判断。
5.9 参考
- Cao Z.-H., Liang Y.-J., Deng L.-J., Vivone G., An Efficient Image Fusion Network Exploiting Unifying Language and Mask Guidance, IEEE TPAMI, 2025.
- 代码: https://github.com/294coder/RWKVFusion
06 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。
文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!