

【论文阅读 | Information Fusion 2025 | DAFusion:面向退化场景的红外与可见光图像融合网络】
[TOC]
01 论文信息
- 论文题目: A Degradation-Aware Guided Fusion Network for Infrared and Visible Image
- 论文作者: Xue Wang, Zheng Guan, Wenhua Qian, Jinde Cao, Runzhuo Ma, Cong Bi
- 发表单位:
- School of Information Science and Engineering, Yunnan University, Kunming, China
- School of Mathematics, Southeast University, Nanjing, China
- Department of Electrical and Electronic Engineering, The Hong Kong Polytechnic University, Hong Kong, China
- 发表会议\期刊: Information Fusion, Vol.118, 2025, Article 102931
- DOI:
10.1016/j.inffus.2025.102931 - 论文状态:Received 2024-09-16 · Revised 2024-12-31 · Accepted 2025-01-02 · Available online 2025-01-07
- 代码链接: https://github.com/wang-x-1997/DAFusion
02 论文主要贡献
DAFusion 的切入点在于:当红外与可见光源图伴随烟雾、低光照、低对比度及噪声时,融合模型的有效特征提纯与退化抑制机制。大多数现有方法默认输入图像是干净的,专注于跨模态互补;DAFusion 采用了更严格的设定——红外和可见光都可能已经受到退化影响,核心问题由传统的跨模态互补延伸为:如何在特征融合阶段抑制退化信息的梯次传播。
论文没有把退化处理成外挂增强任务,也没有引入显式退化标签,而是让网络先在表示空间里区分正常内容与退化扰动,并把这种感知直接引入融合决策。这种训练目标、融合机制与监督约束的闭环架构,构成了其在不同退化场景下表现一致性的基础。

基于以上设定,本文主要贡献体现于三个层面:一是构建了退化感知的表示学习机制,借助无配对高质量图像和 EMA 编码器,通过对比学习让当前输入的表示向量向高质量分布靠拢;二是设计了 CrFM 协同细化融合模块,使退化感知向量直接参与特征融合决策,而非仅作辅助监督信号;三是引入图像级显著性掩码 与特征级能量变化掩码 的联合约束,将融合输出的信息重心拉向源图中更可信的内容区域。实验验证覆盖了常规融合指标、退化场景模拟、目标检测、语义分割和 VIFB 外部基准,以检验退化鲁棒性能否转化为更可用的融合表示。
03 论文创新点
- 退化感知导向的融合定义:不再默认源图像是干净输入,而是假设所有源图像都不同程度受退化影响,并据此重新组织训练机制。
- 无配对高质量图像 + EMA 负样本的对比学习框架:利用冻结编码器从高质量图像中提取稳定正样本,再用 EMA 编码器生成动态负样本,驱动模型在表示空间中学习退化差异。
- CrFM 协同细化融合模块:利用表示特征与源特征之间的依赖关系,先做域内细化,再做跨域交互,使融合不只是简单拼接或加权。
- 图像级显著性掩码与特征级能量变化掩码联合约束:前者聚焦静态显著内容,后者跟踪退化重建动态过程中的高频恢复区域,两者联合优化特征解空间。
04 方法
4.1 方法总览
整套方法分两阶段训练,逻辑主轴可归纳为三步。
第一阶段:退化感知。 借助无配对高质量参考图像、预训练的固定编码器与 EMA 缓存编码器,在表示空间构建稳定锚点,驱动退化输入特征向量向高质量数据分布迁跃。此外,模型并非拟合具体的退化物理模型,而是建立泛化的度量边界,以分离高频细节与退化扰动。
第二阶段:退化导向融合。 全局表示特征不局限于辅助监督,而是作为 CrFM 模块的显式门控信号调控源分支特征。模态融合不仅补偿跨域特征,同时度量各局部通道响应的可信度。
双掩码约束。 图像级显著性掩码维持关键内容轮廓,而特征级能量变化掩码捕捉深浅层特征重建过程中的动态增量。静态选择与动态追踪的交织,引导融合重构收敛于更可靠的源图区域。
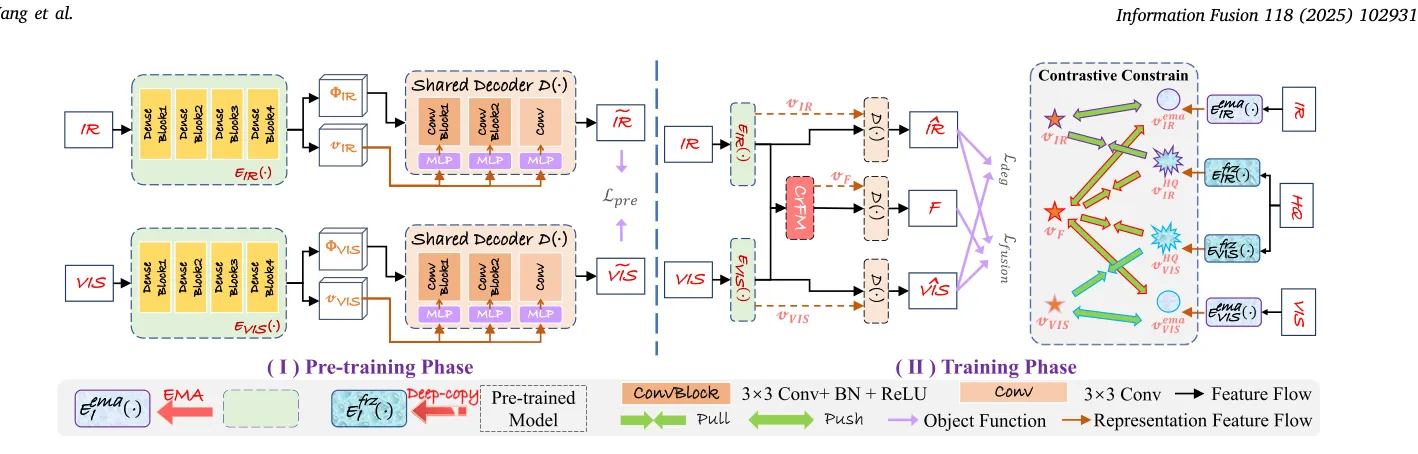
4.2 网络基础结构:编码器
编码器采用类 DenseNet 的密集连接结构,输入为单通道灰度图(红外或可见光亮度通道),共 4 个卷积块,每块均为 Conv2d(3×3) + BN + ReLU,输出通道数固定为 16。
输入: [B, 1, H, W]
E1 = Conv(1→16)(x) → [B, 16, H, W]E2 = Conv(16→16)(E1) → [B, 16, H, W]E3 = Conv(32→16)(cat[E2,E1])→ [B, 16, H, W] # 拼接前两层E4 = Conv(48→16)(cat[E3,E2,E1]) → [B, 16, H, W] # 拼接前三层
Ef = cat[E4, E3, E2, E1] → [B, 64, H, W] # 源特征(用于融合)emb = AdaptiveAvgPool2d(1)(Ef) → [B, 64, 1, 1] # 表示向量(用于退化感知)密集连接的核心价值:每一层都能看到所有前层的输出,底层纹理细节和高层语义表达同时保留在 64 通道的 Ef 中。emb 是对这 64 通道做全局平均池化后得到的 [B, 64, 1, 1] 向量,它是后续退化感知对比学习的载体,也是解码器 AdaIN 的风格来源,还是融合模块 CrFM 的门控信号。
对应代码(net.py: Encoder):
# net.py L7–46 class Encoder / Dual_Encoderclass Encoder(nn.Module): def __init__(self): super().__init__() self.con1 = nn.Sequential(nn.Conv2d(1, 16, 3, 1, 1), nn.BatchNorm2d(16), nn.ReLU()) self.con2 = nn.Sequential(nn.Conv2d(16, 16, 3, 1, 1), nn.BatchNorm2d(16), nn.ReLU()) self.con3 = nn.Sequential(nn.Conv2d(32, 16, 3, 1, 1), nn.BatchNorm2d(16), nn.ReLU()) self.con4 = nn.Sequential(nn.Conv2d(48, 16, 3, 1, 1), nn.BatchNorm2d(16), nn.ReLU()) self.mlp = nn.AdaptiveAvgPool2d(1)
def forward(self, x): E1 = self.con1(x) E2 = self.con2(E1) E3 = self.con3(torch.cat([E2, E1], 1)) E4 = self.con4(torch.cat([E3, E2, E1], 1)) Ef = torch.cat([E4, E3, E2, E1], 1) # [B, 64, H, W] emb = self.mlp(Ef) # [B, 64, 1, 1] return Ef, emb双分支编码器(Dual_Encoder)就是把两个独立的 Encoder 分别作用于红外图和可见光亮度图:
# net.py L48–57 class Dual_EncoderF_ir, emb_ir = encoder_ir (img_ir) # [B,64,H,W], [B,64,1,1]F_vis, emb_vis = encoder_vis(img_vis) # [B,64,H,W], [B,64,1,1]4.3 网络基础结构:解码器
解码器基于 AdaIN(Adaptive Instance Normalization)将表示向量 emb 作为风格信号注入重建过程。代码并非直接使用标准 AdaIN,而是设计了 Adain_module:先用 MLP 把 emb([B,64,1,1])映射成与当前特征图尺寸匹配的风格 tensor,经 AdaIN 调制后,再通过可学习混合系数 (初始化为 -0.8,经 Sigmoid 后初始值约 0.31)与原特征线性混合:
其中 ,随训练自适应调整风格信号的介入程度。
解码器共两个 Adain_module(64→32,32→16)加一个最终卷积输出(16→1),最终用 Tanh 激活后乘以 255 输出重建图:
# net.py L84–113 class Decoder_resclass Decoder_res(nn.Module): def forward(self, x, emb): x1 = self.decon1(x, emb) # Adain_module: 64→32 x2 = self.decon2(x1, emb) # Adain_module: 32→16 x3 = adain(x2, self.mlp(emb)) # 再做一次风格对齐 w = self.sig(self.w) # 混合系数 F = self.decon3(x3*w + x2*(1-w)) # Conv 16→1, Tanh return F * 255, [x1, x2, x3] # 同时返回中间层(用于能量变化掩码)解码器的 [x1, x2, x3] 是后续计算 必须用到的中间层响应,不是可选输出。
4.4 第一阶段:预训练
第一阶段只训练编码器 + 解码器,目标是先让网络在没有退化感知约束的情况下,学会稳定的特征提取和图像重建能力。损失函数为:
输入图同时作为目标,模型以自重建方式训练 20 个 epoch。仓库中保存的是预训练后的权重文件(model_CE_res_20.pth、model_CD_res_20.pth),第二阶段从这里加载继续训练,冻结编码器(model_CE)用于提取高质量正样本表示。
4.5 第二阶段:退化感知对比学习的完整流程
第二阶段是整套方法的核心。训练时同时需要三类输入:
imgA:红外退化输入,[B, 1, H, W]imgB:可见光退化输入(Y 通道),[B, 1, H, W]imgC:无配对高质量图像(从 SICE 等独立数据集取),[B, 1, H, W]
训练中一共存在四种编码器身份,每种身份承担不同角色:
| 编码器 | 身份 | 作用 |
|---|---|---|
model_CE | 冻结预训练编码器 | 提取高质量图像的稳定正样本表示 |
model_E_res | 主编码器(梯度可更新) | 提取退化输入的当前表示 ,是被优化的对象 |
model_E_res_ema | EMA 编码器(无梯度,慢速跟随) | 提取退化输入的历史表示 ,作为负样本 |
model_FNet_ema | EMA 融合模块 | 提供融合表示的慢速历史参照 |
一次完整的训练前向(对照 train.py)如下:
# train.py L145–197 def train() 核心前向# Step 1: 主编码器提取退化输入的源特征和表示F_ir, emb_ir, F_vis, emb_vis = model_E_res(imgA, imgB)
# Step 2: 冻结编码器提取高质量图像的表示(正样本)F_ir_c, emb_ir_c, F_vis_c, emb_vis_c = model_CE(imgC, imgC)
# Step 3: 解码器对退化输入做单模态重建,同时输出中间层响应IR, D_IR = model_D_res(F_ir, emb_ir) # IR: 重建红外, D_IR=[x1,x2,x3] 中间层VIS, D_VIS = model_D_res(F_vis, emb_vis) # VIS: 重建可见光, D_VIS=[x1,x2,x3]
# Step 4: 主编码器再对重建结果编码,得到"重建后的表示"(用于特征一致性损失)# train.py L159_, emb_ir_ir, _, emb_vis_vis = model_E_res(IR, VIS)
# Step 5: EMA 编码器对退化输入编码,得到慢速历史表示(对比学习负样本)# train.py L160 — 注意变量名带 _c 后缀,与 HQ 正样本 emb_ir_c 区分_, emb_ema_ir_c, _, emb_ema_vis_c = model_E_res_ema(imgA, imgB)
# Step 6: 融合模块接收两路特征和表示,输出融合特征和融合表示Fea, emb_F = model_FNet(F_ir, F_vis, [emb_ir, emb_vis])Fea_1, emb_F_1 = model_FNet_ema(F_ir, F_vis, [emb_ir, emb_vis]) # EMA 融合表示(负样本)
# Step 7: 解码器从融合特征生成最终融合图F, _ = model_D_res(Fea, emb_F)
# Step 8: 主编码器对融合图再编码,为融合表示退化感知损失提供"重建后版本"# train.py L169_, emb_ema_ir_F, _, emb_ema_vis_F = model_E_res(F, F)对重建结果重编码的动机(Step 4):
用于特征一致性损失的计算。要求源图输入表示 emb_ir 与重建图再次编码的表示 emb_ir_ir 高度一致,以此约束表示向量剥离退化差异,锚定稳定的场景内容信息。
EMA 编码器的更新机制:
每个迭代步后执行动量更新:
# train.py L39–41 def update_ema_variablesupdate_ema_variables(model_E_res, model_E_res_ema, alpha=0.9, global_step)# 等效于:ema_param = 0.9 * ema_param + 0.1 * paramEMA 编码器采用主网络权重的指数移动平均。这种缓变特性使其能够提供更为稳定的负样本锚点,消除主编码器梯度剧烈波动引发的表征坍塌。

4.6 CrFM:协同细化融合模块
CrFM(Collaborative Refinement Fusion Module)是融合的核心,分两步:CA 通道对齐细化和 SA 空间自适应交互。
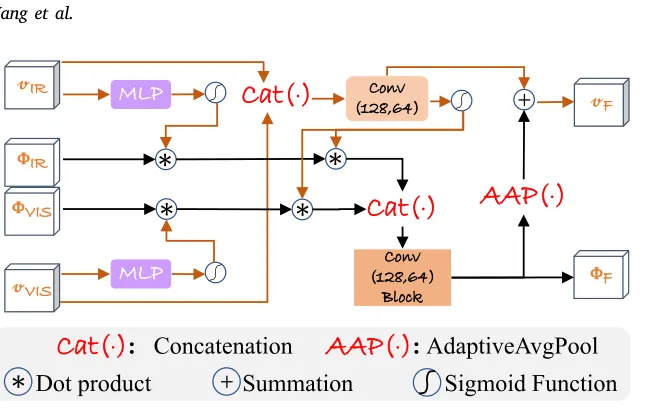
4.6.1 CA:通道对齐细化(Channel-level Alignment)
CA 用各自模态的表示向量 emb_ir / emb_vis 生成通道门控权重,对对应的源特征做逐通道缩放:
# net.py L152–157 Fusion_net.CA_attentiondef CA_attention(self, ir, vis, emb_ir, emb_vis): # emb_ir: [B, 64, 1, 1] → reshape → [B, 64] → fc → sigmoid → [B, 64] ir_atten = sigmoid(fc_ir(emb_ir.reshape(B, -1))) # [B, 64] vis_atten = sigmoid(fc_vis(emb_vis.reshape(B, -1))) # [B, 64]
# reshape 成 [B, 64, 1, 1] 后广播到 [B, 64, H, W] ir_refined = ir_atten.reshape(B, 64, 1, 1) * ir # [B, 64, H, W] vis_refined = vis_atten.reshape(B, 64, 1, 1) * vis # [B, 64, H, W] return ir_refined, vis_refined表示向量 emb_ir 由于受对比学习的拉拽,已显式编码了自身的退化状态。经由 FC + Sigmoid 非线性映射,输出通道门控权重。响应较强的通道得以保留,而受退化腐蚀较严重的通道将被衰减。此机制独立作用于各自模态,属于模态域内标定环节。
4.6.2 SA:空间自适应交互(Spatial Adaptive Interaction)
SA 先把两路表示拼合并压缩成一个融合表示 emb_f,再以此为门控完成跨模态特征交互:
# net.py L159–166 Fusion_net.SA_attentiondef SA_attention(self, ir, vis, emb_ir, emb_vis): # 拼接两路表示 → Conv 压回 64 通道 → 融合表示 emb_f = Conv_embf(cat([emb_ir, emb_vis], dim=1)) # [B,128,1,1]→[B,64,1,1] gate = sigmoid(emb_f) # [B, 64, 1, 1]
# 交叉门控:用一路的门控权重去缩放另一路的特征,再加上自身 SA_ir = vis * gate + ir # [B, 64, H, W] 可见光被门控后加到红外上 SA_vis = vis + ir * gate # [B, 64, H, W] 红外被门控后加到可见光上
# 拼接后卷积融合 f = Conv_f(cat([SA_ir, SA_vis], dim=1)) # [B,128,H,W]→[B,64,H,W]
# 融合表示 = 融合特征的全局池化 + 门控表示的残差 emb_ff = AvgPool(f) + emb_f # [B, 64, 1, 1] return f, emb_ff门控信号 gate 由两分支模态的全局表示向量投影而得,综合了全局的联合退化分布状态。gate 值较高的通道表明该层级上特征均具备较优的可信度。通过交叉门控乘法运算,实现双向的跨模态可信信息自适应注入。最终输出的特征 f 已完成基于退化感知约束的跨模态融合分配。
整个 CrFM 的数据流可以概括成:
emb_ir, emb_vis # 各自模态的退化感知向量 │ │ ▼ CA 模态内重标定 ▼[ir_refined] [vis_refined] \ / ──────── SA 跨模态交互 ──────── │ │ [f] [emb_ff] # 融合特征 + 融合表示4.7 损失函数
4.7.1 单模态退化感知损失
对红外和可见光各自计算,合计如下(以红外为例):
结构保持损失(要求退化输入与其重建结果结构一致):
其中 为 Haar 小波变换的高频子带,约束重建结果在结构和高频细节上与原图保持一致。
特征一致性损失(要求退化输入的表示与重建结果的表示对齐):
对比学习损失(拉近正样本,推远负样本):
代码中用 SimMaxLoss(拉近当前表示与高质量正样本 emb_ir_c)和 SimMinLoss(推远当前表示与 EMA 负样本 emb_ema_ir)实现:
# train.py L124–134 def loss_res# 参数说明:emb_ema → 实际传入 HQ 正样本(emb_ir_c)# emb_ema_F → 实际传入 EMA 历史负样本(emb_ema_ir_c)def loss_res(F, imgA, emb, emb_ema, emb_ir_ir, emb_ema_F): loss1 = wav_loss(imgA, F) + SSIMLoss(imgA, F) # 结构保持 loss2 = (torch.norm(emb - emb_ir_ir) # 特征一致性:当前表示 vs 重建后表示 + SimMaxLoss(emb, emb_ema) # 拉近正样本(emb_ema=emb_ir_c,HQ) + SimMinLoss(emb, emb_ema_F)) # 推远负样本(emb_ema_F=emb_ema_ir_c,EMA) return loss1/nom_bchw + loss2/nom_emb
# 实际调用(train.py L162):# loss_res(IR, imgA, emb_ir, emb_ir_c, emb_ir_ir, emb_ema_ir_c)# ↑当前表示 ↑HQ正样本 ↑重建后表示 ↑EMA负样本单模态总退化感知损失:
4.7.2 双掩码构造
图像级显著性掩码 (sqt 函数)
比较两路重建结果 IR 和 VIS 在各像素位置的局部响应强度,强就拿 1,弱就拿 0:
# net_utilis.py L262–279 def sqtdef sqt(F_ir, F_vis): F_1 = torch.sqrt((F_ir - F_ir.mean()) ** 2) # 各像素对均值的偏离量 F_2 = torch.sqrt((F_vis - F_vis.mean()) ** 2) g_ir = F_1.sum(dim=1, keepdim=True) / 64 # 通道平均 → [B,1,H,W] g_vi = F_2.sum(dim=1, keepdim=True) / 64 w1 = (g_ir > g_vi).int() # 红外响应更强的位置置 1 -> 权重给红外 w2 = (~(g_ir > g_vi)).int() return w1, w2特征级能量变化掩码 (en_w / en_ac 函数)
比较编码器深层特征(F_ir 的后 3/4 通道)与解码器中间层特征(D_IR 的三个中间层拼合)的通道平均响应差值:
# net_utilis.py L306–320 def en_ac / en_wdef en_ac(x, y): # x: 编码源特征 [B,64,H,W],取后48通道(分4组取后3组) F_1 = cat([split(x,4)[1], split(x,4)[2], split(x,4)[3]], dim=1) # [B,48,H,W] # y: 解码中间层列表 [x1,x2,x3],各自拼合 D_fea = cat([y[0], y[1], y[2]], dim=1) # [B, 32+16+16, H, W] g_ir = D_fea.sum(dim=1, keepdim=True) / c_d # 解码层平均响应 [B,1,H,W] g_vi = F_1.sum(dim=1, keepdim=True) / 48 # 编码层平均响应 [B,1,H,W] w1 = norm_1(g_ir - g_vi) # 差值越大,说明这里在重建过程中被调整越多 return w1论文公式定义为( 表示 sum-pooling,取编码器第 3-4 层减去解码器第 1-2 层):
联合权重
将两个掩码直接相加后归一化:
# train.py L171–174 双掩码联合权重计算wen_1, wen_2 = en_w([F_ir, F_vis], [D_IR, D_VIS]) # 特征级掩码w1, w2 = sqt(IR, VIS) # 图像级掩码w1 = norm_1(w1 + wen_1) # 归一化到 [0,1]w2 = norm_1(w2 + wen_2)4.7.3 融合保真损失
论文中的公式形式( 表示归一化, 表示逐元素乘):
代码实现中还额外加了全局结构约束(SSIM + 小波):
# train.py L178–179 融合保真损失 loss5loss5 = 0.7 * (wav_loss(IR, F) + SSIMLoss(IR, F) + wav_loss(VIS, F) + SSIMLoss(VIS, F)) / (b*c*h*w) \ + (torch.norm(w1 * F - w1 * IR, p=2) + torch.norm(w2 * F - w2 * VIS, p=2)) / (b*c*h*w)掩码 w1 权重高的位置(红外响应更强),融合结果应更接近重建红外 IR;w2 权重高的位置(可见光响应更强),融合结果应更接近重建可见光 VIS。
4.7.4 融合分支退化感知损失
融合表示 emb_F 也需要向高质量分布靠拢,对其施加和单模态同样形式的约束:
# train.py L176–177 融合分支退化感知损失 loss3 / loss4loss3 = loss_res_F(F, IR, emb_F, emb_ir_c, emb_ema_ir_F, emb_F_1)loss4 = loss_res_F(F, VIS, emb_F, emb_vis_c, emb_ema_vis_F, emb_F_1)其中 emb_F_1 来自 EMA 融合模块,作为融合表示的慢速历史负样本参照。
4.7.5 总损失
代码中五项损失的对应关系(train.py L181: loss = loss1 + loss2 + loss3 + loss4 + loss5):
| 代码变量 | 对应公式项 | 内容 |
|---|---|---|
loss1 | 红外单模态退化感知损失 | |
loss2 | 可见光单模态退化感知损失 | |
loss3 | (IR侧) | 融合表示对红外高质量分布的对比约束 |
loss4 | (VIS侧) | 融合表示对可见光高质量分布的对比约束 |
loss5 | 融合保真损失(双掩码加权重建 + 全局结构约束) |
只有主编码器 model_E_res 和融合模块 model_FNet 的参数参与反向传播(optimizer_E 和 optimizer_F),解码器在第二阶段权重冻结。
4.8 推理流程(一次完整前向)
推理时不需要高质量参照图,也没有 EMA 分支,只走三步:
# test.py L162–183 推理主循环# 注意 test.py 的变量命名与 train.py 相反:# imgB = load_image_IR(...) → 红外图# imgA = load_image_VIS(...) → 可见光 RGB 图# imgA_Y = RGB2Y(imgA) → 可见光亮度 Y 通道
imgB = load_image_IR(ir_path) # [1, 1, H, W],红外imgA = load_image_VIS(vis_path) # [1, 3, H, W],可见光 RGBimgA_Y = RGB2Y(imgA) # [1, 1, H, W],可见光亮度
with torch.no_grad(): # Step 1: 双分支编码 # model_E(第1参数→ir分支, 第2参数→vis分支) # test.py L178 实际传参:model_E(imgA_Y, imgB) # 即可见光Y通道 → ir分支,红外 → vis分支(命名与语义相反,是仓库的代码调用逆序问题) F_ir, emb_ir, F_vis, emb_vis = model_E(imgA_Y, imgB)
# Step 2: 融合模块(CrFM) F_fea, emb_F = model_F(F_ir, F_vis, [emb_ir, emb_vis])
# Step 3: 解码生成融合亮度图 F, _ = model_D(F_fea, emb_F) # [1, 1, H, W]
# Step 4: 将融合亮度回填到可见光原始色度通道 output_rgb = restore_color(F, imgA) # [1, 3, H, W]注意:融合只在亮度空间进行,最终颜色由原始可见光的 CbCr 通道通过 YCbCr→RGB 回填提供(test.py L181: restore_color)。这是现阶段主流红外可见光融合范式的通用策略,其局限性在于:当可见光源图色度信息本身发生严重退化畸形时,最终重建图像的真彩色度亦将同步受损。
05 实验分析
5.1 实验设置与评测协议
5.1.1 数据集与训练策略
论文使用了 FLIR、TNO、M3FD、MSRS、LLVIP 等经典数据集。其中:
- FLIR 用于训练与验证;
- TNO、M3FD、MSRS、LLVIP 用于测试;
- 高质量参考图像来自 SICE 提供的高质量 ground truth 图像。
这一点很关键。作者并没有从融合数据集本身找理想答案,而是借用了独立高质量图像集作为表示学习参照。这正好符合其无配对高质量图像训练设定。
训练上,作者采用两阶段训练:
- 编码器与解码器先预训练 20 个 epoch;
- 正式训练时再引入 CrFM 与退化感知损失;
- 使用 Adam 优化器,batch size 为 8,初始学习率 0.001。
此外,论文还把可见光图转到 YCbCr 空间,只融合亮度通道,最后再把原图色度恢复回融合图。这个设置与仓库 test.py 里的 RGB2Y 和 restore_color 是对得上的。
5.1.2 评测指标
论文使用的常规融合指标包括:
- EN
- AG
- SF
- SCD
- MI
- VIF
这些指标中:
- EN、AG、SF 更偏统计信息量和纹理强度;
- SCD、MI、VIF 更偏源图信息保留与视觉保真。
同时,作者还额外做了:
- 退化场景模拟评估
- VIFB 测试
- 目标检测
- 语义分割
此类多维验证范式的介入表明,模型的评估边界已从静态融合保真突破至对下游高层感知任务的支撑效能上。
5.2 主实验结果
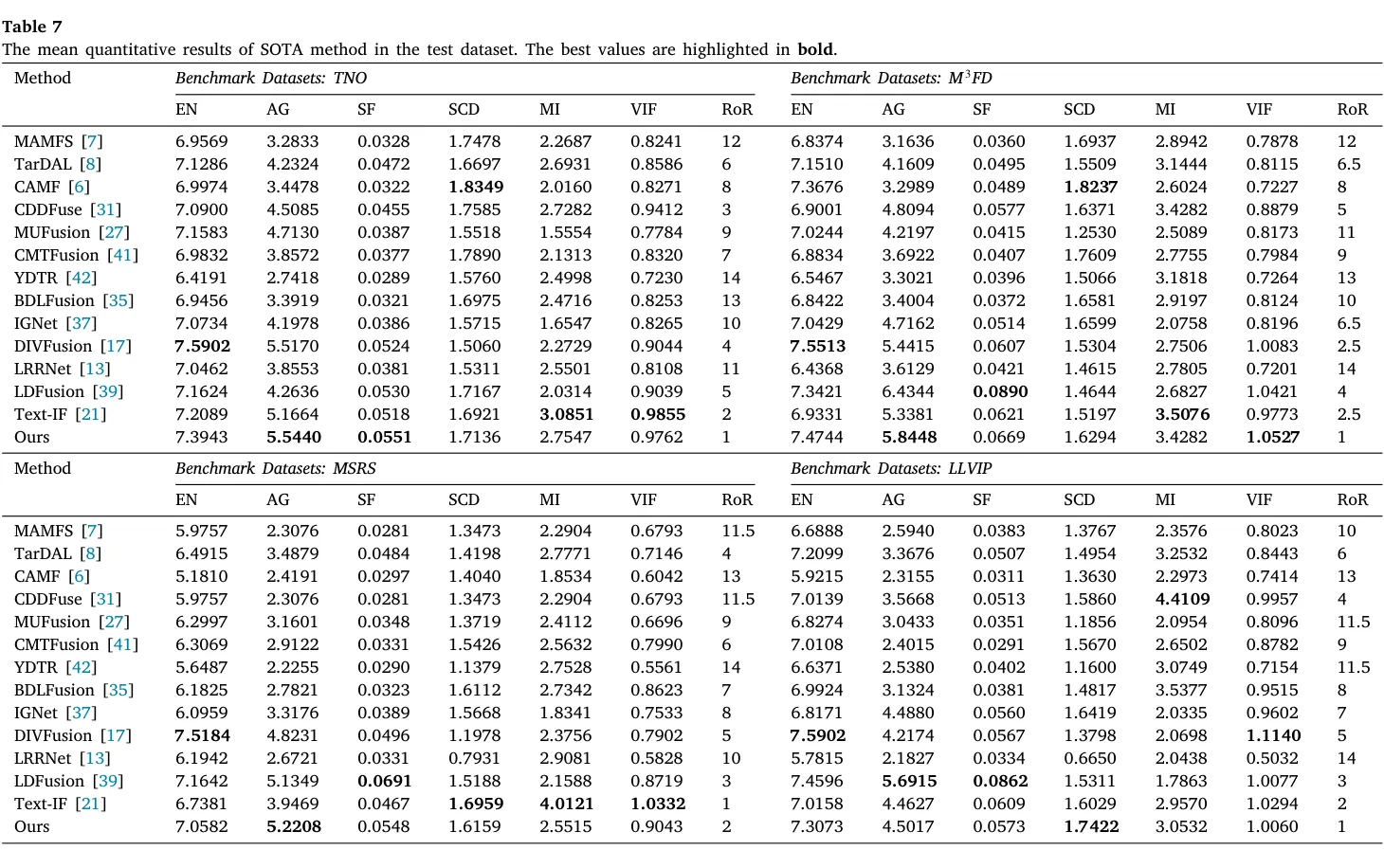
5.2.1 常规融合基准
DAFusion 的常规测试性能展现出显著的区间稳定性,而非针对特定局域指标的拟合冒尖。 在验证集上取得 MI = 3.4830、VIF = 0.8113、综合排名 RoR = 1。在此区间 MI 与 VIF 的同列高位,表明模型维持了接近原图互信息的有效表达,未引入过度强化的伪影纹理。
在 Table 7 的四个常规测试集上,DAFusion 在 M3FD 和 LLVIP 综合排名第一,MSRS 排第二,TNO 保持第一梯队,跨数据集波动小。尽管部分现有方法通过锐化局部梯度以推高 AG、SF 等统计参数,但这通常引发噪声失控及边缘极化,最终弱化高层特征语义。相比而言,DAFusion 将优势轴面收束于 MI、VIF 与 SCD 等侧重信息结构严谨性的综合性指标上,与退化免疫的初衷深度契合。
5.2.2 模型复杂度
论文 Table 6 给出,DAFusion 的参数量仅 0.2778M,FLOPs 为 8.24G。其利用极低参数量同步实现了退化感知、特征融合与解码生成,避免了级联恢复与融合网络的臃肿堆积。在面对真实退化场景部署时,这种运行开销是极为关键的实用级要求。
5.3 消融实验
消融实验对表示特征、CrFM、双掩码、特征一致性项、动态负样本分别进行了移除验证。从 Table 4 看,完整模型在六项指标上综合最优。其中影响最显著的是同时去掉 和 时的情形:EN 从 7.4674 降至 6.4611,AG 从 5.8342 降至 2.9313,VIF 从 0.8113 降至 0.5929,说明双掩码是稳住输出的关键约束,而非可选项。
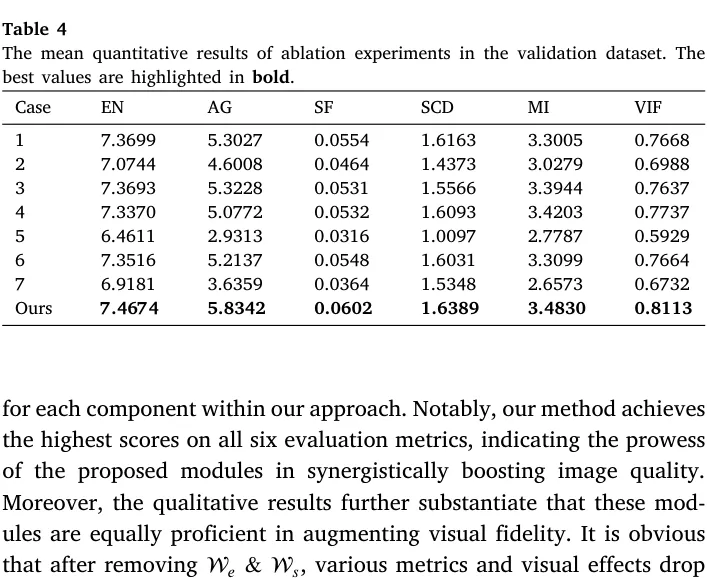
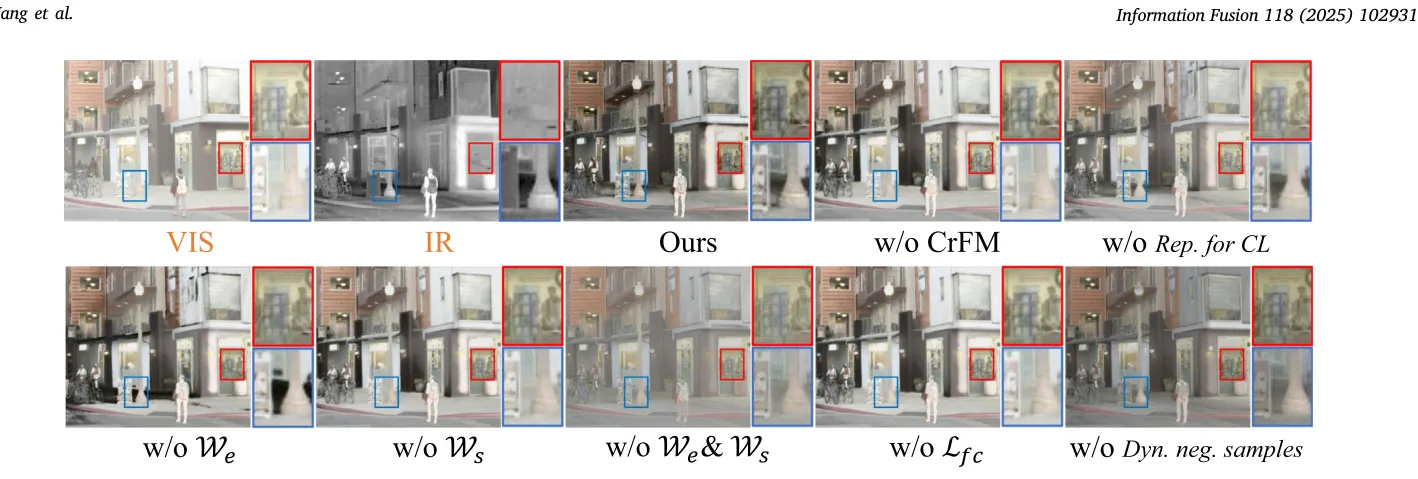
组件剥离消融揭示出三点内生机制:CrFM 的剔除导致全局表示特征断层,退化感知向空间聚合通道的传导受阻;抛弃对比约束导致性能显著滑落,反面证实全局尺度较像素层或局部特征层级更具承载退化度量的数学优势;双掩码的缺失使网络在退化空间易受伪显著性干扰,呈现为噪声压制力衰减及高频显著流失。各项微观组件交织构筑的机制级闭环共振,确保了架构鲁棒能力得以跨界延伸至下游泛化任务。
5.4 退化场景实验
5.4.1 退化场景的实验设计
退化合成实验构筑了校验其抗干扰命题闭环的最核心壁垒——考虑到两路源图可能同时伴随退化分布介入的情况,标准测试集的纯净先验并不适用,通过显式模拟复杂退化边界是必须的检测路径。
验证集所加载的 Smoke、Rain、Dark、Low-contrast、Noise 退化谱段,将对照组扩展为多模态网络配合专用图像恢复网络的(Restoration + Fusion)串联矩阵,DAFusion 常规登顶 RoR = 1,其抗退化假设的边界鲁棒性得到深度验证。

5.4.2 与 restoration + fusion 范式的比较
级联(Restoration + Fusion)范式的理论短板源自预处理层的单任务域过拟合偏重(例如:低光增强聚焦增益映射,去雨网络锚定条纹遮罩)。当面临复合叠加型或域位偏移型未知退化时,这类刚性先验极易引发性能坍塌。相比之下,DAFusion 的对比学习机制未引入显式的物理退化分类,而是利用高质量参考图构筑正交特征基。模型在迭代中剥离退化模式,其核心优化目标为泛化退化偏差的度量,而非拟合特定退化类型的局部纹理。
这一内生机制规避了网络对确定性退化类型的强依赖,大幅强化了模型在不确定扰动背景下的基准稳定性。
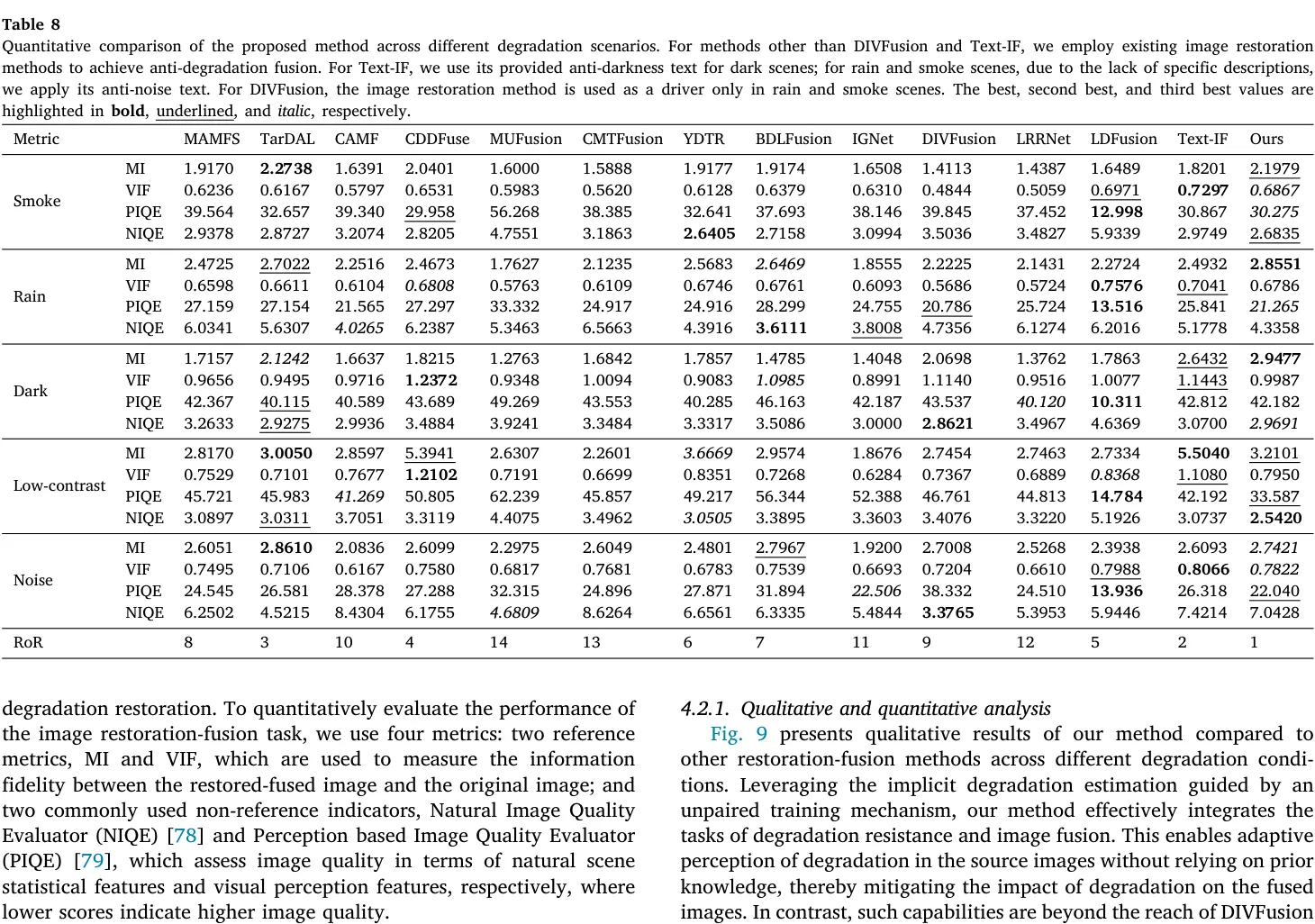
5.4.3 定量分析
Table 8 的核心价值凸显于多类退化基准上的全局矩阵抗性。取得综合 RoR = 1 且在有参考(MI、VIF 等)与无参考(PIQE、NIQE 等)质量评估层取得双向高位,证实系统攻克了去退化与空间分布频段保持上的拮抗约束。
在 Smoke 环境中,DAFusion 的 MI (2.1979) 联袂 NIQE (2.6835) 证实其在压制浓烟干扰的同时最大程度接纳了源序列熵信息。对于 Rain 测试域同样斩获 MI (2.8551) 等多项优异,彰显全局对比感知结构对高频雨滴遮罩及空间细节重构有着深度解耦算力;而在 Low-contrast 图像对中 (PIQE = 33.587, NIQE = 2.5420),更体现其基于底层对比度坍缩畸变的极强抗干扰解析度。面对 Noise 分布,模型继续稳定在高维区间,印证算法并不单纯规避照度相关退化。唯在 Dark 场景下,受限于现有研究阶段暂未介入色度域纠偏回归回路,极暗退化环境下仍会造成后期 RGB 指数映射色彩偏离,未能达成极限统御。
其根本规律为:DAFusion 凭借内部抗扰机制横穿五大退化测试频谱,均呈现稳定的前排位次,并非单一局域特定适配的偶然超越。
5.4.4 对比学习机制的验证
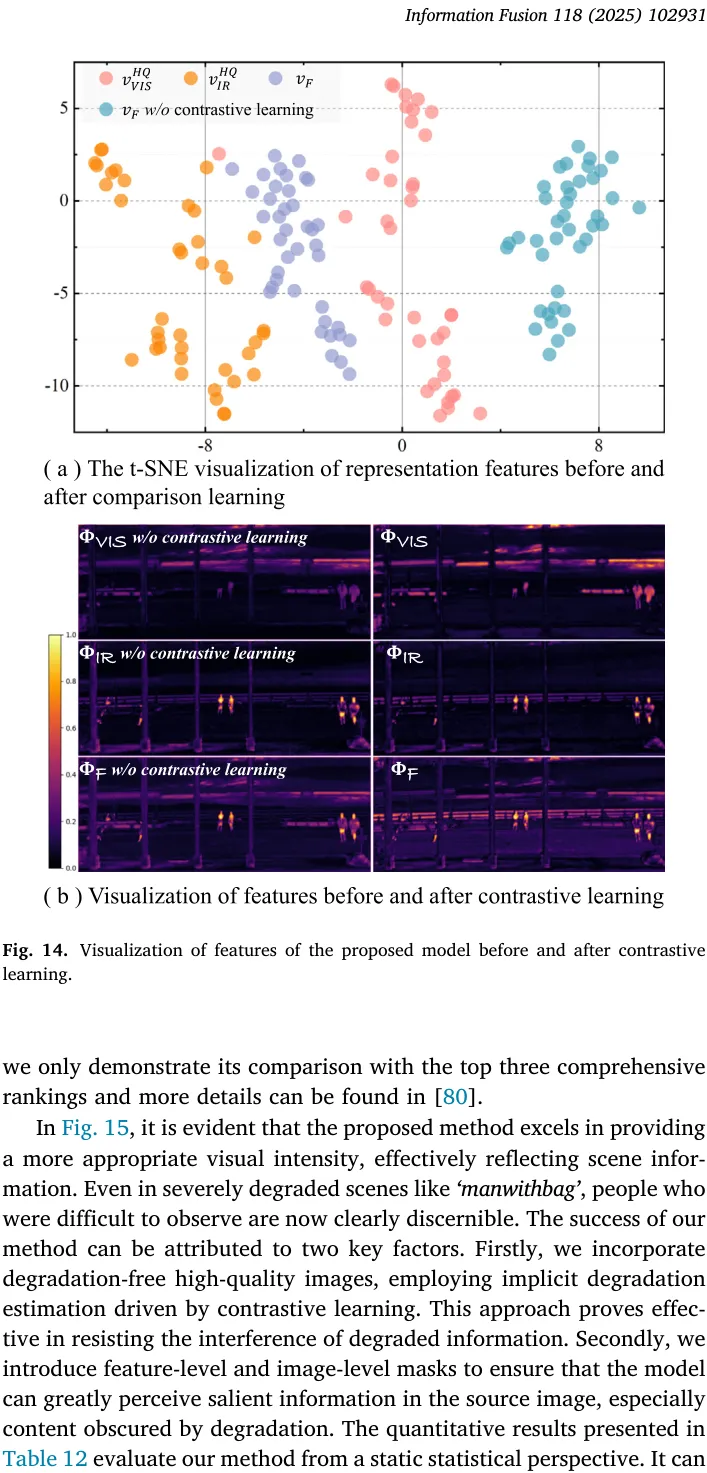
退化测试序列与 组件消融完成了前后闭环的交叉验证。剥离对比学习模块将导致架构在诸如低照度及强雨迹掩盖下诱发剧烈频谱震荡及纹理损失;辅以 t-SNE 高维空间投影显像,介入对比项后的融合表征向量确实在欧氏距离度量上紧贴高质量图谱中心。这从理论诠释层面为网络退化鲁棒性背书——无配对参考图导向的表征流型学习成为剥离底层退化特征的基石。
5.5 高层视觉任务与 VIFB 补充验证
5.5.1 目标检测
论文使用 YOLOv5 在 M3FD 和 LLVIP 两个数据集上做评测。DAFusion 在两个数据集上均取得综合排名 RoR = 1,退化感知的收益从融合图像层迁移到了下游检测层。
更具体地说,DAFusion 在两套数据上都拿到了 Precision 第一。在 M3FD 上,它取得 P = 0.886、mAP@0.5 = 0.821,其中 mAP@0.5 为全表最高,Precision 同样最高;但 mAP@[0.5:0.95] = 0.512 并不是第一。
在 LLVIP 上,它拿到 P = 0.986、mAP@0.5 = 0.986、mAP@[0.5:0.95] = 0.686,这三项都是最优。尤其是 mAP@[0.5:0.95] 这一项最难刷,它说明模型不是只在宽松阈值下把目标差不多框住,而是在更严格的 IoU 范围内仍然维持了很强的检测质量。
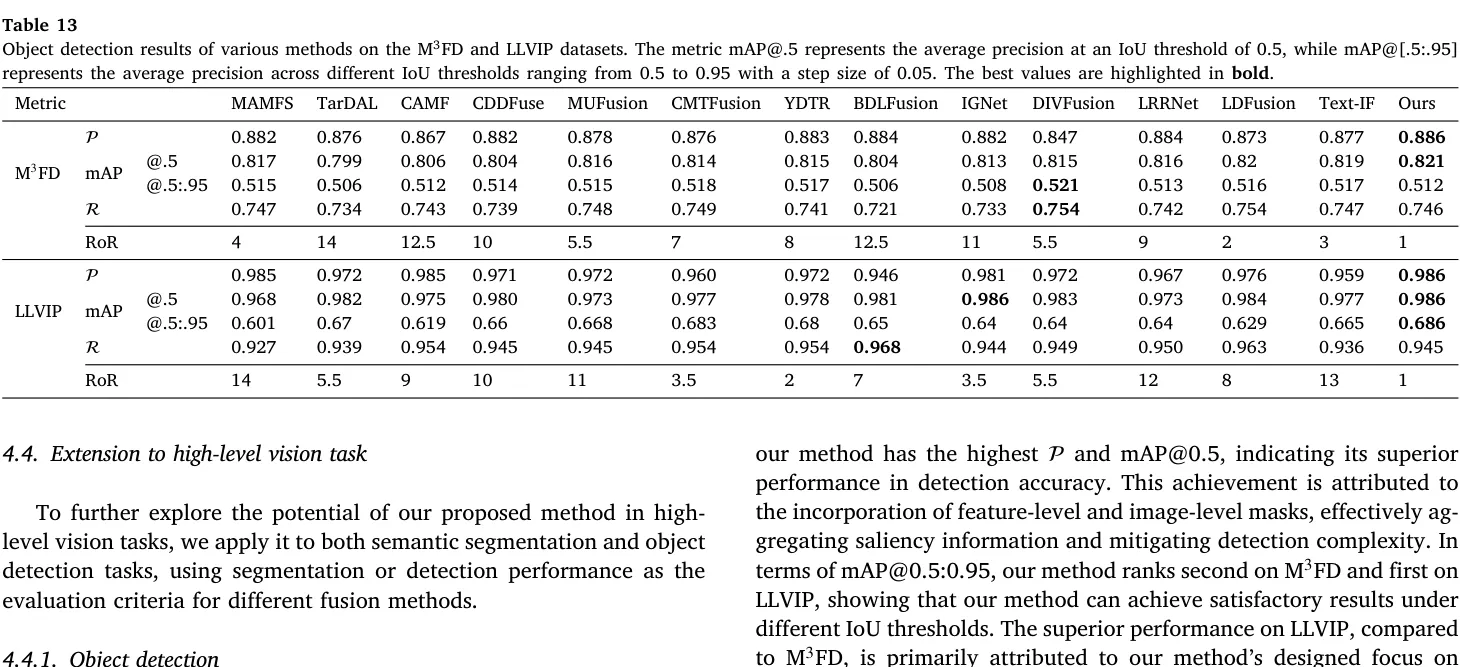

需要指出的是,在 M3FD 和 LLVIP 两个数据集上,最高 Recall 并不属于 DAFusion。这反映了其方法边界:双掩码机制在强调显著信息聚合的同时,可能使重叠显著区域的分离变得困难,带来一定的漏检风险,但这并未改变其整体检测性能(综合排名 RoR=1)的优势位置。
5.5.2 语义分割
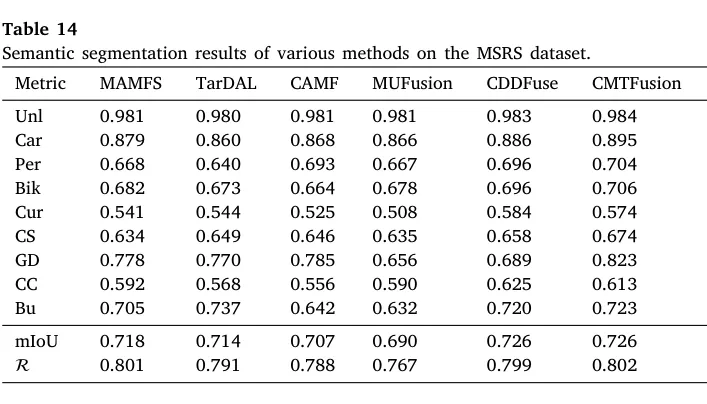
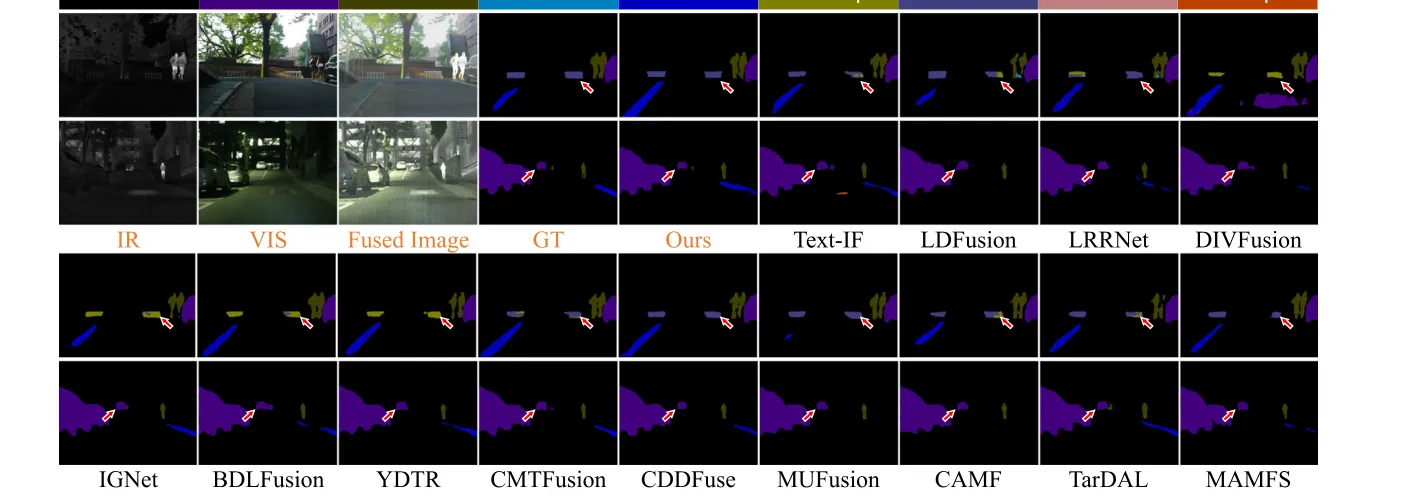
在 MSRS 上,DAFusion 的 mIoU = 0.727,这不是独占第一,而是并列最优。与此同时,它的 Recall = 0.809,是全表最高。mIoU 并列最优说明整体区域划分质量站到第一梯队,Recall 最高说明对可分割目标和场景区域的召回最充分。从 Table 14 看,各细分类别排名有起伏,优势并非来自某几个类别的偶然吃分,而是整体结构表达的一致性。
定性可视化(如车辆周边的 Person,白天场景的 Guardrail)表明,原本容易被退化掩盖或在融合中粘连的细节,在 DAFusion 的输出中能被更完整地保留下来,支撑了其整体结构表达更佳的推断。
5.5.3 VIFB 外部基准
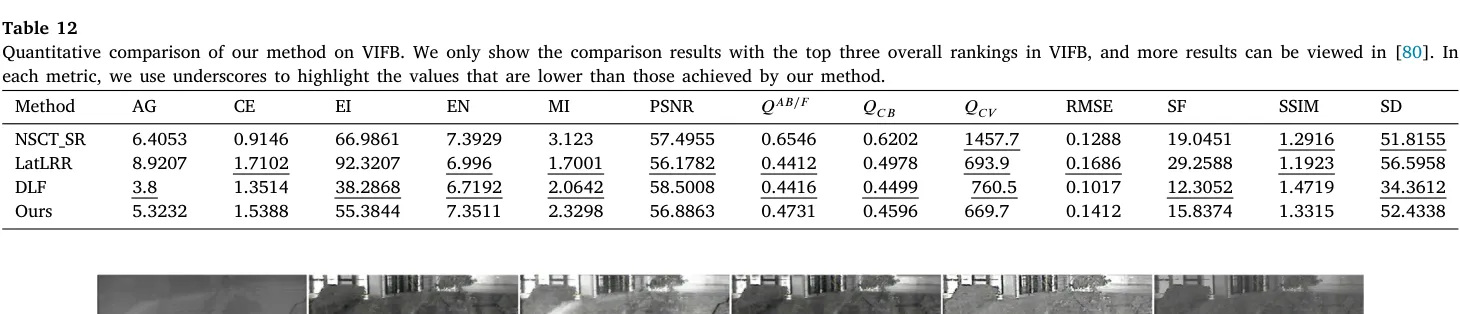
观测 Table 12 的输出指标集合,DAFusion 在 VIFB 拓展基准集中的有效性基线已建立,主要受益于 等代表视觉相干能力的评估项指标优势,客观上更为吻合人类视觉神经响应。与此同时,在其参数在 EN 等统计熵谱面维系强势的同时,唯独偏局部强度梯度的(如 AG、CE、SF)标量级序列未显统治地位。依据原作者论证:由于对比池体中大量级联融合流派依赖激化刻意边缘高频振幅等手段换取统计梯度,此类单项维度参标在极端失真下反而背离了网络重构的忠实初衷。
VIFB 作为独立于模型调配参数的盲评池介入并完成补充验证:确立了此前置推论并未陷入训练拟合的封闭锁铐中,这种跨域一致性能够安全平移。
5.6 证据结构总结
DAFusion 的验证体系由三层证据构成,各自回应不同层面的问题。
第一层,常规融合主实验(Table 7):方法在标准评价下的基准竞争力。跨数据集综合稳定,优势体现在 MI、VIF 等信息质量指标。
第二层,退化场景主证据(Table 8、Fig.9、Fig.14):方法主张是否被核心实验真正证明。输入已经退化时,融合表示能否仍向高质量分布方向收敛——这是全文最关键的证据层。
第三层,高层任务与外部基准(Table 13、14、12):收益能否迁移至下游任务和独立评测。
上述证据链结构表明,DAFusion 的核心学术价值不仅局限于通过特定模块实现单一榜单指标的攀升,而是自顶向下贯彻了”退化输入下融合特征免疫性”的破题思路。其通过主实验构建基准优势、退化合成实验映射内在机制、高层泛化任务校验域迁移能力的严密矩阵,完成了论证脉络的逻辑自洽。
5.7 参考
- Wang X., Guan Z., Qian W., Cao J., Ma R., Bi C., A Degradation-Aware Guided Fusion Network for Infrared and Visible Image, Information Fusion, Vol.118, 2025, Article 102931.
- 代码:https://github.com/wang-x-1997/DAFusion
06 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。
文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!