

【论文阅读 | arXiv 2026 | SLGNet:结构先验与语言引导调制协同的多模态目标检测框架】
[TOC]
01 论文信息
- 论文题目: SLGNet: Synergizing Structural Priors and Language-Guided Modulation for Multimodal Object Detection
- 论文作者: Xiantai Xiang, Guangyao Zhou, Zixiao Wen, Wenshuai Li, Ben Niu, Feng Wang, Lijia Huang, Qiantong Wang, Yuhan Liu, Zongxu Pan, Yuxin Hu
- 发表单位:
- Aerospace Information Research Institute, Chinese Academy of Sciences
- Key Laboratory of Target Cognition and Application Technology, Chinese Academy of Sciences
- University of Chinese Academy of Sciences
- Xi’an Jiaotong University
- 发表会议\期刊: arXiv preprint, 2026
- arXiv: https://arxiv.org/abs/2601.02249
- 代码链接: 暂未在论文首页与当前可见公开信息中确认到可信的官方开源仓库
02 论文主要贡献
2.1 关键判断
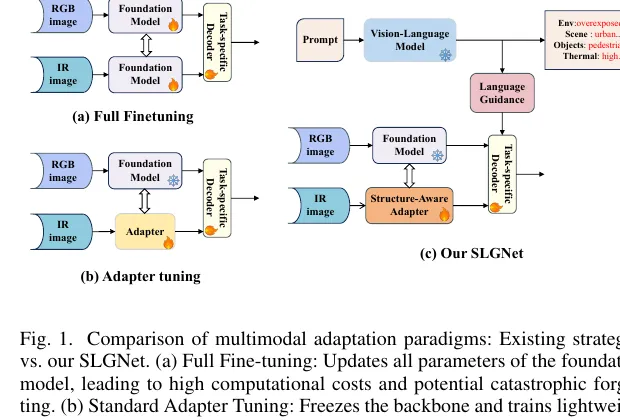
- 这篇工作本质上是 RGB-T 检测论文,不是图像融合论文。 它关注的是多模态目标检测里的参数高效迁移、结构保持和环境感知,不是先生成一张融合图再做下游任务。
- 作者抓得很准的痛点有两个。 一是冻结 ViT 后,普通 adapter 更偏语义迁移,容易把检测真正依赖的边缘、轮廓和局部几何信息弄丢;二是现有 RGB-T 融合策略大多是静态的,缺少对环境变化的显式感知。
- SLGNet 的核心不是简单堆两个模块,而是把两个问题拆开处理。 下支路用结构先验补几何细节,上支路用语言引导做环境感知调制,两条支路分工很清楚。
- 这篇文章最有价值的地方,是把 VLM 从“生成描述”变成“调制检测特征”的上层控制信号。 它不直接做 open-vocabulary detection,也不直接拿文本分类,而是把结构化 caption 转成通道级 affine modulation 参数。
- 从结果看,它确实不是只靠大模型包装概念。 LLVIP、FLIR、KAIST、DroneVehicle 四个数据集都有提升,而且参数量明显低于 full fine-tuning。
2.2 一句话概括
SLGNet 想做的事很直接。
冻结一个 RGB 预训练 ViT 主干,再额外挂两套轻量模块,一套专门补结构,一套专门看环境,最后把这台只会看 RGB 的大模型,改造成一个更适合 RGB-T 检测的多模态检测器。
03 论文创新点
- 提出双流参数高效适配框架。 在冻结 ViT 基础模型的前提下,把多模态适配拆成结构先验注入和语言引导调制两条路径,目标是同时兼顾精度、泛化和训练效率。
- 提出 Structure-Aware Adapter。 该模块通过 Structure Encoder 从 RGB 与红外中提取多尺度结构先验,再通过 Feature Fusion Adapter 注入到多级 ViT 表征里,显式补偿 patch 化和下采样导致的结构退化。
- 提出 Language-Guided Modulation。 作者先让 VLM 生成结构化 caption,再用 CLIP 文本编码器将其变成语义先验,最后通过通道级 affine modulation 对视觉特征做动态重标定。
- 在多个 RGB-T 检测基准上达到较强性能,同时保留较高参数效率。 论文报告 LLVIP mAP 达到 66.1,且相比 full fine-tuning 路线大幅减少可训练参数。
04 方法
4.1 方法总览
SLGNet 的总体结构可以概括成一句话。
冻结 ViT 主干,外接一个结构感知适配器和一个语言引导调制器。前者补结构,后者调环境。
作者给出的总览图其实已经把这个逻辑画得很清楚了。
完整框架如下图所示。底部黄色部分是 Structure-Aware Adapter,用来抽多尺度结构先验并注入 ViT;右侧绿色部分是 LGM,用结构化 caption 去调制最终视觉特征。
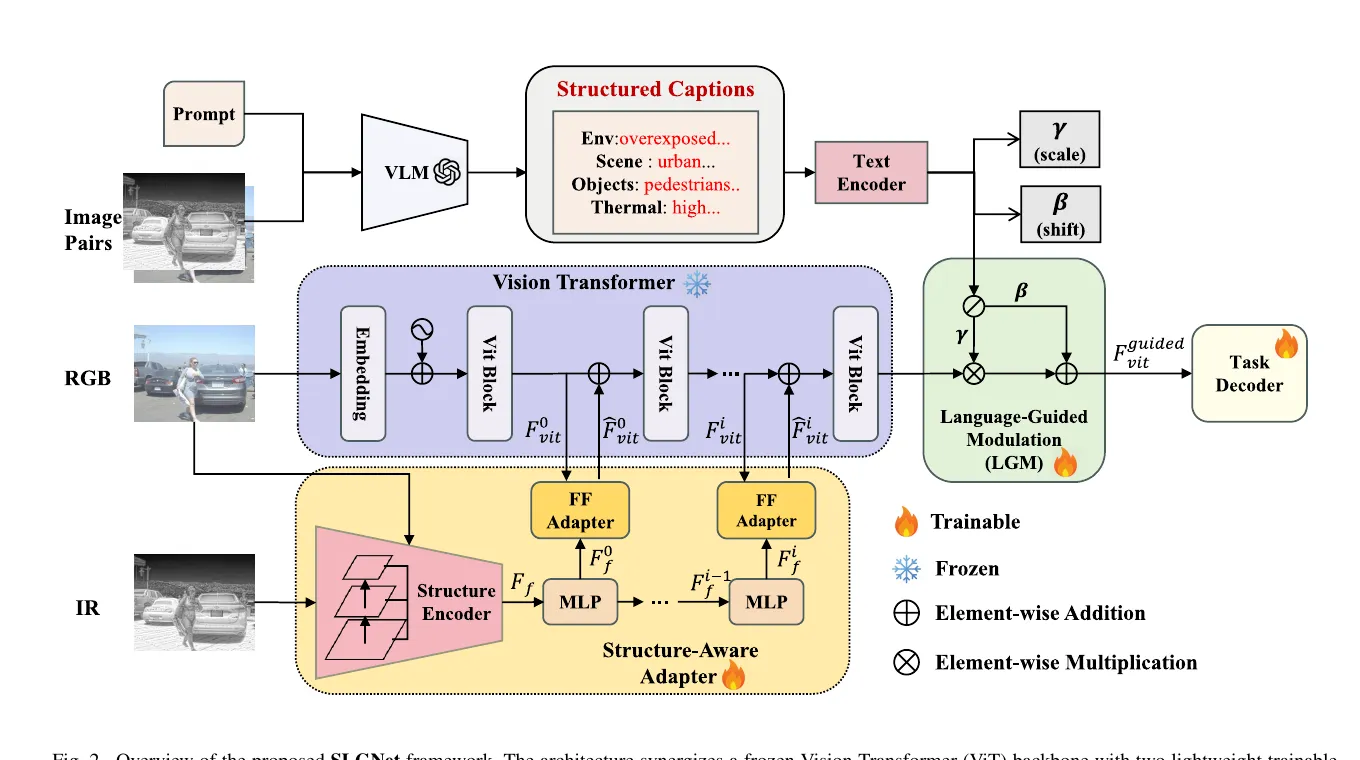
从前向流程看,RGB 图像进入冻结的 ViT backbone,被切成 patch token 并在多层 transformer block 中传播。由于 backbone 维持的是相对粗的空间分辨率,这会天然削弱检测任务依赖的边缘、轮廓和局部几何信息。为解决这个问题,作者从 RGB 与 IR 额外提取多尺度结构先验,并把这些先验通过 FF-Adapter 注回各级 ViT 表征中。
与此同时,作者又引入一条独立的语言支路。该支路不直接参与检测头,而是先让视觉语言模型为当前图像对生成结构化 caption,再将文本编码成语义特征,生成通道级缩放和偏置参数,对最终视觉特征做 affine modulation。于是整套系统的分工就很清楚了。
- 结构支路 负责几何恢复与跨模态结构一致性
- 语言支路 负责环境解释与动态重标定
这也是 SLGNet 和一般静态 RGB-T 融合框架最主要的差别。
4.2 参数高效迁移设定
论文采用的是冻结 backbone、只训练轻量模块的 adapter tuning 范式。设模型参数被拆成两部分:
其中 表示冻结的 ViT 主干参数, 对应结构适配与语言调制模块参数。训练目标写为:
这个设定本身不新,但它在全文里非常关键。因为作者真正想证明的不是 adapter tuning 能不能做 RGB-T 检测,而是:只要注入的信息足够针对任务,冻结式迁移同样可以兼顾效率和性能。
4.3 Structure-Aware Adapter
结构感知适配器由两部分组成:
- Structure Encoder
- Feature Fusion Adapter
前者负责从 RGB 与红外中提结构,后者负责把结构注回 ViT。
4.3.1 Structure Encoder
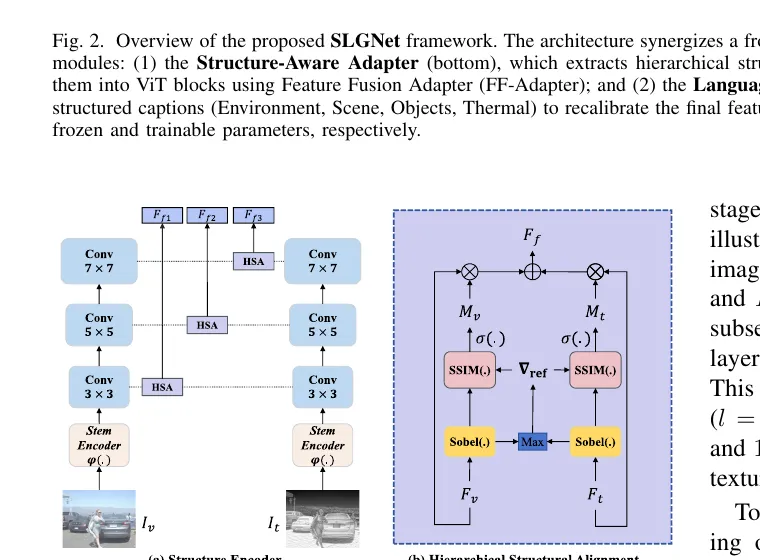
Structure Encoder 的目标,是从两个模态中恢复对目标检测有价值的层次化几何信息。给定 RGB 图像 与红外图像 ,作者先通过共享 stem encoder 提取初始特征,再通过三个卷积阶段得到三层结构特征 与 ,其中 ,分别对应大约 、 与 尺度。
更关键的是它后面的 Hierarchical Structural Alignment。对于每个尺度 ,先分别用 Sobel 算子提取两模态的边缘响应:
再用逐元素最大值得到参考结构图:
随后,论文用 SSIM 风格的结构一致性去计算两模态相对参考图的可靠程度,并将其归一化为自适应权重,最终得到融合结构特征:
这一步的意思并不复杂。
作者不是预设 RGB 更可信,或者红外更可信,而是每个尺度下都根据结构一致性,动态决定谁在这一层贡献更多结构信息。
下图就是 Structure Encoder 和 HSA 模块的细化结构。
4.3.2 Feature Fusion Adapter
如果说 Structure Encoder 负责提结构,那 FF-Adapter 负责把结构注回 ViT。论文这里没有采用简单加法或逐层拼接,而是借鉴 deformable attention 的思想,为每个 ViT stage 设计了面向多尺度结构先验的稀疏注意力注入方式:
进一步写成:
这里真正重要的一点是:FF-Adapter 并不是把整张结构图一股脑广播到 token 上,而是让 token 只去稀疏采样最有信息量的结构位置。 这让注入过程既保住了多尺度几何约束,又不会像密集对齐那样额外拖垮计算量。
此外,作者还用 MLP 让结构特征随着 ViT 层级逐步演化:
这意味着结构先验不是静态外挂,而是跟着 backbone 的语义层级一起变化。
4.4 Language-Guided Modulation
LGM 的目标,是让模型在多模态融合时拥有显式的环境理解能力。这里的重点不是把文本作为额外提示 token 塞进 ViT,而是先让视觉语言模型把场景翻译成结构化语言描述,再用这些语言先验去调制视觉特征。
具体地,给定 RGB 与红外图像对 ,作者先使用 Qwen2.5-VL 生成结构化 caption。该 caption 被拆成四类上下文成分:
- Environmental Context,描述光照与天气等整体环境条件
- Scene Type,描述室内外或功能区域等场景属性
- Object Density,描述关键目标的分布密度
- Thermal Signature,描述热对比和温度变化特征
随后,作者使用冻结的 CLIP 文本编码器 将四类文本分别编码为语义特征:
再通过拼接和轻量 MLP 投影,得到融合后的语义先验:
接着对文本 token 做池化,并通过两个投影头生成通道级缩放和偏置参数:
最后对 ViT 输出特征做 affine modulation:
这个模块最有意思的点在于,它给了模型一个高层场景解释接口。传统视觉注意力虽然也能学到某种模态重权,但通常只是从视觉统计中隐式推断环境变化;LGM 则试图先由 VLM 明确判断当前是低光、过曝、目标稠密还是热对比显著,再把这种解释过的环境信息写回视觉通道权重。
换句话说,它在网络里承担的是一种环境感知式特征重标定器,而不是普通的文本增强模块。
05 实验分析
5.1 数据集与训练设定
作者在四个数据集上验证方法。
- LLVIP 主要强调低照场景下的 RGB-T 行人检测
- FLIR 更偏复杂户外驾驶环境,背景杂乱、尺度变化大
- KAIST 是经典 RGB-T 行人检测基准,模态间存在空间不对齐问题
- DroneVehicle 是无人机俯视场景,目标小、密度高、方向变化大
指标方面,LLVIP、FLIR 与 DroneVehicle 主要看 mAP;KAIST 用的是行人检测里常见的 MR-2,越低越好。
实现上,作者采用 ViT-Base + DINOv2 作为 backbone,Structure-Aware Adapter 插在 12 个 transformer blocks 前。训练 50 个 epoch,batch size 为 8,优化器使用 AdamW,初始学习率为 ,并使用 layer-wise learning rate decay 和 AMP。
这里有个很关键的工程判断。
作者并没有把 VLM 作为在线实时推理的一部分。 论文明确说,VLM 生成场景上下文的部分是离线完成的。也就是说,它更像一种低频更新的上层语义控制信号,而实时检测主链路仍然由视觉 backbone 与 adapter 完成。这一点其实很现实,不然 VLM 推理开销会把部署价值直接冲掉。
5.2 LLVIP 与 FLIR 结果
先看 LLVIP 和 FLIR。
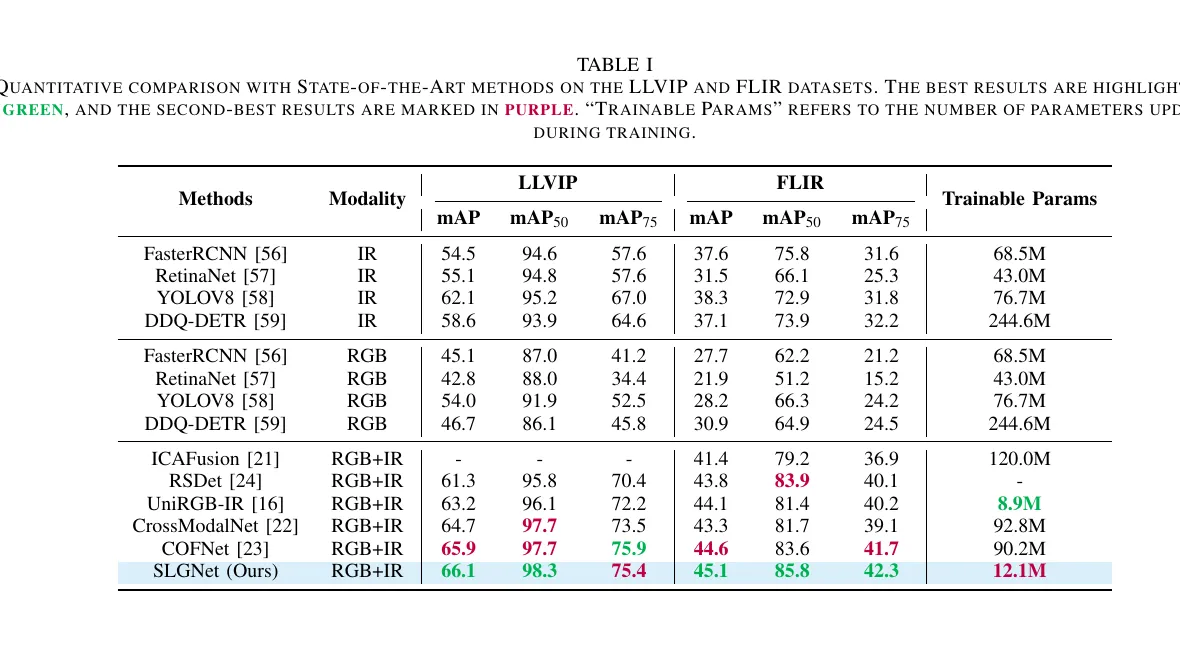
从表 1 可以直接看出几个结论。
第一,SLGNet 在 LLVIP 上确实很强。 它拿到 66.1 mAP、98.3 mAP50、75.4 mAP75。相比普通多模态方法 COFNet,mAP 略高,mAP50 也更高。更关键的是,SLGNet 只训练 12.1M 参数,而 COFNet 是 90.2M。
第二,FLIR 上的提升更能说明方法泛化性。 LLVIP 本身就是低照优势明显的数据集,热红外收益很容易体现;但 FLIR 场景更杂,背景噪声更重,尺度变化也更大。SLGNet 在这里依然拿到 45.1 mAP、85.8 mAP50、42.3 mAP75,说明它不只是吃夜间场景红利。
第三,结构支路和语言支路的配合在这两套数据上的逻辑是成立的。 在 LLVIP 这类极暗环境下,结构感知分支能用热红外边缘补回 RGB 看不见的几何细节;而 LGM 则进一步抑制 RGB 中被低照污染的无效信息。到了 FLIR 这种复杂街景,结构先验负责小目标和遮挡边界,语言支路负责根据环境上下文调模态权重。
5.3 KAIST 结果
KAIST 更能测试方法在模态错位和昼夜变化下的稳健性。
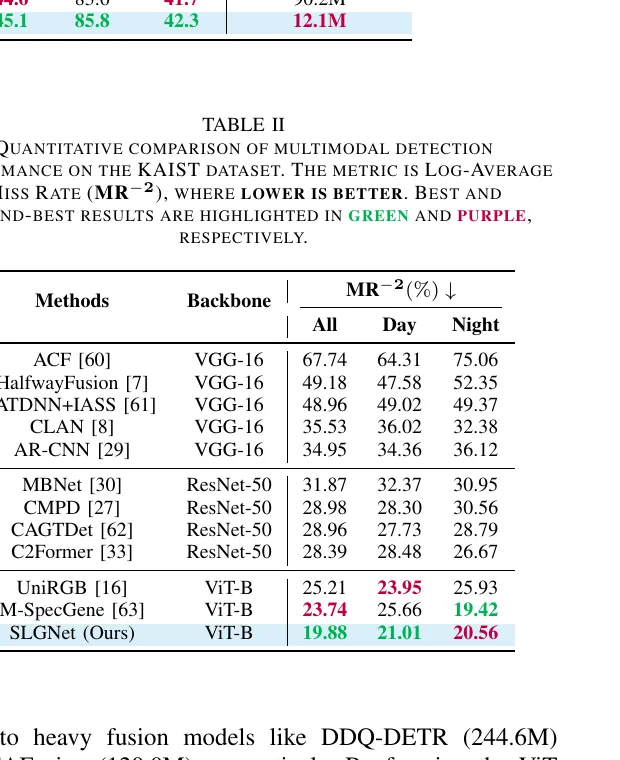
SLGNet 的 overall MR-2 是 19.88,明显优于 ResNet 系列方法,也优于不少现有 ViT 系方法。这个结果说明一件事。
结构先验注入并不是只在“模态完全对齐”时才有意义。 即便 RGB 与 IR 存在空间错位,只要高层 token 还能通过稀疏结构采样抓住更稳的边界信息,它仍然能对检测有帮助。
不过论文也给了一个很诚实的现象。夜间指标上,M-SpecGene 的 night MR-2 是 19.42,略优于 SLGNet 的 20.56。但 SLGNet 在 day 指标上更强,所以总体更平衡。换句话说,SLGNet 不是把某一个工况卷到极致,而是尽量让结构补偿和语言调制在不同工况下都稳定发挥作用。
5.4 DroneVehicle 结果
DroneVehicle 是这篇文章里我觉得最能体现结构支路价值的数据集。因为它是俯视视角,小目标密、排列挤、背景纹理杂,单靠粗分辨率 token 很容易把车群糊成一片。
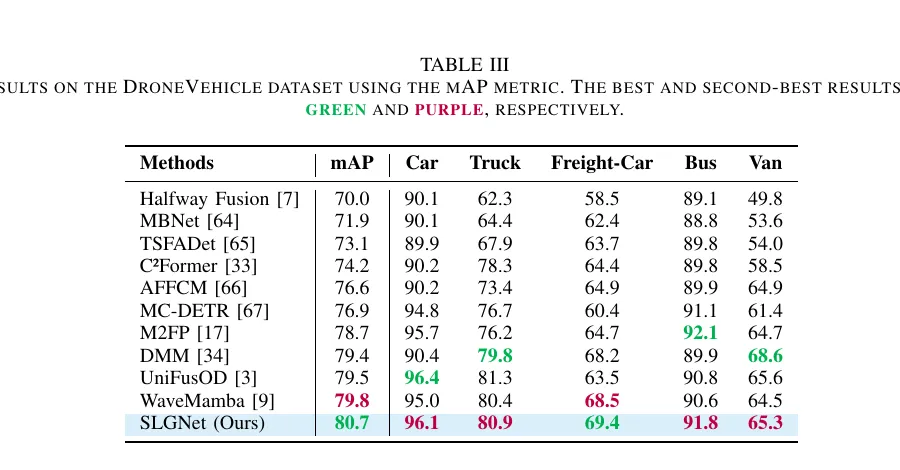
SLGNet 在 DroneVehicle 上达到 80.7 mAP,超过 WaveMamba、UniFusOD 等强基线。类别层面上,作者特别强调 Freight-Car 类别提升明显,这很符合方法直觉。因为货车本身轮廓更长、更规则、热特征也更明显,结构感知适配器更容易从中抽到稳定的几何先验。
但这篇文章也不是完全没有短板。论文里提到在 Van 类别上,SLGNet 仍略逊于 DMM。这也很好理解。Van 的外形在俯视图里常常介于 passenger car 和 truck 之间,不像货车那样有特别清晰的长形结构边界。这时,过于强调显式结构的模型,反而未必总比更自由的特征交互方式占优。
定性结果也能说明这一点。

从图 6 可以看出,SLGNet 在密集小车、相邻目标分离和夜间局部区域定位上明显更稳。尤其是蓝框放大的区域,基线方法会漏掉紧挨着的小目标,SLGNet 则更容易把它们单独分开。
5.5 组件消融
作者先做了最核心的组件消融。
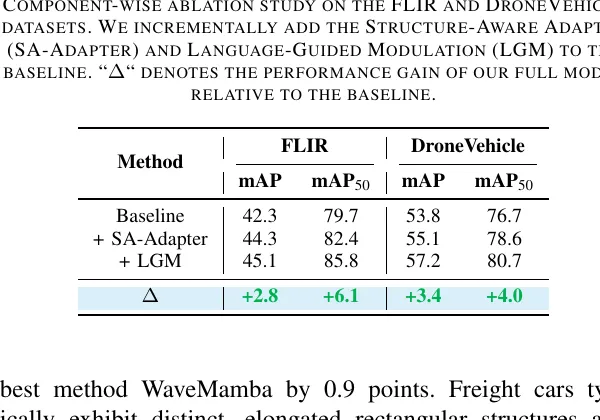
这个表非常重要。因为它回答了一个最直接的问题。
SLGNet 的收益,到底是结构模块带来的,还是语言模块带来的,还是纯粹因为多堆了点东西。
结果很清楚。
- 只加 SA-Adapter,FLIR 从 42.3 提到 44.3,DroneVehicle 从 53.8 提到 55.1
- 再加 LGM,FLIR 到 45.1,DroneVehicle 到 57.2
这说明两件事。
第一,结构支路是主增益来源之一。 只要把结构信息稳稳注回冻结 ViT,检测性能就会明显涨。
第二,语言支路不是摆设。 它在已有结构恢复的前提下,继续提供额外收益,说明显式环境上下文的确能帮助模态重标定,尤其在复杂背景或热对比变化较大的场景中更明显。
5.6 参数效率与训练稳定性
这篇文章另一个卖点,是它不是只在涨点,还在省参数。
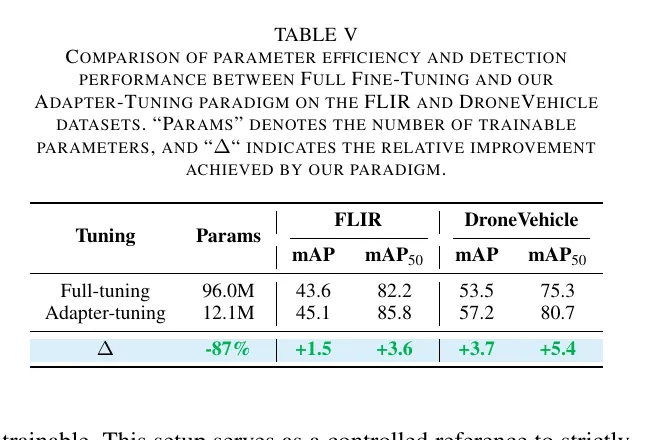
从表 5 看,adapter-tuning 的可训练参数从 96.0M 降到 12.1M,大约减少 87%。但在 FLIR 和 DroneVehicle 上,性能反而都超过 full fine-tuning。
这点挺有意思。
按直觉,full fine-tuning 应该更自由,也更容易涨点。但在 RGB-T 这种数据规模没那么夸张、场景分布又有偏移的任务里,大模型全量微调反而更容易把预训练的泛化能力弄乱。SLGNet 通过冻结 backbone、只训练轻量适配器,等于是把优化空间约束住了,反而更稳。
训练曲线也支持这个判断。
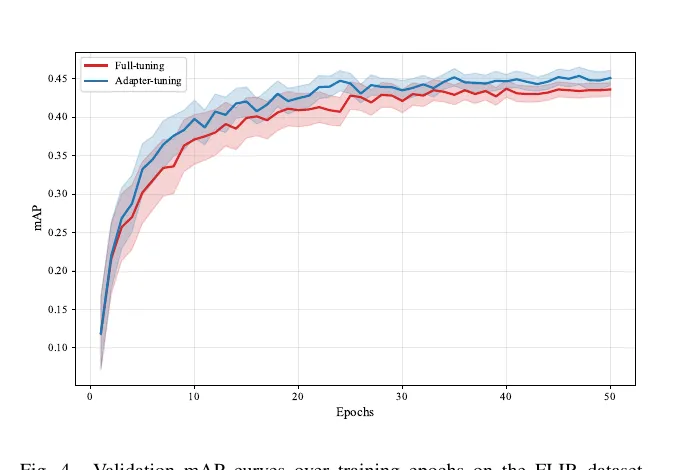
图 4 里,adapter-tuning 的蓝线更快进入稳定区间,阴影带也更窄。这意味着它不仅省参数,还更容易训稳。
5.7 结构可解释性
作者还给了一个我很喜欢的可视化。
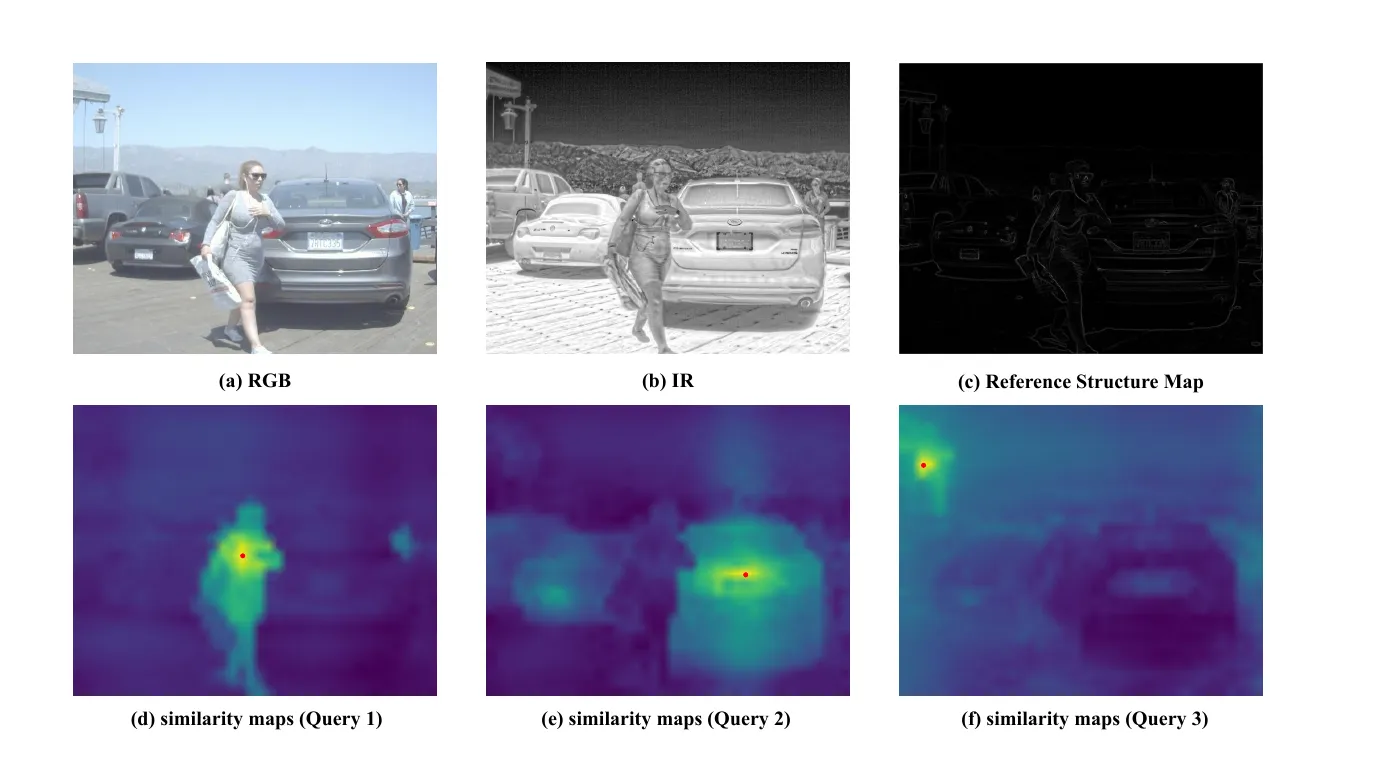
图 5 最有意思的地方,不是 pedestrian 或 car 的高响应,而是那个未标注的路灯杆。论文里专门提到,查询点放在路灯杆上时,SA-Adapter 仍能把整个杆状结构激活出来。
这说明一个很关键的现象。
结构支路学到的不是“检测类别模板”,而是更通用的几何结构先验。 这恰好符合它的设计目标。它不是替检测头去分类,而是尽量把本来会在 ViT 里被削弱的几何组织重新拉回来。
5.8 文本编码器与 prompt 设计
作者还比较了不同文本编码器和不同 prompt 组织方式。
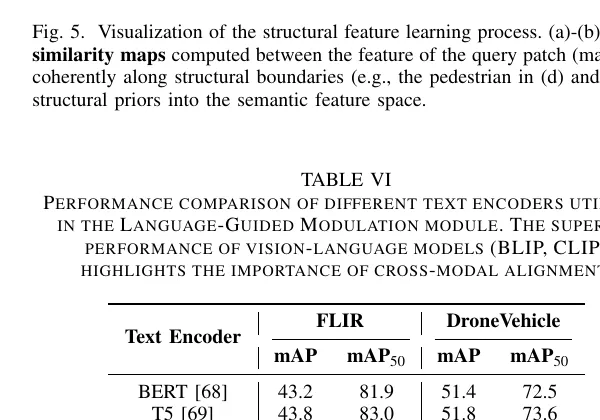
表 6 的结论很直接。
纯 NLP 编码器不如视觉语言预训练得到的 CLIP。 这很合理。因为 LGM 最终要去调制视觉 backbone 的通道特征,如果文本特征空间本来就和视觉特征没对齐,那 modulation 参数就更像额外噪声。CLIP 之所以更有效,是因为它天生就在 image-text 对齐空间里训练过。
再看 prompt 设计。

这里最值得注意的点是,只把类别名拼成一句 prompt,甚至比不加 LGM 还差。 这说明语言支路要有用,前提不是有文本就行,而是文本里必须包含能帮助模态重标定的环境信息,比如低光、过曝、热对比、场景类型、目标稠密度这些东西。
所以作者强调 structured caption,是说得通的。它不是为了把 prompt 写得更花,而是为了让语言支路拿到真正能指导融合策略的高层上下文。
5.9 小结与边界
这篇文章最聪明的地方,是它没有把问题说得太玄。
它承认冻结式 ViT 在 RGB-T 检测里会丢结构,也承认静态融合很难显式理解环境变化。于是作者没有去发明一个更大的多模态 backbone,而是把问题拆成两个很具体的补丁:一个补结构退化,一个补环境感知缺失。这种拆法很工程,也确实有效。
不过这篇文章也有几个边界需要一起看。第一,它本质上还是 RGB-T 检测方法,不是图像融合方法;如果任务目标是先生成高质量融合图,再做检测、分割或视觉增强,那它并不直接对应。第二,语言支路的部署价值取决于上下文更新频率。论文把 caption 生成放在离线阶段,这很现实,但也意味着场景变化过快时,调制信号可能会滞后。第三,结构先验对轮廓清晰、热特征稳定的类别更占优,但对像 Van 这类边界和语义都更模糊的类别,结构优势未必总能完整转成分类优势。
我觉得它最值得借走的,不只是 SA-Adapter 或 LGM 这两个模块,而是这种建模方式。对于 foundation model 迁移到多模态检测这类任务,不一定非得靠全量微调或更重的融合骨干。很多时候,更有效的路子是先问一句,这个任务真正缺的是哪一类信息,然后只为那类信息设计一条轻量但精准的补偿支路。
06 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。
文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!