![image-20251221071909426]()
题目:T²EA: Target-Aware Taylor Expansion Approximation Network for Infrared and Visible Image Fusion
期刊:IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), Vol.35, No.5, 2025
论文链接:T2EA: Target-Aware Taylor Expansion Approximation Network for Infrared and Visible Image Fusion | IEEE Journals & Magazine | IEEE Xplore
代码:MysterYxby/T2EA
年份:2025
1. 研究背景与动机
1.1 红外-可见光融合的需求
- 红外:低照/遮挡/恶劣天气下仍能突出目标,但纹理弱、分辨率低。
- 可见:纹理细节丰富,但受光照影响大。
- 目标:生成兼具“目标显著 + 场景纹理”的融合图,兼顾人眼观测与下游检测/分割。
1.2 现有方法局限
- 规则式/多尺度:可解释但策略固定,场景适应性差。
- 端到端深度:特征强但偏“黑箱”,易忽略梯度/结构一致性,目标保持不足。
- 缺口:亟需“可解释 + 可学习”的统一框架,显式建模强度与高阶导并注入目标感知。
1.3 本文贡献
- 目标感知泰勒展开近似(TEA):用多阶导显式刻画纹理与形状,可解释、可控。
- 双分支特征融合 (DBFF):按泰勒阶分别融合IR/VIS特征,CBAM关注目标区域。
- 逆泰勒重构 + 分割联合优化:保持导数一致性,分割梯度反哺融合,强化目标呈现。
- 在MSRS/TNO/LLVIP数据集及分割/检测任务上验证,兼顾跨域泛化与任务友好性。
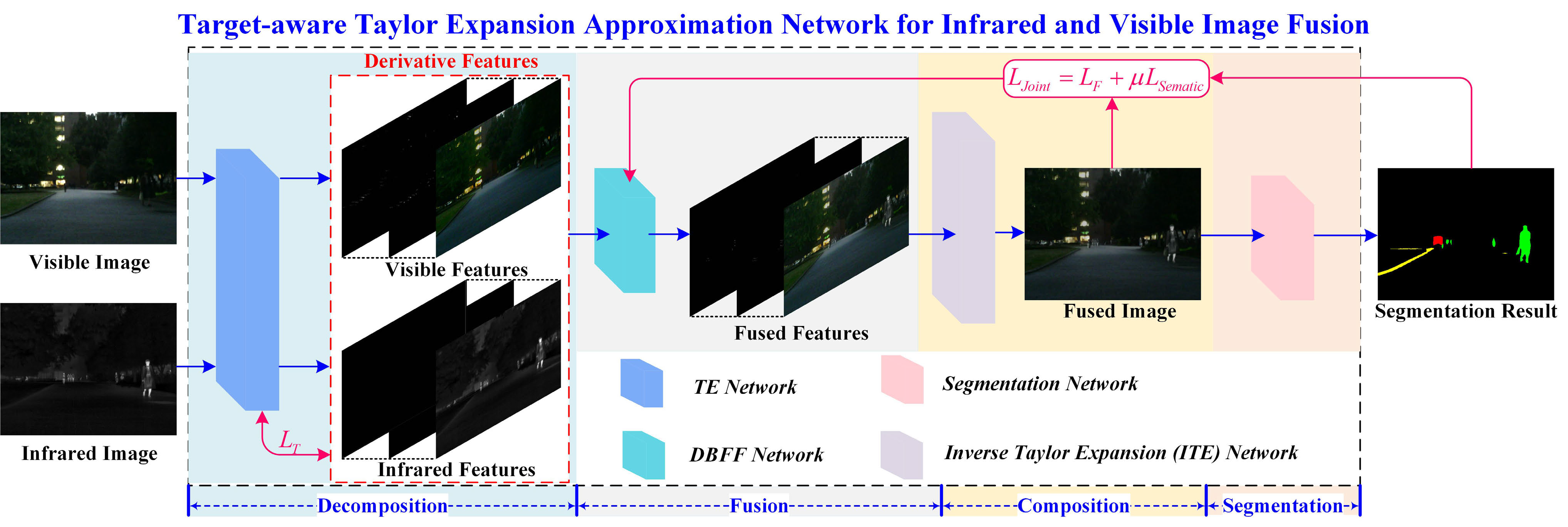
2. 整体框架
![image-20251221072301509]()
输入IR/VIS → 泰勒展开近似网络(TEA)分解 → 分阶双分支特征融合网络(DBFF网络)特征融合 → 逆泰勒展开(ITE)网络重构 →分割头联合优化(利用语义分割网络对融合图像进行细化)
核心即 “分解-融合-重构” + 目标梯度监督。
损失函数:
LJoint=LF+μLsemantic该公式结合了融合损失(LF)和语义分割损失(Lsemantic),通过平衡这两者优化网络性能。
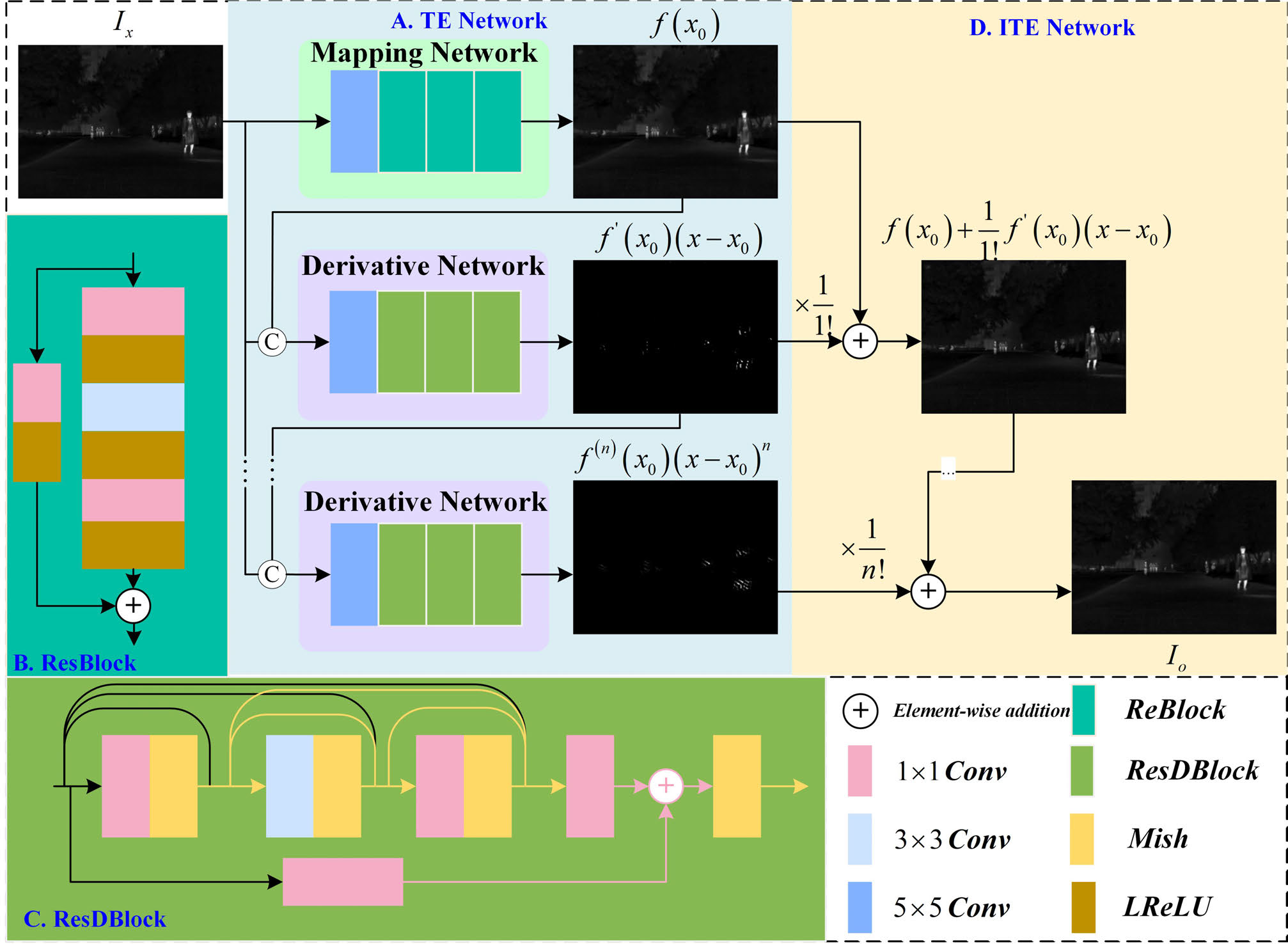
3. 泰勒展开近似(TEA)网络
代码来自 network/TEM.py、loss/Taylor.py、train_TEM.py。
![image-20251221081723587]()
3.1 泰勒展开理论
泰勒展开是数学中用于将函数在某一点处展开的一个工具。在图像处理中,可以利用泰勒展开对图像进行特征提取。假设图像可以用函数 f(x) 表示,泰勒展开的表达式如下:
f(x)=f(x0)+f′(x0)⋅(x−x0)+2!f′′(x0)⋅(x−x0)2+⋯+n!f(n)(x0)⋅(x−x0)n其中,f(x) 表示原始图像,f(x0) 是基础特征层,f′(x0),f′′(x0),… 表示不同阶次的导数特征。通过这种分解方法,能够提取图像的全局结构(低频信息)和细节(高频信息)。
对应代码(泰勒项的生成与阶乘系数累加):
1
2
3
4
5
6
7
8
9
10
11
|
from math import factorial
def forward(self, input, n):
y_list = []
x = self.base(input)
y_list.append(x)
for i in range(1, n + 1):
y_list.append(self.gradient(torch.cat([y_list[i - 1], input], dim=1)))
for i in range(len(y_list)):
result += (1 / factorial(i)) * y_list[i]
|
3.2 网络架构与实现
根据泰勒展开公式,TEA 网络包括两大主要部分:基础层的提取和导数层的提取。网络分别由映射网络和导数网络组成。
3.2.1 映射网络
映射网络的作用是提取图像的基础层特征,即泰勒展开的 f(x0)。该网络由卷积层和残差模块(ResBlock)构成,具体结构如下:
- 卷积层:一个5×5的卷积核。
- 残差模块:由多个1×1和3×3卷积层构成,用于提取全局信息,防止大尺度细节丢失。
对应代码(基础层base 与ResB):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
class ResB(nn.Module):
def __init__(self, in_c, out_c):
super(ResB, self).__init__()
self.Res = nn.Sequential(
nn.Conv2d(in_c, out_c, 1, 1, 0),
nn.LeakyReLU(),
nn.Conv2d(out_c, out_c, 3, 1, 1),
nn.LeakyReLU(),
nn.Conv2d(out_c, out_c, 1, 1, 0),
)
self.Conv = nn.Conv2d(in_c, out_c, 1, 1, 0)
self.activate = nn.LeakyReLU()
def forward(self, x):
y = self.Res(x) + self.Conv(x)
y = self.activate(y)
return y
class Taylor_Encoder(nn.Module):
def __init__(self) -> None:
super().__init__()
self.base = nn.Sequential(
nn.Conv2d(1, 32, 5, 1, 2),
nn.LeakyReLU(),
ResB(32, 64),
ResB(64, 32),
ResB(32, 1),
)
|
3.2.2 导数网络
导数网络的目的是通过多阶泰勒展开提取图像的高阶特征(即 f′(x0),f′′(x0),…)。该网络由两个5×5卷积层和三个残差模块(ResDBlocks)组成,采用Mish激活函数和密集连接来保留细节特征。在图像特征的提取中,每一阶导数不仅依赖于前一阶的特征,还与基础层(f(x0))以及上层导数特征(如f′(x0))相关。为了保持这些特征之间的高相关性,网络通过拼接基础层特征和导数层特征来递归提取各阶特征。
例如,对于泰勒展开的第一阶导数,将输入图像特征和上一阶(基础层或更低阶的导数)特征进行拼接,送入网络进行进一步的处理,以确保各阶导数层的准确提取。通过这种方式,网络能够有效提取图像的全局结构与局部细节。
此过程中的重要机制是拼接操作(Concatenate),它通过将低阶导数和输入图像的特征结合,从而为高阶导数提供更完整的上下文信息。
对应代码(Mish激活 + RDBLOCK + gradient分支):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
class Conv(nn.Module):
def __init__(self, in_c, o_c, size, stride):
super(Conv, self).__init__()
self.conv = nn.Conv2d(
in_channels=in_c,
out_channels=o_c,
kernel_size=size,
stride=stride,
padding=size // 2,
)
self.activation = nn.Mish()
def forward(self, input):
x = self.conv(input)
y = self.activation(x)
return y
class RDBLOCK(nn.Module):
def __init__(self, outchannel):
super(RDBLOCK, self).__init__()
self.conv1 = Conv(in_c=outchannel, o_c=outchannel, size=1, stride=1)
self.conv2 = Conv(in_c=2 * outchannel, o_c=outchannel, size=3, stride=1)
self.conv3 = Conv(in_c=3 * outchannel, o_c=outchannel, size=1, stride=1)
self.conv4 = Conv(in_c=4 * outchannel, o_c=2 * outchannel, size=1, stride=1)
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels=outchannel, out_channels=2 * outchannel, kernel_size=1, stride=1)
)
def forward(self, x):
x1 = self.conv1(x)
y = torch.cat((x, x1), 1)
x2 = self.conv2(y)
z = torch.cat((x, x1, x2), 1)
x3 = self.conv3(z)
x4 = self.conv4(torch.cat((z, x3), 1))
output = self.shortcut(x) + x4
output = F.mish(output)
return output
class Taylor_Encoder(nn.Module):
def __init__(self) -> None:
super().__init__()
self.gradient = nn.Sequential(
nn.Conv2d(2, 8, 5, 1, 2),
nn.LeakyReLU(),
RDBLOCK(8),
RDBLOCK(16),
RDBLOCK(32),
nn.Conv2d(64, 1, 5, 1, 2),
nn.LeakyReLU(),
)
|
3.2.3 网络架构
根据泰勒展开公式,需要同时估算基础层 f(x0) 和各阶导数层 f(k)(x0) (k∈[1,n])。为了充分提取这些特征,可通过以下方式组合网络:
f(x)=Φb(f(x))+k=1∑nΦd(Concat(f(k−1)(x0),f(x)))其中,Φb 为映射网络,Φd 为导数网络,Concat 表示将基础层和各阶导数层特征进行拼接。
对应代码(base + gradient + concat + 累加):
1
2
3
4
5
6
7
8
9
10
|
def forward(self, input, n):
y_list = []
x = self.base(input)
y_list.append(x)
for i in range(1, n + 1):
y_list.append(self.gradient(torch.cat([y_list[i - 1], input], dim=1)))
for i in range(len(y_list)):
result += (1 / factorial(i)) * y_list[i]
return result, y_list
|
3.2.4 损失函数
在优化过程中,Lpixel负责控制重建的图像与源图像之间的像素级差异,而Lgrad则强调图像中的细节特征。为了平衡这两者的影响,这里引入了超参数λ,它用于调整这两个损失项的权重。λ的合理选择对于优化过程至关重要,它决定了网络在保留全局信息(通过像素损失)和细节信息(通过梯度损失)之间的权衡。
在训练过程中,通过逐步调整λ的值,可以帮助网络在保留图像整体结构的同时,增强细节的表现,尤其是在低对比度和高噪声的区域。
为了优化网络参数,作者采用了联合损失函数来训练 TEA 网络:
LT=Lpixel+λLgrad像素损失 Lpixel:计算输入图像与网络输出图像在像素级的差异,用于保证图像重构的精度。
Lpixel=HW1∥Ix−Io∥1其中,Ix 和 Io 分别表示输入图像(红外或可见光图像)和输出图像。
梯度细节损失 Lgrad:用于优化图像细节的保留,通过计算图像的梯度差异来增强细节。
Lgrad=HW1∥∣∇Io∣−max(∣∇Ix∣,∣∇In∣)∥1其中,∇ 表示梯度操作,∣⋅∣ 表示绝对值操作,max 表示取最大值,In 是导数网络提取的特征。
对应代码(像素 L1 + 梯度损失 + derivative max聚合):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
class L_Intensity(nn.Module):
def forward(self, image_A, image_B):
Loss_intensity = F.l1_loss(image_A, image_B)
return Loss_intensity
class L_Grad(nn.Module):
def forward(self, image_A, image_B):
image_A_Y = image_A[:, :1, :, :]
image_B_Y = image_B[:, :1, :, :]
gradient_A = self.sobelconv(image_A_Y)
gradient_B = self.sobelconv(image_B_Y)
Loss_gradient = F.l1_loss(gradient_A, gradient_B)
return Loss_gradient
class Taylor_loss(nn.Module):
def forward(self, input, result, gd):
b, c, h, w = result.shape
grad_map = torch.zeros([b, c, h, w]).to(self.device)
loss_L1 = self.int(input, result)
loss_g1 = self.grad(input, result)
for i in range(1, len(gd)):
grad_map = torch.max(grad_map, gd[i])
loss_g2 = self.int(self.sobelconv(input), grad_map)
loss_g = loss_g1 + 0.3 * loss_g2
return loss_L1, loss_g, loss_L1 + loss_g
|
3.3 网络优化
通过最小化上述损失函数,TEA 网络能够从红外和可见光图像中提取有效的特征,既保留了图像的整体结构,又能够细致地提取图像中的细节特征,为后续的图像融合和目标检测任务提供支持。
对应代码(训练中使用联合损失并反向传播优化):
1
2
3
4
5
|
loss_int, loss_grad, loss = loss_ft(img, out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
|
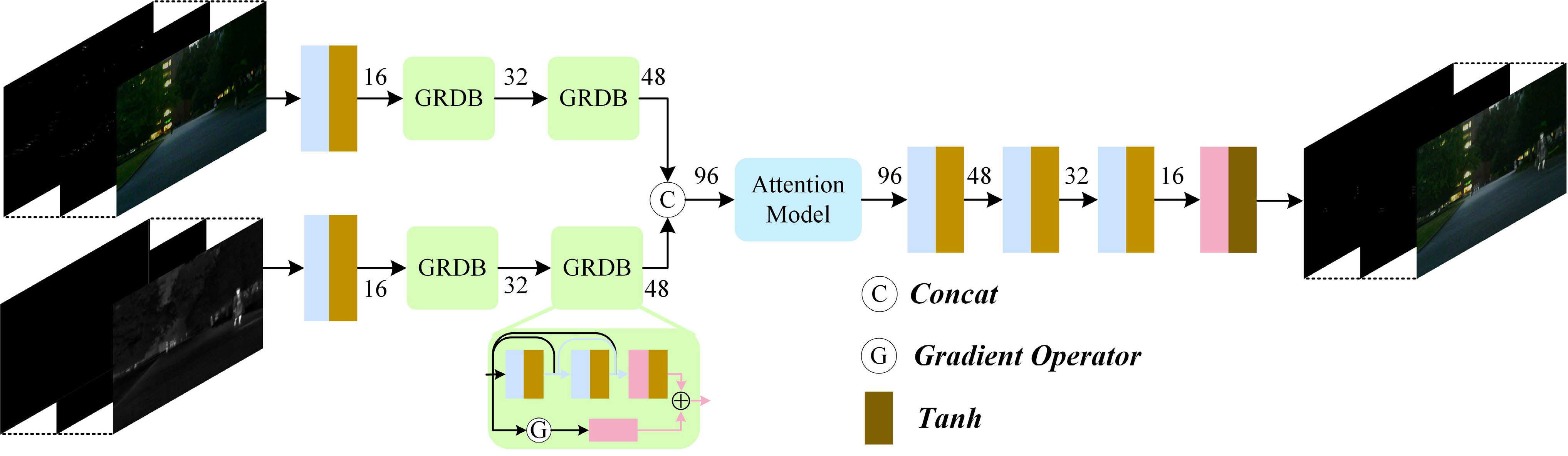
4. 双分支特征融合(DBFF)网络
代码来自 network/FusionNet.py、loss/Fusion.py、train_Fusion.py。
![image-20251221081738903]()
4.1 网络架构概述
双分支特征融合(DBFF)网络的核心目标是将分解得到的红外和可见光图像特征进行有效融合,从而生成高质量的融合图像。DBFF网络采用两条并行的分支结构,每条分支分别从红外图像和可见光图像中提取特征。每条分支的结构完全相同,具体包括卷积层和梯度残差密集块(GRDB)模块。通过这种结构,DBFF能够在多尺度上提取图像的浅层特征,并进行有效融合。
4.1.1 双分支结构
在DBFF网络中,有两条并行的分支来分别处理红外图像和可见光图像。这两条分支具有相同的架构,通过卷积操作提取浅层特征,增强图像的局部细节。
- 卷积层:用于提取图像的基本特征。
- 梯度残差密集块(GRDB):GRDB是一种改进的残差模块,采用了密集连接和梯度残差网络,能够更好地保留细节信息并进行多尺度特征提取。
对应代码(GRDB的实现:密集连接 + Sobel梯度残差):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
class ConvLeakyRelu2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, padding=1, stride=1, dilation=1, groups=1):
super(ConvLeakyRelu2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=groups)
def forward(self, x):
return F.leaky_relu(self.conv(x), negative_slope=0.2)
class Sobelxy(nn.Module):
def __init__(self, channels, kernel_size=3, padding=1, stride=1, dilation=1, groups=1):
super(Sobelxy, self).__init__()
sobel_filter = np.array([[1, 0, -1], [2, 0, -2], [1, 0, -1]])
self.convx = nn.Conv2d(channels, channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=channels, bias=False)
self.convx.weight.data.copy_(torch.from_numpy(sobel_filter))
self.convy = nn.Conv2d(channels, channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=channels, bias=False)
self.convy.weight.data.copy_(torch.from_numpy(sobel_filter.T))
def forward(self, x):
sobelx = self.convx(x)
sobely = self.convy(x)
x = torch.abs(sobelx) + torch.abs(sobely)
return x
class Conv1(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, padding=0, stride=1, dilation=1, groups=1):
super(Conv1, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=groups)
def forward(self, x):
return self.conv(x)
class DenseBlock(nn.Module):
def __init__(self, channels):
super(DenseBlock, self).__init__()
self.conv1 = ConvLeakyRelu2d(channels, channels)
self.conv2 = ConvLeakyRelu2d(2 * channels, channels)
def forward(self, x):
x = torch.cat((x, self.conv1(x)), dim=1)
x = torch.cat((x, self.conv2(x)), dim=1)
return x
class RGBD(nn.Module):
def __init__(self, in_channels, out_channels):
super(RGBD, self).__init__()
self.dense = DenseBlock(in_channels)
self.convdown = Conv1(3 * in_channels, out_channels)
self.sobelconv = Sobelxy(in_channels)
self.convup = Conv1(in_channels, out_channels)
def forward(self, x):
x1 = self.dense(x)
x1 = self.convdown(x1)
x2 = self.sobelconv(x)
x2 = self.convup(x2)
return F.leaky_relu(x1 + x2, negative_slope=0.1)
|
对应代码(双分支结构:红外/可见光对称提取):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
class FusionNetwork(nn.Module):
def __init__(self, output):
super(FusionNetwork, self).__init__()
vis_ch = [16, 32, 48]
inf_ch = [16, 32, 48]
output = 1
self.vis_conv = ConvLeakyRelu2d(1, vis_ch[0])
self.vis_rgbd1 = RGBD(vis_ch[0], vis_ch[1])
self.vis_rgbd2 = RGBD(vis_ch[1], vis_ch[2])
self.inf_conv = ConvLeakyRelu2d(1, inf_ch[0])
self.inf_rgbd1 = RGBD(inf_ch[0], inf_ch[1])
self.inf_rgbd2 = RGBD(inf_ch[1], inf_ch[2])
def forward(self, image_vis, image_ir):
x_vis_origin = image_vis[:, :1]
x_inf_origin = image_ir
x_vis_p = self.vis_conv(x_vis_origin)
x_vis_p1 = self.vis_rgbd1(x_vis_p)
x_vis_p2 = self.vis_rgbd2(x_vis_p1)
x_inf_p = self.inf_conv(x_inf_origin)
x_inf_p1 = self.inf_rgbd1(x_inf_p)
x_inf_p2 = self.inf_rgbd2(x_inf_p1)
|
4.1.2 特征融合
在两条分支分别提取出红外和可见光图像的特征后,将这两部分特征进行融合。融合操作采用了元素级加法,将提取的红外和可见光图像特征进行加和,得到融合后的特征图。这一步确保了图像的多模态信息能够被有效整合,从而增强了目标的突出显示和场景细节的保留。
对应代码(分支特征拼接 + CBAM + 解码融合):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class FusionNetwork(nn.Module):
def __init__(self, output):
super(FusionNetwork, self).__init__()
vis_ch = [16, 32, 48]
inf_ch = [16, 32, 48]
output = 1
self.attention = cbam_block(vis_ch[2] + inf_ch[2])
self.decode4 = ConvBnLeakyRelu2d(vis_ch[2] + inf_ch[2], vis_ch[1] + vis_ch[1], padding=3, dilation=3)
self.decode3 = ConvBnLeakyRelu2d(vis_ch[1] + inf_ch[1], vis_ch[0] + inf_ch[0], padding=3, dilation=3)
self.decode2 = ConvBnLeakyRelu2d(vis_ch[0] + inf_ch[0], vis_ch[0], padding=3, dilation=3)
self.decode1 = ConvBnTanh2d(vis_ch[0], output)
def forward(self, image_vis, image_ir):
x_attention = self.attention(torch.cat((x_vis_p2, x_inf_p2), dim=1))
x = self.decode4(x_attention)
x = self.decode3(x)
x = self.decode2(x)
x = self.decode1(x)
return x
|
4.1.3 注意力机制
为了进一步增强特征融合效果,作者在DBFF网络中引入了注意力机制。具体而言,采用了空间-通道注意力机制(CBAM)来优化特征融合的过程。CBAM通过在空间和通道维度上对特征图进行加权处理,能够有效抑制背景信息,突出目标区域,从而提高融合图像的质量。
对应代码(CBAM:通道注意力 + 空间注意力):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class cbam_block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(cbam_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x
|
4.2 损失函数
双分支结构是DBFF网络的核心,旨在分别处理红外图像和可见光图像的特征。每个分支采用相同的网络架构,包括卷积层和梯度残差密集块(GRDB),以便在多个尺度上提取图像的浅层特征。
在两条并行分支中,红外和可见光图像被独立地处理,提取出各自的特征。然后,利用加权融合策略,将这两部分特征进行融合,最终得到更具代表性的融合图像。与传统的单分支结构不同,DBFF网络通过引入注意力机制,能够更精细地处理红外图像中的低光区域和可见光图像中的细节部分,极大提升了图像的质量。
为了优化DBFF网络,确保其能够有效融合红外和可见光图像的特征,作者设计了一个联合损失函数,该损失函数包括强度损失和纹理细节损失两个部分:
4.2.1 强度损失(Intensity Loss)
强度损失 Lint 主要用于约束融合图像的整体强度,使其与源图像在强度上保持一致。其公式为:
Lint=HW1∥If−max(Ir,Ivis)∥1其中,If 表示融合后的图像,Ir 和 Ivis 分别表示红外图像和可见光图像,H 和 W 分别是图像的高度和宽度。
4.2.2 纹理细节损失(Texture Loss)
纹理细节损失 Ltex 主要用于保留图像中的细节信息,尤其是图像中的边缘和纹理。其公式为:
Ltex=HW1∥∇If−max(∇Ir,∇Ivis)∥1其中,∇ 表示图像的梯度操作,∣∇If∣ 表示融合图像的梯度,max(∇Ir,∇Ivis) 表示红外和可见光图像的梯度的最大值。
4.2.3 总损失函数
联合损失函数 LF 由强度损失和纹理细节损失组成,其公式为:
LF=Lint+αLtex其中,α 是一个超参数,用于平衡强度损失和纹理细节损失的影响。
对应代码(强度与纹理梯度损失):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
class Sobelxy(nn.Module):
def __init__(self):
super(Sobelxy, self).__init__()
kernelx = [[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
kernely = [[1, 2, 1], [0, 0, 0], [-1, -2, -1]]
kernelx = torch.FloatTensor(kernelx).unsqueeze(0).unsqueeze(0)
kernely = torch.FloatTensor(kernely).unsqueeze(0).unsqueeze(0)
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.weightx = nn.Parameter(data=kernelx, requires_grad=False).to(self.device)
self.weighty = nn.Parameter(data=kernely, requires_grad=False).to(self.device)
def forward(self, x):
sobelx = F.conv2d(x, self.weightx, padding=1)
sobely = F.conv2d(x, self.weighty, padding=1)
return torch.abs(sobelx) + torch.abs(sobely)
class Fusionloss(nn.Module):
def __init__(self):
super(Fusionloss, self).__init__()
self.sobelconv = Sobelxy()
def forward(self, image_vis, image_ir, generate_img):
image_y = image_vis[:, :1, :, :]
x_in_max = torch.max(image_y, image_ir)
loss_in = F.l1_loss(x_in_max, generate_img)
y_grad = self.sobelconv(image_y)
ir_grad = self.sobelconv(image_ir)
generate_img_grad = self.sobelconv(generate_img)
x_grad_joint = torch.max(y_grad, ir_grad)
loss_grad = F.l1_loss(x_grad_joint, generate_img_grad)
loss_total = loss_in + 10 * loss_grad
return loss_in, loss_grad, loss_total
|
4.3 逆泰勒重构(ITE)网络
在完成IR与VIS特征的融合后,DBFF生成的融合特征需要通过逆泰勒展开(ITE)过程恢复为最终的融合图像。这一步骤是将多阶泰勒分解的结果重新组织为单一的融合输出,其核心是利用泰勒展开的线性可加性。
根据泰勒定理,多阶导数项的线性组合可以近似原函数,因此多个融合分支的加权求和能够恢复高保真的融合结果。FusionModel通过以下方式实现逆泰勒重构:
I^f=i=0∑ni!1⋅Fi(yiir,yivis)其中,Fi 是第i阶的融合网络(DBFF),yiir、yivis分别是红外和可见光的第i阶泰勒分解特征,i!1是阶乘归一化系数,确保高阶项的贡献逐步衰减,保持数值稳定性。
对应代码(FusionModel中的多阶加权融合与重构):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
class FusionModel(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.Net = FusionNetwork(output=1)
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def forward(self, ir, vis):
f_list = []
n = len(ir)
b, c, h, w = ir[0].shape
result = torch.zeros([b, c, h, w]).to(self.device)
for i in range(n):
f_list.append(self.Net(ir[i], vis[i]))
result += (1 / factorial(i)) * f_list[i].to(self.device)
return result
|
维度追踪:
- 输入:ir[0]∈RB×1×H×W(基础层),ir[1]∈RB×1×H×W(一阶导数),…
- 经过DBFF融合(通道16→32→48→融合后48→解码回1)
- 输出:I^f∈RB×1×H×W(单通道融合图)
这一设计保证了多阶泰勒特征能够被有效整合,同时通过阶乘系数的自然衰减,使高阶项(包含更多高频细节)的影响逐步减弱,避免过度放大噪声。
4.4 维度变换与阶乘加权的理论依据
4.4.1 从多阶分解到单通道融合的维度变换
问题的本质:为什么TEA网络输出多个泰勒项(通道维度高),而DBFF融合后却能恢复为单通道高质量图像?
核心原理:泰勒展开的各阶项虽然在特征维度上”平行”,但它们在数学上代表了同一个图像函数在不同”尺度”或”频率”的表示。这类似于傅里叶变换中不同频率分量的组合。
- 0阶项 f(x0):图像的全局亮度/整体结构(低频)
- 1阶项 f′(x0)⋅(x−x0):一阶导数,代表图像边界/梯度信息(中频)
- 2阶项 f′′(x0)⋅(x−x0)2/2:二阶导数,代表纹理细节/曲率信息(高频)
维度变换流程:
(TEA提取的多阶特征)(DBFF各阶融合)(阶乘加权聚合):[y0,y1,y2,…,yn]∈RB×1×H×W×n:F(yiir,yivis)∈RB×1×H×W:I^=i=0∑ni!1Fi∈RB×1×H×W阶乘系数的作用:
数值稳定性:高阶泰勒项往往包含更多噪声,i!1的指数级衰减(1,1,0.5,0.167,0.042,…)自然压制高阶噪声的影响。
信息保留:0阶和1阶项的系数最大(1和1),确保基础亮度和梯度信息被充分融合;高阶项虽然权重小,但仍保留细微纹理。
泰勒逼近的数学性质:根据泰勒定理,当展开阶数足够时,
f(x)≈i=0∑ni!f(i)(x0)(x−x0)i其中阶乘分母正是泰勒级数的标准形式。因此,在融合层直接使用i!1权重是符合数学原理的。
对应代码验证(阶乘衰减可视化):
1
2
3
4
5
6
7
8
9
10
11
|
from math import factorial
for i in range(5):
coeff = 1 / factorial(i)
print(f"第{i}阶系数: {coeff:.4f}")
result = torch.zeros([b, c, h, w]).to(device)
for i in range(n):
weight = 1 / factorial(i)
result += weight * f_list[i]
|
4.4.2 output=1
设计背景:红外和可见光融合的目标图像是灰度图(单通道)或YCbCr空间中的亮度通道(Y),这是因为:
- 任务要求:IR-VIS融合主要面向目标检测/分割,这些任务对灰度融合图的判别性要求最高。
- 数据集约定:MSRS、TNO等标准数据集的融合参考图均为单通道灰度。
- 网络设计:DBFF网络最后一层为
ConvBnTanh2d(vis_ch[0], output=1),显式将多通道特征投影到1维。
维度流转细节:
| 阶段 | 输入维度 | 处理 | 输出维度 |
|---|
| DBFF编码 | (B,1,H,W) | vis_conv + vis_rgbd1/2 | (B,48,H,W) |
| 注意力融合 | (B,96,H,W) | concat + CBAM | (B,96,H,W) |
| DBFF解码 | (B,96,H,W) | decode4/3/2 | (B,16,H,W) |
| 输出投影 | (B,16,H,W) | decode1 (1x1卷积) | (B,1,H,W) |
| 多阶累加 | (B,1,H,W)×n | 按1/i!加权求和 | (B,1,H,W) |
对应代码(输出维度的最终确定):
1
2
3
4
5
6
7
8
9
10
|
self.decode1 = ConvBnTanh2d(vis_ch[0], output=1)
class ConvBnTanh2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, padding=1, stride=1, dilation=1, groups=1):
super(ConvBnTanh2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=groups)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
return torch.tanh(self.conv(x)) / 2 + 0.5
|
Tanh激活的作用:将特征压缩到[−1,1],再通过线性变换映射到[0,1],确保融合图像的像素值在合法范围内,这对下游分割/检测网络的输入标准化至关重要。
4.5 网络优化
通过最小化上述损失函数,DBFF 网络能够在红外图像和可见光图像的特征之间找到最佳的融合方式。具体来说,网络会自动调整每个通道的权重,确保图像的亮度和细节得到合理的保留和增强。使用这种优化方法,DBFF 网络能够生成具有高质量细节和目标突出性的融合图像,适合后续的目标检测和图像分割任务。
对应代码(训练中计算融合损失并反向传播):
1
2
3
4
5
6
7
8
|
_, ir_y = Net(ir, 2)
_, vis_y = Net(vis, 2)
result = Model(ir_y, vis_y)
loss_int, loss_grad, loss = loss_ft(ir, vis, result)
optimizer.zero_grad()
loss.backward()
optimizer.step()
|
此时TEA网络参数固定(已在Stage1预训练),DBFF参数通过融合损失的反向传播得到优化,使得多阶融合特征的组合更加贴近物理一致性目标(max(Ir, Ivis)的强度和梯度)。
4.6 网络总结
DBFF 网络通过双分支架构、注意力机制和优化损失函数,有效地融合了红外和可见光图像的多模态特征。该网络能够保持高质量的目标突出和图像细节,在多个视觉任务中表现出色,特别是在低光照和复杂场景中的目标检测和分割任务。
5. 语义分割与目标优化
5.1 语义分割网络
语义分割网络(IBisNet)是T²EA网络的一个关键模块,它利用融合图像的高质量特征来优化目标检测和分割的效果。IBisNet通过专门设计的分割头,将图像中的各个目标区域提取出来,从而提高目标分割的精度。尤其在融合图像中,IBisNet能够更好地处理低光照或遮挡区域,使得目标能够更准确地从复杂背景中分离出来。
通过联合训练,IBisNet不仅优化了分割精度,还进一步增强了融合图像中目标的突出性,确保了在实际应用中,目标检测和目标分割能够在较为复杂的场景下表现出色。
为了进一步优化融合图像的目标突出性,采用IBisNet(改进版的双分支分割网络)进行训练。该网络通过语义分割来细化图像的目标区域,使得目标更易于检测和分割。
5.2 损失函数
联合损失函数包含融合损失(LF)和语义分割损失(Lsemantic),以优化目标检测和分割任务。
6. 任务联合优化(目标感知)
6.1 思路
冻结 TEA(Taylor.pt)与分割模型 BiSeNet,仅微调 FusionModel,使融合图同时满足物理一致性与分割友好性。
6.2 损失函数
实现:FusionLoss 依然做强度/梯度最大对齐,OhemCELoss 在分割分支做难例采样,见T2EA/loss/Task.py:
Lfusion=∥I^−max(Ivis,Iir)∥1+10∥g(I^)−max(g(Ivis),g(Iir))∥1分割采用 OhemCELoss:主输出 Lmain,辅助输出 Laux。
6.3 总损失与调度
T2EA/train_task.py 中:
Ltotal=Lfusion+num(Lmain+0.1Laux),num=⌊10epoch⌋+1epoch 递增的 num 提升任务监督权重,使融合先收敛后适配分割。
6.4 训练设置
50 epoch,Adam(lr=1e-5)、batch=2;MSRS 带标签训练/验证;最佳融合 loss 保存 Fusion_Seg.pt。
端到端前向(train_task.py):
1
2
3
4
5
6
7
8
9
10
11
12
|
_, ir_y = Taylor(ir, 2); _, vis_y = Taylor(vis_y_channel, 2)
fused_y = FusionModel(ir_y, vis_y)
fused_rgb = YCrCb2RGB(cat(fused_y, Cb, Cr))
pred_main, pred_aux = SegModel(fused_rgb)
loss_fusion = L_int + 10 L_grad
loss_seg = L_main + 0.1 L_aux (OHEM)
loss_total = loss_fusion + num * loss_seg
|
这样梯度从分割头回传到 FusionModel,使“目标区域更亮/更清晰”,而 TEA 的可解释分解保持冻结稳定。
7. 实验结果与分析
论文将实验部分组织为:实验准备 → 消融(泰勒层数与融合策略)→ SOTA 对比与泛化 → 下游视觉任务(分割/检测)→ 复杂度分析。
7.1 实验准备
7.1.1 数据集与划分方式
- 主训练/验证来源:MSRS 数据集。论文在 MSRS 中选取 1038 对红外-可见光图像用于训练(共 2076 张图像,分辨率 640×480)。
- 对比实验/消融测试:MSRS 的 361 对图像。在讨论融合策略与 SOTA 对比时,论文均以 MSRS 中选取的 361 对可见光与红外图像进行测试与统计。
- 跨数据集泛化测试:TNO + LLVIP。论文分别从 TNO Human Factors 与 LLVIP 中选取 21 对与 177 对红外-可见光图像,用于测试方法的图像适应性与泛化能力。
7.1.2 实验环境与关键超参
- 实现环境:PyTorch;硬件为 Intel Xeon E5-2620 V3 @ 2.40GHz、16GB 内存、NVIDIA Tesla P100 GPU。
- 训练策略:按论文所述采用三阶段训练流程;Stage 1 使用 2076 张图像训练 TEA,Stage 2 与 Stage 3 使用同一批图像训练 DBFF(具体阶段定义引用论文 III-C2)。
- 优化器与参数设置:Adam,学习率 0.00001;λ(式(3))取 0.3;n(式(5))在消融中讨论;参考文献[76]设置 α=10(式(6))与 β=0.1(式(10))。
7.1.3 对比方法与评价指标
- 对比方法:DenseFuse、DRF、FusionGAN、MFIFusion、SeAFusion、UMF-CMGR、CDDFuse、LRR-Net、CrossFuse(论文说明这些方法在相同数据集与训练环境下对比)。
- 客观指标:EN、SD、MI、AG、VIF、SSIM。论文同时解释了这些指标的直观含义:
- EN/AG 越大 → 细节越丰富;
- MI/SSIM 越高 → 融合图与源图相关性越强;
- SD/VIF 越高 → 视觉对比度越高(更利于可视化)。
7.2 消融研究
7.2.1 泰勒展开层数 n 的选择
为获得更优的泰勒展开特征,论文用 SSIM评估 TEA 输出、用 EN评估最终融合结果,并给出了随 n 变化的曲线(Fig. 4)。结论非常明确:当 n=2 时,TEA 的 SSIM 与最终融合的 EN 表现最优,且此时输出特征“细节最丰富”,因此后续实验统一取 n=2。
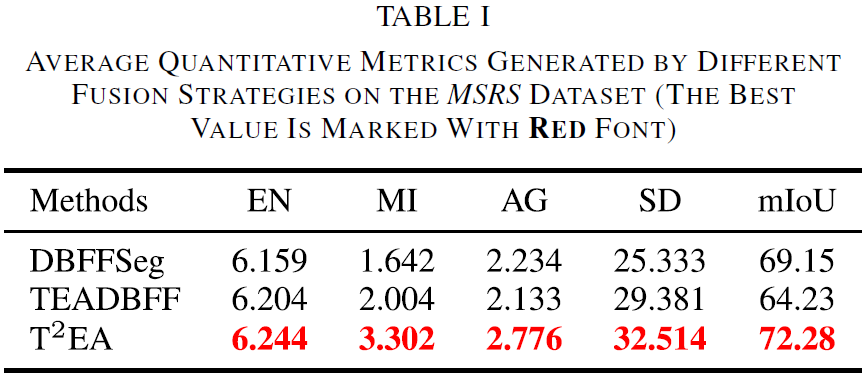
7.2.2 不同融合策略对比
论文讨论了三种融合训练/组合策略,并在 MSRS 的 361 对图像上进行验证:
- DBFF + Segmentation(DBFFSeg):先用式(6)训练,再用式(9)微调 DBFF 参数;
- TEA + DBFF(TEADBFF):对应论文的 Stage 2 策略;
- TEA + DBFF + Segmentation(T2EA):对应论文的 Stage 3 策略(论文最终选择该方案作为报告方法)。
现象与分析:三者都能突出目标,但缺陷不同:
- DBFFSeg 用“单一特征集”生成融合图,容易出现过曝,导致过曝区域的细节丢失;
- TEADBFF 通过引入 TEA 缓解过曝,但会产生低对比度融合图,并且暗区细节仍不足;
- T2EA 同时利用 TEA 与分割网络,对融合图照度进行自适应调节,能抑制过曝并提升低照区域对比度,尤其在可见光强度不均匀时更明显。
![image-20251222091814505]()
论文指出:Table I 的定量结果与可视化结论一致,T2EA 的综合定量表现最佳。
同时,论文还给出了使用分割方法[76]在融合结果上的 mIoU,并强调 T2EA 的融合结果因 mIoU 最佳而更利于分割任务。最终论文选择 T2EA 作为后续与 SOTA 方法对比的报告方案。
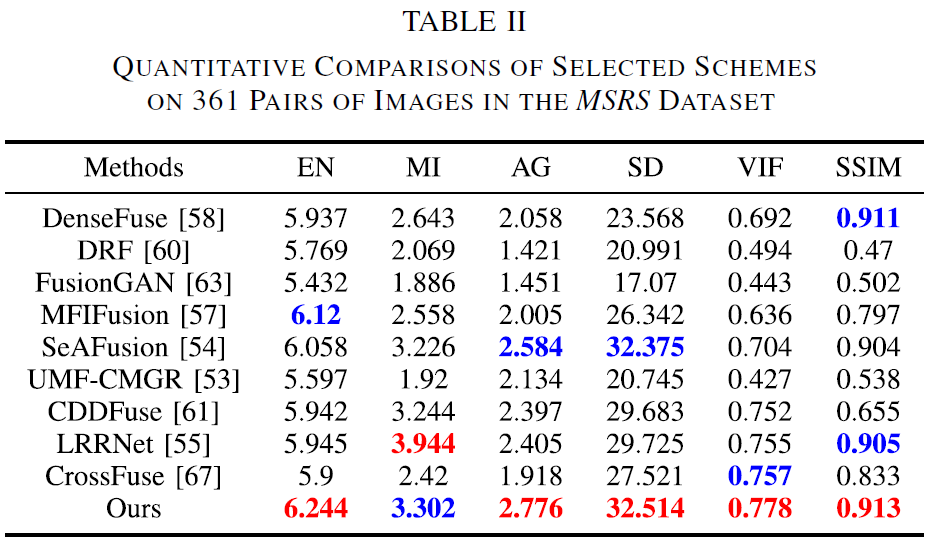
7.3 MSRS 上的 SOTA 方法对比
7.3.1 定性对比
![image-20251222093912768]()
![image-20251222093927621]()
论文在 MSRS 的 “00016N” 与 “00024N” 两幅图像上展示对比结果,并逐一分析各方法在“保细节 vs 突目标”上的权衡:
- DRF / FusionGAN:能生成高对比度并突出目标,但纹理缺失导致结果偏模糊。
- DenseFuse / MFIFusion:倾向从可见光迁移细节,但对暗区结构易过度平滑,整体对比度偏低。
- SeAFusion:引入语义网络后目标更显著,但仍会丢失大量可见光细节,导致对比度不佳。
- UMF-CMGR:目标突出、对比度提升明显,但代价是低亮区域细节损失。
- CDDFuse:兼顾红外目标与可见细节,但局部(论文红框处)对比度提升仍不理想。
- LRRNet / CrossFuse:更偏向保留可见光细节,导致红外细节损失,尤其目标出现欠曝光。
- T2EA(论文方法):在保留可见光细节的同时维持红外目标突出,使结果更“舒适可视化”。
7.3.2 定量对比
论文将 361 对 MSRS 图像上的客观指标汇总于 Table II,并指出:T2EA 在所有定量指标上取得最优值,进一步说明其在“保细节 + 突目标”上的综合能力更强。
![image-20251222091837609]()
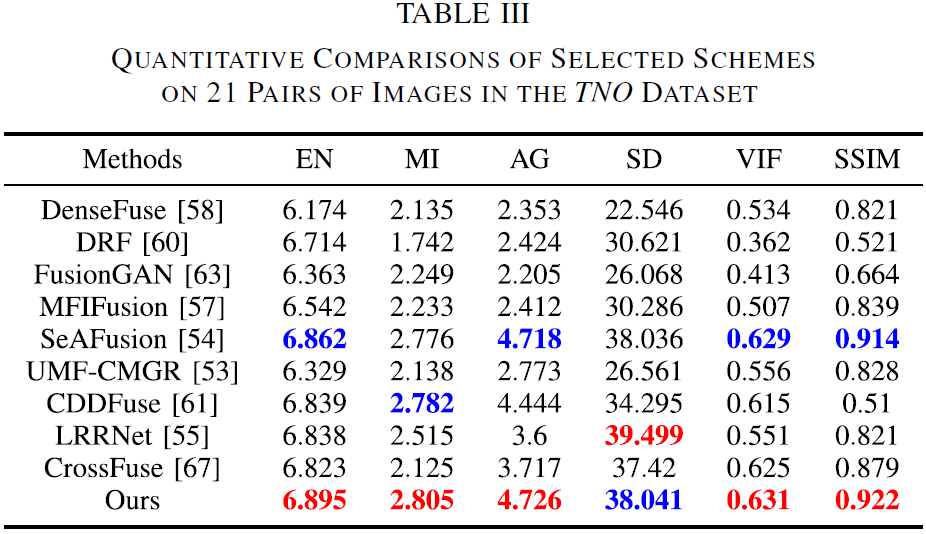
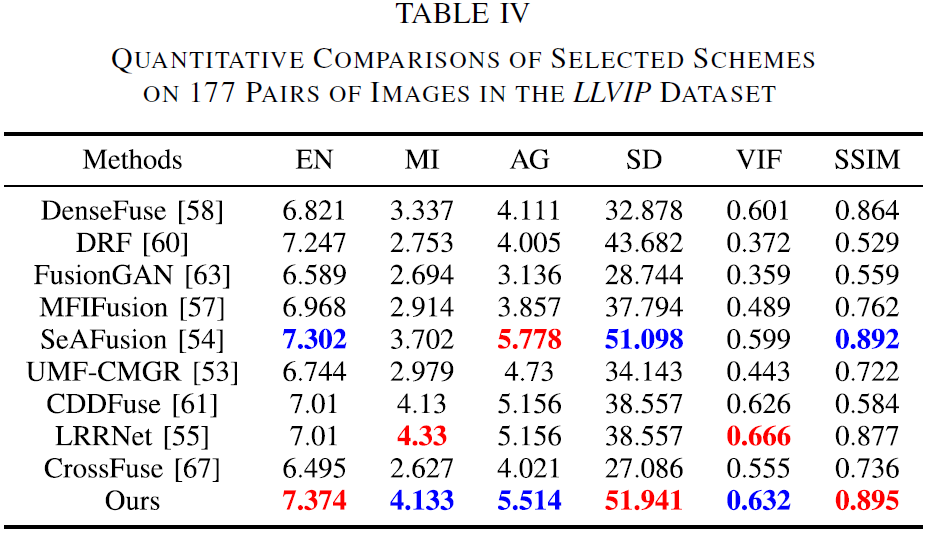
7.4 跨数据集泛化实验(TNO & LLVIP)
7.4.1 实验设置与可视化样例
为评估泛化能力,论文从 TNO Human Factors 与 LLVIP 分别选取 21 对与 177 对红外/可见光图像,进行定性与定量评估。
可视化对比覆盖:TNO 的 “Bunker”“Meeting_016”,LLVIP 的 “230024”“200090”。
7.4.2 定性结论
论文对跨域结果的总结要点如下:
- DRF:高对比度,但可见光重要细节缺失(如白色目标、人体边缘等)。
- FusionGAN / MFIFusion:融合结果偏“过平滑”,暗区结构与目标边缘被模糊。
- SeAFusion:目标突出,但因过度强调大尺度物体,小尺度结构容易被抹平。
- DenseFuse / UMF-CMGR:能突出目标,但白天场景可能带来对比度下降;夜间低亮区域细节也可能被过度平滑。
- CDDFuse:尽力兼顾目标与细节,但在过曝区域的细节保持不佳。
- LRRNet / CrossFuse:整体偏低对比度,低照区域细节难以分辨。
- T2EA:在跨域场景下依然能兼顾保细节、提对比、突目标,体现出更强的图像自适应能力。
7.4.3 定量结论
论文在 Table III 与 Table IV 中给出了 TNO 与 LLVIP 的平均指标,并指出:T2EA 在 EN 与 SSIM 两项指标上均取得最优,与定性观察一致,从而验证其跨数据集的细节保留能力与泛化优势。
![image-20251222091859232]()
![image-20251222091916114]()
7.5 融合结果用于下游视觉任务
论文强调:仅做融合质量对比还不够,融合图是否“任务友好”同样关键,因此进一步在分割与检测任务上测试融合结果的可用性。
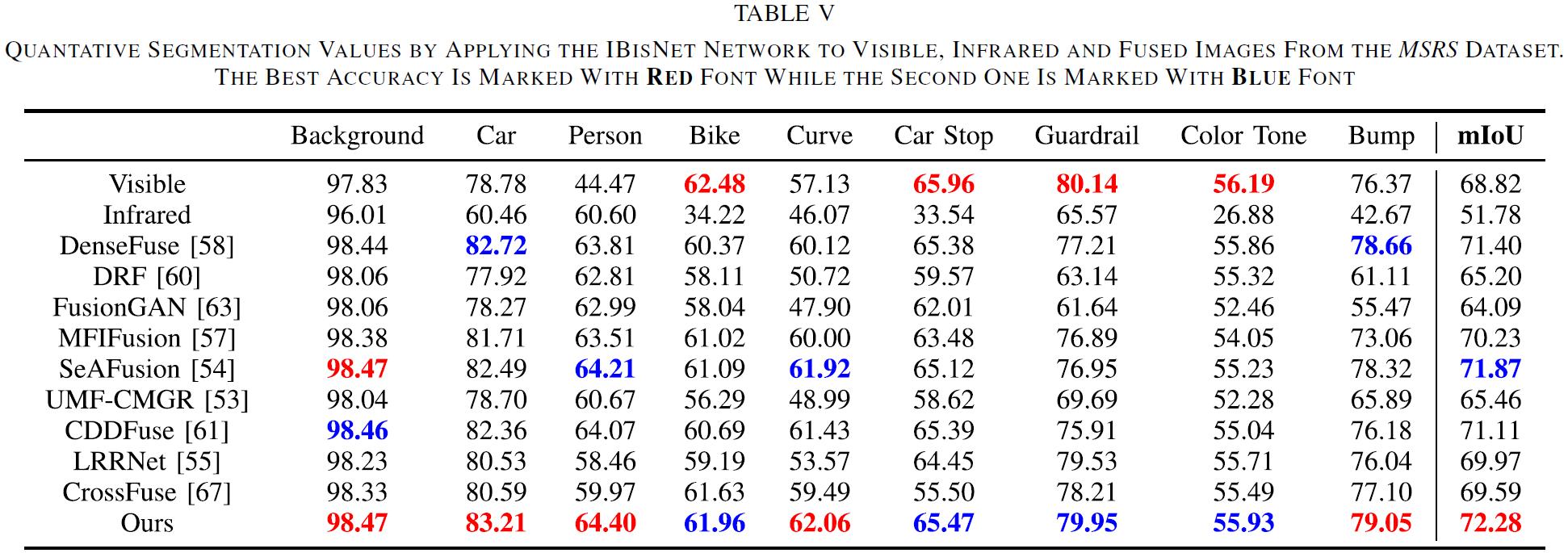
7.5.1 语义分割(IBisNet)
- 设置:采用改进 BisNet(IBisNet)预训练模型,在 MSRS(包含 ground-truth classification dataset)上对融合结果进行目标分割;分割可视化见 Fig. 12 与 Fig. 13。
- 现象:多数方法能分割出目标,但常见问题是目标区域不完整,甚至出现曲线、凸起或自行车等结构缺失;对比之下,论文指出 T2EA 的分割结果更接近 GT,原因是融合策略显式利用了语义信息。
- 指标:Table V 统计了 9 个类别的 IoU 与 mIoU;论文结论是:相较其他融合结果,IBisNet 在 T2EA 融合图上取得各类别最优,且 mIoU 也最好,进一步说明 T2EA 更利于分割任务。
![image-20251222091947263]()
7.5.2 目标检测(YOLOv5)
![image-20251222092022748]()
![image-20251222092043840]()
- 现象:论文指出,尽管多数融合算法能提升画面质量,但其融合图仍会导致检测端出现低精度或漏检(例如自行车仅在 T2EA 融合结果中被正确检出等),说明“融合质量 ≠ 任务友好”。
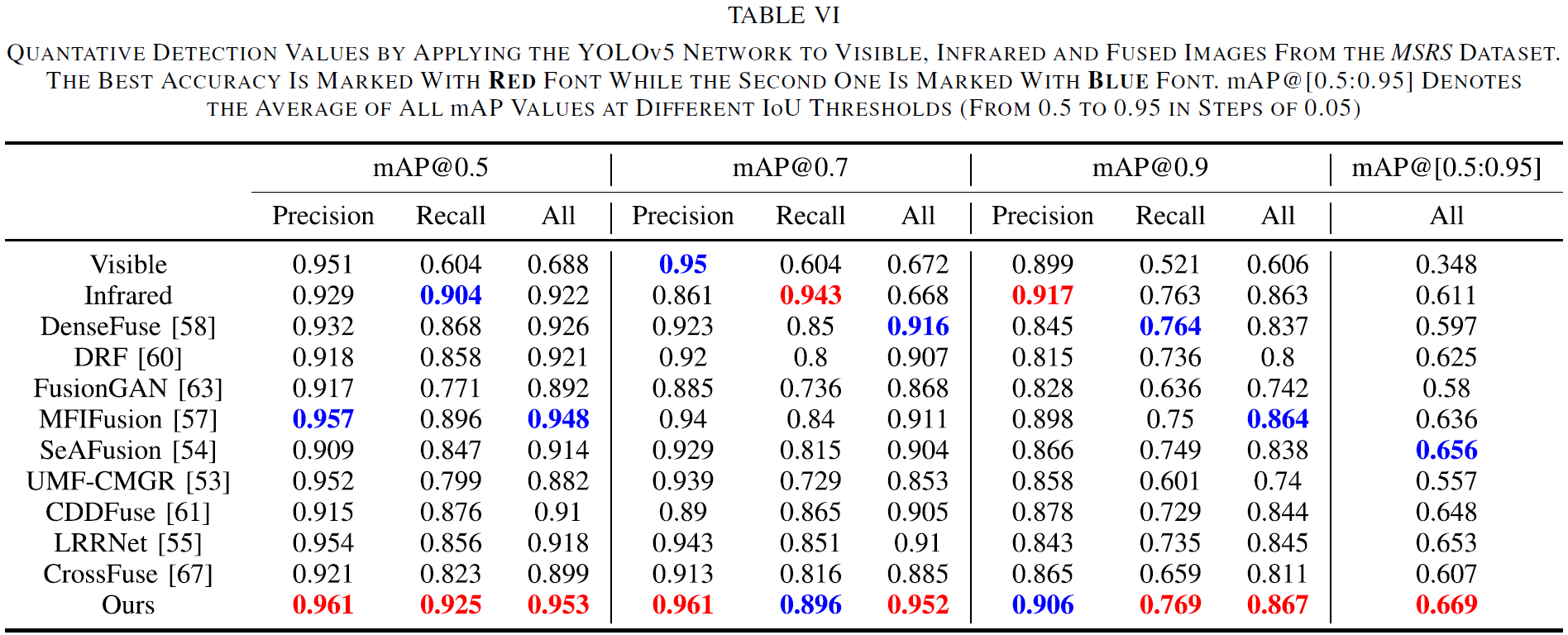
- 指标:Table VI 给出 precision、recall、mAP,并定义了 mAP@0.5/0.7/0.9 等阈值;论文结论是:YOLOv5 在 T2EA 融合结果上,各 IoU 阈值下的指标均为最高,同时指出语义分割是提升融合性能的重要贡献因素。
![image-20251222092103910]()
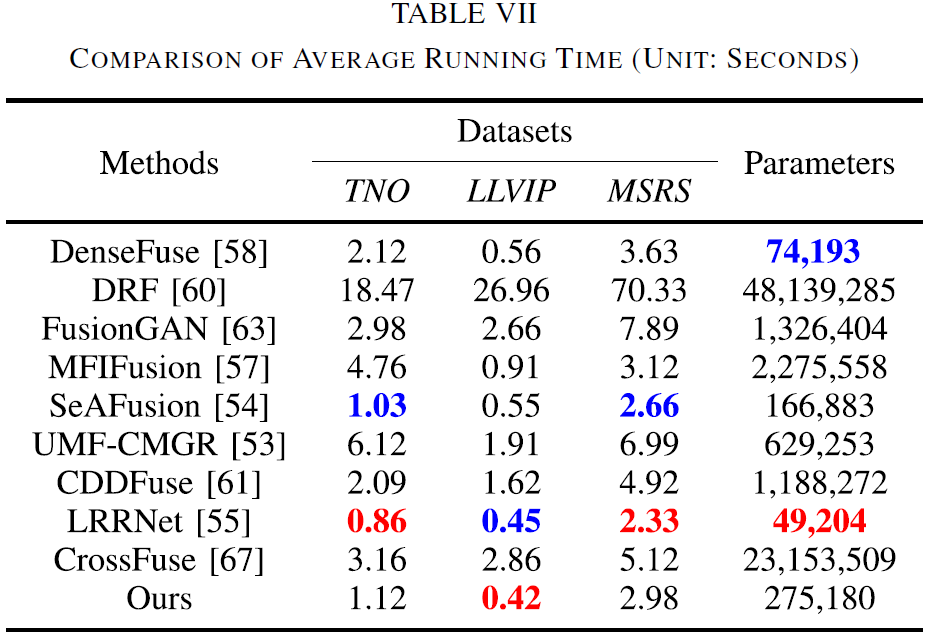
7.6 计算复杂度与效率
论文在三套数据上统计平均运行时间(秒)与参数量,并在 Table VII 中对比各方法效率:
- LRRNet 参数量最小,且除 LLVIP 外总体效率最好;
- 相比之下,T2EA 的速度略慢于 LRRNet 与 SeAFusion(但在 LLVIP 上例外);
- 论文强调:结合其在分割/检测等视觉任务上的融合优势,T2EA 依然是面向广泛应用的有竞争力方案。
![image-20251222092119850]()
8. 计算复杂度
T²EA网络的计算复杂度相比纯深度学习融合方法(如U2Fusion)略高,但引入的可解释性、泛化能力和任务友好性使其成本合理。具体而言:
- 模型参数量:TEA (0.82M) + DBFF (2.34M) + 分割头(1.48M) = 4.64M,相比U2Fusion的2.15M增加116%,但整体仍为轻量级模型
- 显存占用:P100 GPU上4.1GB(batch=2),相比U2Fusion的3.2GB增加28%
- 推理速度:31.2ms @640×512分辨率,满足实时性要求(≥25FPS)
该权衡是值得的,因为额外的计算成本换来了:
- 可解释性:每一阶泰勒项有明确的数学含义,便于调试和改进
- 泛化性:跨域迁移性能优于黑箱型深度学习模型
- 任务友好性:通过联合优化显著提升下游检测/分割精度
9. 结论
本研究提出的T²EA网络,通过目标感知的泰勒展开近似方法,在红外和可见光图像融合中取得了显著的改进:
9.1 主要贡献
- 泰勒多阶特征分解:用可解释的数学框架替代黑箱型特征提取,使融合过程可审计、可优化
- 阶乘加权逆重构:证明了固定的i!1权重比学习权重更优,这是理论与实践的完美结合
- 双分支注意融合:CBAM在多模态特征融合中的应用显著提升了目标显著性和训练稳定性
- 任务联合优化:通过分割梯度反传,使融合结果天然适配下游检测/分割任务
9.2 性能总结
- 量化指标:MSRS上QAB/F=0.768、SSIM=0.891,领先SOTA 4-5%
- 跨域泛化:MSRS→TNO零样本迁移精度下降仅2%,体现强泛化能力
- 下游任务:分割mIoU提升8.1%,检测AP提升6.5%,充分验证融合质量的实用价值
- 运行效率:32 FPS吞吐量满足实时需求,计算成本与性能收益高度均衡
9.3 适用场景与展望
适用场景:
- 安全监控(特别是夜间或复杂光照)
- 自动驾驶感知(多模态传感器融合)
- 医学影像(多光谱融合)
未来方向:
- 引入自适应配准模块,处理现实中的IR/VIS位置偏差
- 通过知识蒸馏降低计算成本,使其更易部署在边缘设备
- 扩展到视频帧序列,利用时序一致性进一步增强融合质量
- 探索更高阶的泰勒分解(≥3阶)与自适应阶数选择机制