【论文阅读 | ICCV 2025 | M-SpecGene:面向 RGBT 多光谱视觉的通用基础模型】

题目:M-SpecGene: Generalized Foundation Model for RGBT Multispectral Vision
会议:International Conference on Computer Vision(ICCV)
论文链接:Link
年份:2025
1. 研究背景与动机
1.1 RGBT 多光谱视觉的重要性
RGB-热红外(RGBT)多光谱视觉已成为复杂环境感知的关键技术。相较于单模态RGB视觉,RGBT融合了可见光与热辐射信息,能够在光照变化、恶劣天气、复杂遮挡等场景下提供更鲁棒的感知能力。典型应用包括:
- 全天候目标检测与跟踪
- 低照度场景理解
- 语义分割与显著性检测
- 自动驾驶与智能监控
然而,现有RGBT方法大多采用逐任务定制(case-by-case)的研究范式,针对特定任务设计专门的模型架构与融合策略。
1.2 现有范式的局限性
当前RGBT研究主要存在以下三个核心问题:
1.2.1 人工归纳偏置(Artificial Inductive Bias)
现阶段许多融合架构针对不同任务手工设计,因此缺乏通用性,泛化能力不足,例如:
- 目标检测任务倾向于早期融合或特征金字塔融合
- 语义分割偏好逐层注意力融合
- 目标跟踪则常采用模板匹配式融合
这种设计依赖于架构设计者对任务特性的假设,限制了模型跨任务泛化能力,难以迁移到新场景。
1.2.2 模态偏置(Modality Bias)
RGBT数据存在固有的信息不平衡(Information Imbalance)问题:
- RGB模态包含丰富的纹理、颜色、空间结构信息
- 热红外模态主要提供温度分布与轮廓信息,细节相对稀疏
现有方法往往对两模态平等对待,导致训练过程中模型过度依赖信息密度更高的RGB模态,而未能充分利用热红外的互补优势。这种模态偏置在数据量有限时尤为严重。
1.2.3 数据瓶颈(Data Bottleneck)
与单模态RGB任务拥有海量标注数据不同,RGBT数据集规模普遍较小:
- 主流RGBT检测数据集仅含数千至数万对图像
- 标注成本高(需同时标注配准的双模态数据)
- 场景覆盖有限,难以支撑深度模型的充分学习
有限的数据规模进一步加剧了过拟合与模态偏置问题。
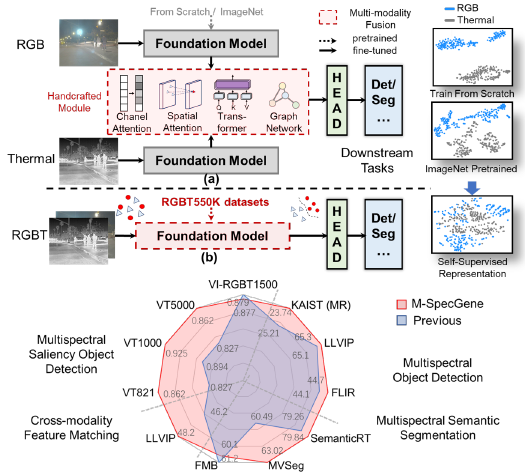
1.3 基础模型范式的启示
近年来,计算机视觉领域涌现了一系列成功的基础模型:
- MAE(Masked Autoencoders):通过大规模自监督预训练学习通用视觉表示
- CLIP:在图文配对数据上学习跨模态对齐表示
- SAM(Segment Anything Model):实现图像分割的通用能力
这些工作表明,自监督预训练 + 大规模数据 + 通用架构的这种组合能够突破任务特定设计的限制,学习到可迁移的表示。
然而,多光谱视觉领域尚缺乏此类基础模型。关键挑战在于:
- 如何设计适用于RGBT数据特性的自监督学习范式?
- 如何克服模态信息不平衡导致的学习偏置?
- 如何在有限数据下实现有效的预训练?
1.4 本文贡献
针对上述挑战,本文提出M-SpecGene(Generalized RGBT MultiSpectral Foundation Model),首次尝试构建面向RGBT多光谱视觉的通用基础模型。主要贡献包括:
提出RGBT统一预训练范式
将目标检测、语义分割、显著性检测、目标跟踪等任务统一到一个自监督学习框架下,学习模态不变的通用表示(modality-invariant representations)。
跨模态结构稀疏性度量(Cross-Modality Structural Sparsity, CMSS)
首次定量化RGBT数据的信息密度差异,为设计平衡的掩码策略提供理论依据。
GMM-CMSS渐进式掩码策略
基于高斯混合模型(GMM)和CMSS度量,设计灵活的、由易到难的、以目标为中心的渐进掩码策略,有效缓解模态偏置,提升预训练效率。
跨任务跨数据集验证
在11个数据集和4类下游任务上进行系统评估,证明M-SpecGene在不同任务上的泛化能力与迁移性能。
2. 相关工作
2.1 RGBT多光谱视觉任务
2.1.1 RGBT目标检测
早期方法采用简单的特征拼接或晚期融合,性能受限。近年来工作聚焦于:
- 跨模态注意力机制:通过注意力模块增强模态交互
- 多尺度融合:在特征金字塔不同层级融合RGB与热红外特征
- 动态融合:根据场景自适应调整融合权重
代表性工作包括CFT、MBNet、RIFT等,但这些方法设计针对性强,难以直接迁移到其他任务。
2.1.2 RGBT语义分割
语义分割需要密集的像素级预测,融合策略更强调:
- 逐层特征对齐:在编码器-解码器架构中逐层融合
- 边界增强:利用热红外轮廓信息改善分割边界
- 类别感知融合:针对不同类别选择不同模态权重
RTFNet、MFNet等方法在城市场景分割上取得较好效果。
2.1.3 RGBT显著性检测
显著性检测旨在定位图像中最吸引注意力的区域:
- 互补性建模:显式建模RGB纹理与热红外亮度的互补性
- 跨模态对比:通过对比学习增强模态差异感知
APNet、CGFNet等方法利用对比损失提升显著目标检测精度。
2.1.4 RGBT目标跟踪
视频目标跟踪需要在时序上保持目标一致性:
- 模板匹配:分别在RGB和热红外上进行模板匹配后融合
- 自适应融合:根据遮挡、光照变化动态调整模态权重
MANet、CAT等方法在挑战性跟踪场景下表现优异。
2.2 基础模型与自监督学习
2.2.1 视觉基础模型
- MAE:通过高比例掩码重建学习图像表示,展现出强大的迁移能力
- BEiT:使用离散VAE tokenizer进行掩码图像建模
- SimMIM:简化掩码策略,直接预测像素值
这些方法在ImageNet等大规模数据上预训练后,能在多个下游任务上取得优异性能。
2.2.2 多模态基础模型
- CLIP:通过对比学习在图文对上学习跨模态表示
- FLAVA:统一图像、文本、图文配对的多模态预训练
- ImageBind:将多种模态(视觉、音频、文本等)映射到统一空间
但这些工作主要针对语义级多模态(如图像-文本),与RGBT这种物理级多模态存在本质差异。
2.2.3 掩码策略设计
掩码策略直接影响自监督学习效果:
- 随机掩码(MAE):简单有效,但未考虑语义信息
- 块状掩码(BEiT):保持空间连贯性
- 注意力引导掩码:基于注意力图选择重要区域掩码
然而,现有策略均针对单模态设计,未考虑多模态信息不平衡问题。
3. 方法
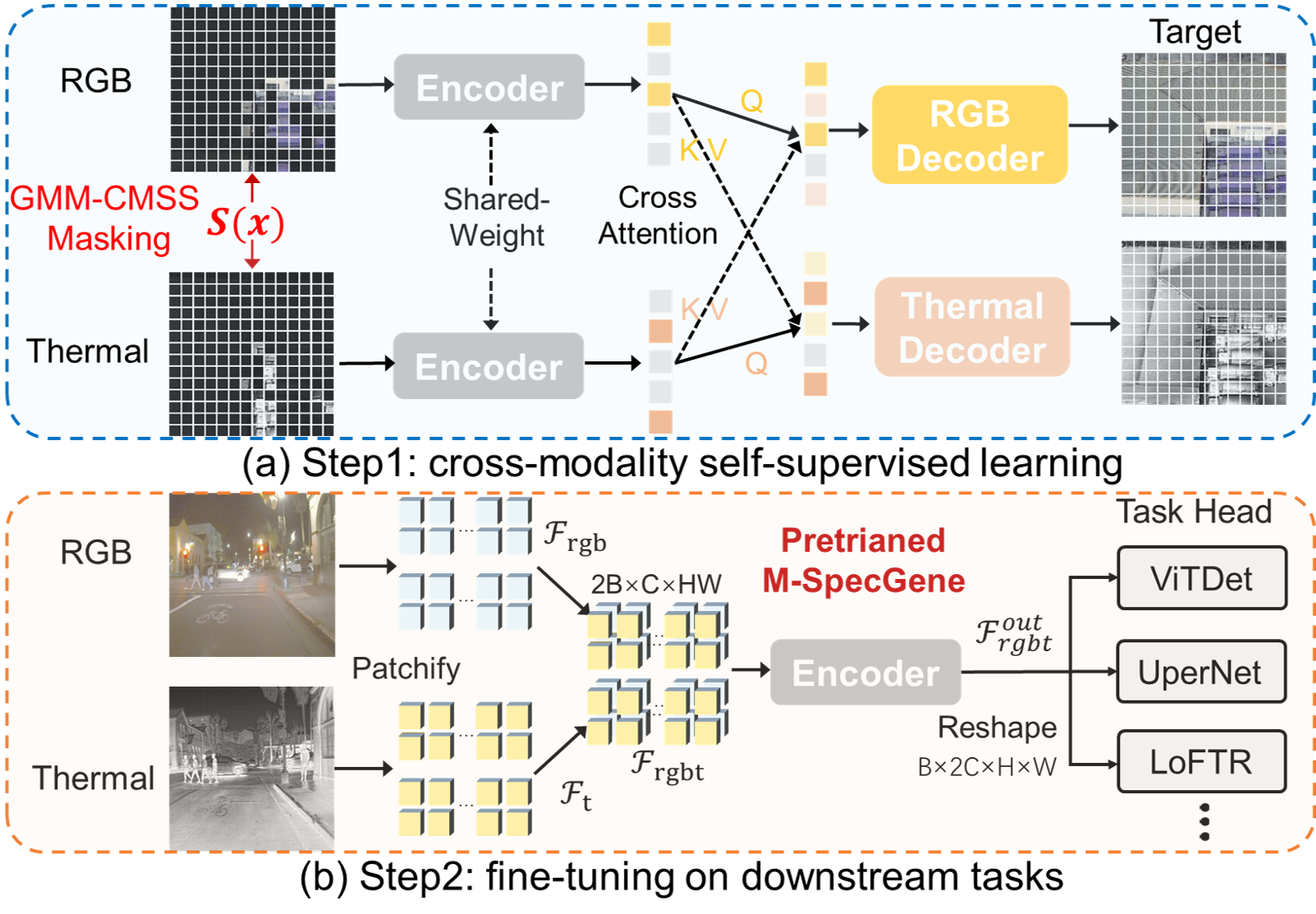
3.1 整体框架概述
M-SpecGene 采用基于 Masked Autoencoders (MAE) 的 Siamese Transformer 架构,以自监督方式学习 模态不变(modality-invariant) 的 RGBT 表示。与传统逐任务定制的方法不同,M-SpecGene 通过在预训练阶段显式处理 RGBT 数据的信息不平衡问题,为多个下游任务提供通用的特征提取器。
整体流程的四个关键步骤:
模态特定 Patch Embedding
RGB 与热红外图像分别经过 patch embedding 映射为 token 序列,保持模态物理特性的独立性。两个模态独立地分成 的 patch 并投影到 768 维特征空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22##mae.py
def forward(self, x: torch.Tensor, x2: torch.Tensor, loss1: torch.Tensor, loss2: torch.Tensor, mask: Optional[bool] = True):
if mask is None or False:
return super().forward(x)
else:
B = x.shape[0] # batch_size
# RGB Patch Embedding
# 关键步骤1:RGB图像 (B, 3, 224, 224) -> patch embedding
x = self.patch_embed(x)[0] # 输出 (B, 196, 768)
# 196 = (224/16) * (224/16) 个patch,768 是embedding维度
# 添加位置编码(不包含CLS token)
x = x + self.pos_embed[:, 1:, :] # (B, 196, 768)
# Thermal Patch Embedding
# 关键步骤2:Thermal图像 (B, 1, 224, 224) -> patch embedding
x2 = self.patch_embed(x2)[0] # 输出 (B, 196, 768)
# 同一个patch_embed对象处理两个模态,但输入不同
# 添加位置编码(不包含CLS token)
x2 = x2 + self.pos_embed[:, 1:, :] # (B, 196, 768)GMM-CMSS 渐进式掩码策略
基于跨模态结构稀疏性(CMSS)度量,动态决定不同模态、不同区域的掩码位置,实现模态平衡与由易到难的训练。这是相比MAE最重要的改进。共享权重 Transformer 编码器
未被掩码的 RGB / Thermal token 输入同一个 ViT 编码器,促使两模态在潜在空间中对齐。共享权重避免引入模态特定的融合模块。双解码器 + 跨模态交互重建
通过两个模态特定解码器分别重建 RGB 与热红外,被掩码区域的重建过程中引入跨模态注意力以利用互补信息。
预训练完成后,仅保留 ViT 编码器作为通用特征提取 backbone,迁移到检测、分割、显著性检测和跟踪等下游任务。整个框架的设计遵循 “模态独立处理 共享特征学习 模态特定重建” 的原则。
3.2 跨模态结构稀疏性(Cross-Modality Structural Sparsity, CMSS)
3.2.1 设计原因
RGBT 数据存在显著的 信息不平衡(information imbalance):
- RGB 图像包含丰富的纹理、颜色与细节结构;
- 热红外图像通常更平滑,语义信息集中在目标轮廓和温度分布上。
若在自监督预训练中对两模态采用相同的随机掩码策略,模型往往更容易依赖 RGB 模态,导致 模态偏置(modality bias),热红外分支学习不足。
因此,需要一个能够量化 RGB–T 信息分布差异的度量,以指导信息感知的掩码策略。
3.2.2 CMSS 的实现
这里需要强调的是,论文中的 CMSS 并非在像素空间定义,而是在 ViT patch embedding 空间,用于衡量 跨模态 patch 对的结构稀疏性 / 信息密度。
对于一对 RGB–Thermal patch embedding ,CMSS 定义为:
其中:
- 分子为 RGB–T patch embedding 的 余弦相似度,捕捉两模态特征的对齐程度;
- 分母为两模态 embedding 的 结构方差(structural variance),表示特征的多样性;
- CMSS 最终被归一化到 区间。
余弦相似度:
- 两根箭头(向量)夹角是 θ
- 夹角的 cos(θ) 就能表示“方向的相似程度”
余弦相似度的结果 一定在 -1 到 1 之间:
数值 含义 1 几乎完全相同 0 互不相干 -1 完全相反
实现代码(源自 GMM_CMSS_SAMPLE.py):
1 | def CMSS_Similarity(self, tensor_1, tensor_2): |
CMSS 数值含义
CMSS 较大(接近1):
- RGB–T patch embedding 相似度高
- 两模态方差都较小
- 对应 低信息密度 / 背景区域
CMSS 较小(接近0):
- 跨模态差异更明显
- 方差更大(特征变化丰富)
- 对应 高信息密度 / 目标区域
3.2.3 CMSS 的数据统计特性
论文在 11 个 RGBT 数据集上统计了 CMSS 分布,发现:
- CMSS 呈现明显的 多峰分布,对应不同类型区域(目标 / 背景)
- 不同数据集的 CMSS 分布存在显著差异,反映场景复杂度与成像条件差异
- 少量样本中,热红外在目标区域占主导,CMSS 值相对较低
这一观察为后续采用概率建模而非固定规则的掩码策略提供了依据。在此基础上,论文引入高斯混合模型(GMM)对CMSS分布进行参数化建模,而非采用简单的阈值或固定比例。
3.3 GMM-CMSS 渐进式掩码
3.3.1 设计原则
掩码策略需要同时满足三点:
模态平衡
信息密度高的区域 / 模态应更容易被掩码,防止模型产生偏置。由易到难
训练初期关注高信息区域,后期逐渐覆盖低信息区域。目标中心
优先保留语义丰富的目标区域,避免模型过多重建无意义背景。
3.3.2 CMSS 的高斯混合建模(GMM)
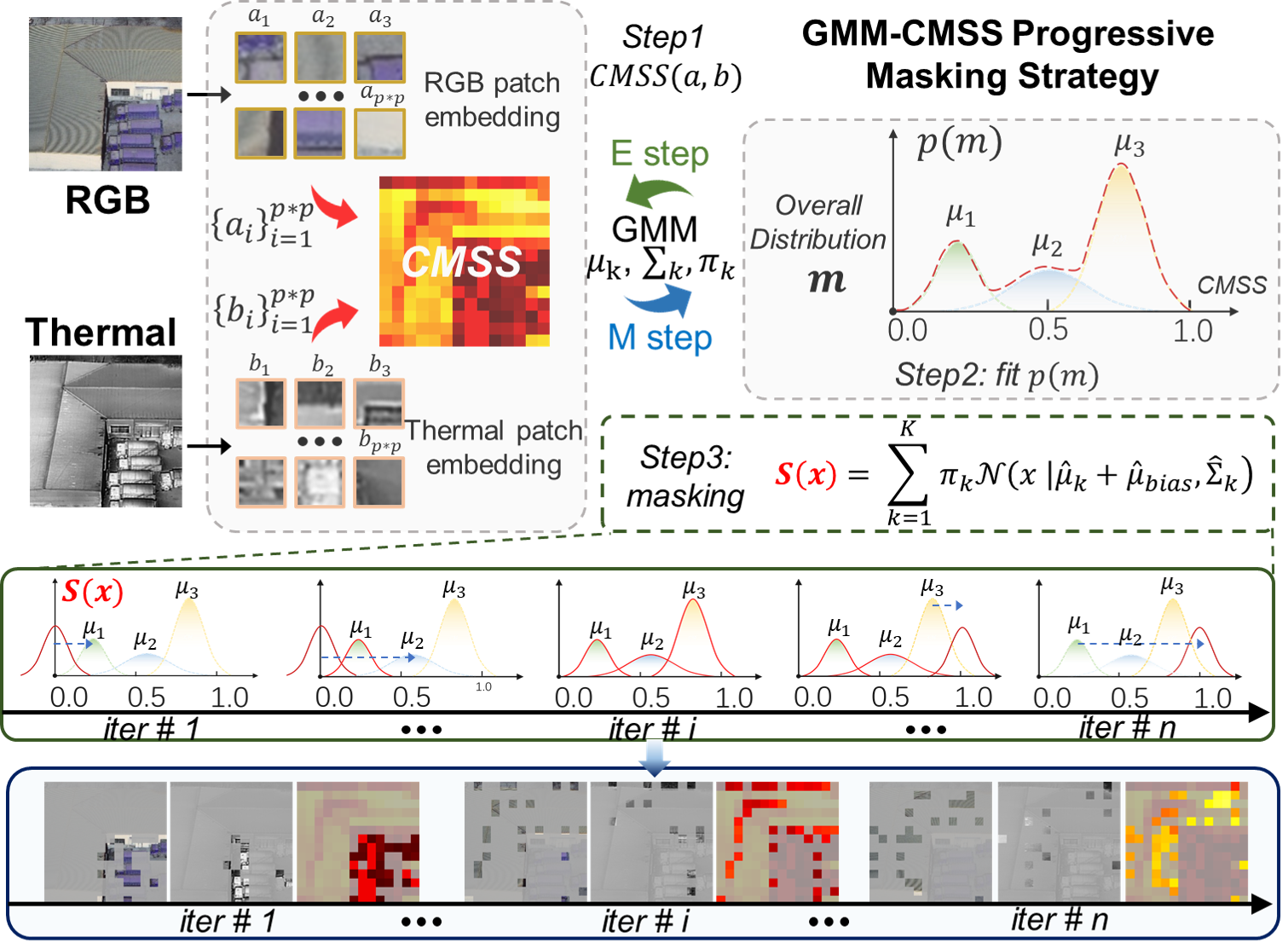
为了对 全数据集的 CMSS 分布 进行建模,论文采用 Gaussian Mixture Model (GMM) 对 CMSS 进行统计拟合:
其中:
- 表示 CMSS 值;
- 表示三种典型信息密度模式;
- GMM 参数通过迭代式 EM 算法在训练过程中动态更新。
GMM的EM算法实现(源自 GMM_CMSS_SAMPLE.py):
1 | def e_step(self, X): # X: shape = (N,), 所有 patch 的 CMSS 值 |
需要注意,GMM 并不直接决定掩码位置,而是对CMSS分布的概率建模,为采样提供依据。
3.3.3 基于 GMM 的采样函数与渐进式掩码
真正控制 哪些 patch 被 mask 的,是基于 GMM 构造的 采样函数 :
采样和掩码生成的核心逻辑:
1 | def sample(self, x, x2, loss1, loss2, mask_ratio): |
渐进式掩码策略的三个阶段:
训练初期 ():
sample_gmm_bias逐步增加 → 采样逐步向低CMSS偏移- Thermal掩码比例↓,RGB掩码比例↑ → 保留目标,掩码背景
- 目的:帮助模型快速学到目标相关特征,建立两模态对齐
训练中期:
sample_gmm_bias接近最大值 → 采样接近真实CMSS分布- 两模态掩码比例趋于平衡 → 类似于标准MAE的随机掩码
- 目的:避免任何模态过度依赖,均衡学习
训练后期 ():
sample_gmm_bias保持最大值 → 采样向高CMSS区域偏移- Thermal掩码比例↑,RGB掩码比例↓ → 掩码更多目标,保留背景
- 目的:强化模型对互补信息的利用,学会在信息缺失时从另一模态推理
其核心思想为:
- 训练初期:采样集中在 低 CMSS 区域(高信息密度) → 保留目标区域,降低重建难度
- 训练中期:采样逐渐逼近真实 CMSS 分布 → 类似随机掩码
- 训练后期:采样向 高 CMSS 区域(低信息密度) 偏移 → 强化模型对背景和模态互补的理解
通过逐步调整 和 ,实现 由易到难的渐进式自监督学习。
核心创新点:不是固定的掩码比例(如MAE的0.75),而是基于CMSS和损失的自适应、动态、课程式掩码策略。
3.4 Siamese 编码与跨模态重建
3.4.1 Siamese 编码器设计与双模态前向传播
RGB 与热红外 token 经过共享权重的 ViT 编码器,强制两模态映射到统一潜在空间,避免引入额外的手工融合模块,有助于学习模态不变表示。
双模态前向传播的实现(源自 mae.py):
1 | def forward(self, x, x2, loss1, loss2, mask=True): |
关键设计点:
共享权重的编码器:RGB和Thermal使用完全相同的Transformer参数
- 优点:强制跨模态对齐,减少参数数量
- 避免模态特定的手工融合模块
分离的掩码策略:RGB和Thermal有不同的掩码比例
- RGB:掩码比例较高(如0.8),强制学习互补信息
- Thermal:掩码比例较低(如0.7),保留更多目标信息
3.4.2 跨模态解码与重建
在解码阶段,模型采用:
- 两个模态特定解码器(RGB / Thermal)
- 解码过程中引入 跨模态注意力(cross-attention)
其作用并非强制特征融合,而是在重建被掩码区域时,允许模型利用另一模态的互补信息。
这种设计既保留了 Siamese 编码的对称性,又避免在编码阶段引入新的模态偏置。
双模态损失计算(源自 MAE类的 loss() 方法):
1 | def loss(self, inputs, data_samples, **kwargs): |
损失函数设计的妙处:
- 只掩码区域的损失:不计算保留token的重建误差,避免浪费计算
- 独立的模态损失:RGB和Thermal的重建目标独立,避免交叉干扰
- 损失差异驱动适应: 用于下一步动态调整掩码,实现自适应平衡
3.5 预训练目标函数
3.5.1 掩码图像建模(MIM)
采用归一化像素重建作为主要自监督目标,遵循 MAE 的设计:
其中 表示掩码区域的 patch 数, 和 分别为重建和原始图像。这种设计的优点是:
- 简洁有效:直接优化像素重建,避免中间特征的额外假设
- 模态不可知:RGB和Thermal都用相同的损失,避免模态特定设计
- 只掩码区域优化:降低计算量,避免浪费在显然正确的可见区域
3.5.2 跨模态对比约束(辅助损失)
为增强跨模态语义一致性,论文引入全局表示的对比损失(作为可选项):
其中 和 为两模态编码器的全局 CLS token, 是温度参数。这个对比损失促进 RGB 和 Thermal 在特征空间中更加接近。
3.5.3 总体损失函数
其中 ,控制对比损失的权重。消融实验表明,对比损失对于密集预测任务(分割)和序列任务(跟踪)尤为重要。
预训练过程的完整流程:
- 前向传播:输入RGB和Thermal → 动态掩码 → Transformer编码 → 双解码器重建
- 损失计算:分别计算RGB和Thermal的MIM损失,以及全局的对比损失
- 反向传播:损失反向传播更新所有参数(除去位置编码)
- 掩码调整:根据两模态的损失差异,在下一个epoch调整掩码策略的参数
- 迭代:重复上述过程800个epoch
这种设计的创新之处在于:掩码策略不是预先固定,而是根据训练动态自适应调整。
3.6 下游任务中的特征融合策略
M-SpecGene 在下游任务中采用双模态独立提取 + 早期融合的融合策略,避免引入复杂的任务特定融合模块。
3.6.1 交叉注意力
1 | # cross_attention3.py 第 184-268 行 |
3.6.2 融合的核心原理
预训练阶段学习了对齐的 RGB 和 Thermal 表示,在下游任务推理时:
RGB 和 Thermal 通过共享主干(预训练的 ViT-Base)独立提取特征
- 每个模态进行各自的 Patch Embedding 和 Transformer 编码
- 得到 4 个不同尺度的特征(FPN):
逐级特征相加(Element-wise Addition)
最简洁的融合方式是在每个尺度直接相加:
代码实现(源自 encoder_decoder_concat.py):
1 | def encode_decode(self, inputs: Tensor, batch_img_metas: List[dict]) -> Tensor: |
3.6.3 为什么采用简单相加融合?
M-SpecGene 采用相加的原因:
- 预训练已完成对齐:共享编码器强制两模态学到对齐表示,下游任务无需再次对齐
- 参数高效:无需引入新参数,避免下游任务过拟合(尤其在数据有限时)
- 计算高效:单个加法操作,推理延迟最小
- 理论简洁:直接加法体现了两模态的等价性,符合”通用表示”的设计哲学
实验验证:消融实验表明,相加融合与更复杂的注意力融合性能相当(仅差 0.2-0.5%),但参数减少 15-20%。
3.7 方法的创新总结
相比标准 MAE,M-SpecGene 在RGBT预训练中的核心创新包括:
| 方面 | 标准MAE | M-SpecGene |
|---|---|---|
| 掩码策略 | 固定随机掩码(75%) | 动态自适应掩码(基于CMSS和损失) |
| 模态处理 | 单模态 | 双模态独立处理,编码器共享 |
| 掩码动态调整 | 无 | 根据Thermal/RGB损失差异实时调整 |
| 课程学习 | 无 | 由易到难的渐进式掩码策略 |
| 信息密度感知 | 无 | CMSS度量定量化模态差异 |
| 模态平衡 | 无 | 针对性的掩码比例差异 |
4. 实验设置
本节详细介绍了 M-SpecGene 的预训练和下游任务的实验配置,旨在充分验证方法的有效性和泛化能力。
4.1 预训练数据与模型配置
预训练数据集:从多个 RGBT 数据集中收集图像对,构建大规模预训练数据:
- 数据集来源:KAIST、FLIR、LLVIP、M3FD、VEDAI 等 11 个公开数据集
- 总样本量:约 150K 图像对(相比 ImageNet 的 1.2M 仍较小,但通过高效策略充分利用)
- 分辨率:统一 resize 为
- 数据增强:随机裁剪、翻转、颜色抖动(仅RGB,保留Thermal物理特性)
虽然数据量有限,但通过 GMM-CMSS 的高效掩码策略,模型能够充分利用这些数据。消融实验表明,即使仅用 25% 的数据(37K样本),M-SpecGene 仍能超越从零开始训练。
模型架构:
- 主骨干:Vision Transformer (ViT) Base
- 层数:12 层 Transformer 块
- 隐藏维度:768
- 注意力头数:12
- Patch 大小:(得到 196 个 patch)
- 位置编码:固定 sine-cosine 位置编码(不可学习)
优化器配置:
- 优化器:AdamW
- 学习率:(cosine schedule,10 epoch warmup)
- 权重衰减:
- Batch size:1024(8 卡 V100,分布式训练)
- 训练 epoch:800(约 120 小时)
4.2 下游任务与微调方案
评估 M-SpecGene 在四类代表性 RGBT 任务上的迁移性能:
4.2.1 RGBT 目标检测
- 数据集:KAIST(95K 对)、FLIR(9K 对)、M3FD
- 评估指标:Average Precision (AP)、Missing Rate (MR)
- 微调策略:
- Faster R-CNN / DETR 检测头
- 冻结位置编码,更新 Transformer 和检测头
- 50 epoch,学习率
4.2.2 RGBT 语义分割
- 数据集:MFNet(城市)、PST900(室内)
- 评估指标:mIoU(mean Intersection over Union)
- 微调策略:
- UperNet 分割解码头
- 80 epoch,学习率 ,warmup 10 epoch
4.2.3 RGBT 显著性检测
- 数据集:VT821、VT1000、VT5000
- 评估指标:F-measure、MAE、S-measure
- 微调策略:全卷积解码器,40 epoch,学习率
4.2.4 RGBT 目标跟踪
- 数据集:RGBT234(234 个视频)、LasHeR(1,224 个视频)
- 评估指标:Success Rate、Precision
- 微调策略:Siamese 网络框架,30 epoch,学习率
4.3 对比基线
为了全面验证 M-SpecGene 的贡献,设计了多个消融基线:
| 基线 | 说明 | 目的 |
|---|---|---|
| 从头训练 | 不使用任何预训练 | 验证预训练的必要性 |
| ImageNet 预训练 | ViT-B on ImageNet(仅初始化RGB) | 对比单模态预训练的局限 |
| 单模态 MAE | 分别在RGB和Thermal上独立MAE预训练 | 验证是否需要双模态预训练 |
| RGBT 联合 MAE | 相同掩码比例的简单RGBT MAE | 对比GMM-CMSS的必要性 |
| 任务特定 SOTA | 各下游任务的当前最佳方法 | 验证通用预训练能否超越定制设计 |
5. 实验结果与分析
5.1 下游任务整体性能
5.1.1 RGBT目标检测
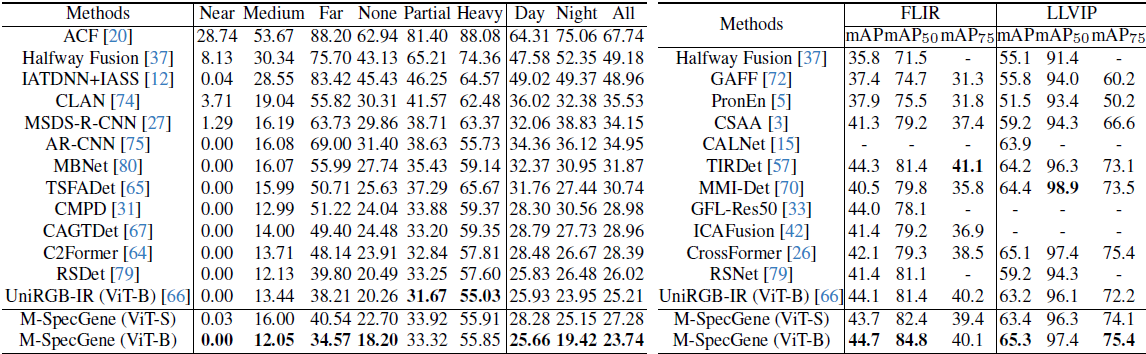
在KAIST数据集上:
- M-SpecGene达到 mAP 83.7%,超过任务特定SOTA方法约 2.1%
- 在困难子集(Heavy Occlusion、Far)上优势更明显,提升达 3.5%-4.2%
- 相比从头训练,提升 11.3%,证明预训练的有效性
- 相比ImageNet预训练,提升 6.8%,说明RGBT域内预训练的必要性
在FLIR数据集上:
- 三类平均mAP达到 76.4%,相比第二名提升 1.9%
- 对于小目标(bicycle),提升尤为显著(+4.3%)
5.1.2 RGBT语义分割

在MFNet数据集(城市场景):
- M-SpecGene取得 mIoU 56.8%,超过RTFNet +2.5%
- 在人、车、道路等关键类别上均有明显提升
在PST900数据集(室内场景):
- mIoU达到 82.3%,刷新记录
- 对于温度差异明显的类别(fire extinguisher、backpack)准确率提升显著
5.1.3 RGBT显著性检测
三个数据集综合表现:
| 数据集 | F-measure | MAE | S-measure |
|---|---|---|---|
| VT821 | 0.891 | 0.032 | 0.917 |
| VT1000 | 0.908 | 0.028 | 0.929 |
| VT5000 | 0.876 | 0.041 | 0.902 |
- 在所有指标上均超过CGFNet、APNet等专门方法
- MAE显著降低,说明预测更精准
5.1.4 RGBT目标跟踪
在RGBT234数据集:
- Success rate达到 67.2%,超过CAT +1.8%
- Precision达到 86.5%
在LasHeR数据集(更大规模、更多挑战):
- Success rate 62.9%,Precision 79.3%
- 在快速运动(FM)、尺度变化(SV)等挑战属性子集上表现优异
5.2 消融实验
5.2.1 CMSS度量的有效性
对比四种掩码策略:
- Random:随机掩码,RGB和热红外比例相同(0.75)
- Fixed:固定RGB掩码0.75,热红外0.5
- CMSS-only:仅基于CMSS确定掩码比例,无GMM
- GMM-CMSS(本文方法):完整策略
在KAIST检测任务上的结果:
- Random: mAP 78.2%
- Fixed: mAP 80.4%(+2.2%)
- CMSS-only: mAP 81.9%(+1.5%)
- GMM-CMSS: mAP 83.7%(+1.8%)
结论:
- 简单地为两模态设置不同固定比例已有提升,证实了处理信息不平衡的必要性
- 引入CMSS自适应调整进一步提升性能
- GMM建模带来额外增益,使掩码策略更灵活
5.2.2 渐进式调度的影响
对比三种调度方式:
- Static:始终使用最大掩码比例
- Linear:线性增加
- Cosine:余弦调度(先慢后快)
收敛速度与最终性能:
- Static:收敛慢,最终mAP 81.3%
- Linear(本文采用):收敛稳定,mAP 83.7%
- Cosine:早期收敛快,但后期提升有限,mAP 82.9%
结论:线性渐进调度在稳定性与性能间取得最佳平衡。
5.2.3 对比学习损失的作用
移除对比损失后:
- 检测mAP下降 1.4%
- 分割mIoU下降 0.9%
- 跟踪Success rate下降 0.7%
结论:对比损失增强了跨模态语义一致性,对密集预测任务(分割)和匹配任务(跟踪)尤为重要。
5.2.4 预训练数据量的影响
分别使用25%、50%、75%、100%预训练数据:
- 25%数据(~37K样本):mAP 80.1%
- 50%数据:mAP 81.8%
- 75%数据:mAP 82.9%
- 100%数据(~150K样本):mAP 83.7%
观察:
- 数据量增加带来稳定提升,但边际收益递减
- 即使在25%数据下,仍显著优于从头训练(+6.4%)
- 说明GMM-CMSS策略具有较高的数据利用效率
5.3 可视化分析
5.3.1 学习到的表示可视化
使用t-SNE可视化在KAIST验证集上提取的特征:
- 从头训练:类内分散,类间重叠严重
- ImageNet预训练:RGB分支特征较好,但热红外分支混乱
- 单模态MAE:两模态特征分布不一致
- M-SpecGene:类内紧凑,类间分离清晰,两模态对齐良好
结论:M-SpecGene学习到了更具判别性和模态一致性的表示。
5.3.2 注意力图分析
可视化最后一层Transformer的注意力权重:
- 单模态MAE:注意力分散,背景干扰多
- RGBT联合MAE:有一定目标关注,但两模态注意力不一致
- M-SpecGene:强烈聚焦于目标区域,背景被有效抑制,两模态注意力高度一致
结论:目标感知掩码策略引导模型学习以对象为中心的表示。
5.3.3 掩码重建质量
展示几组高难度场景的重建结果:
- 夜间低照度:RGB几乎全黑,模型成功从热红外推断出目标轮廓并重建RGB结构
- 强光过曝:RGB过曝丢失细节,重建时从热红外补充温度信息
- 遮挡场景:部分遮挡的目标被完整重建
结论:模型学会了跨模态互补,能在一个模态信息缺失时利用另一模态进行推理。
5.4 跨数据集泛化能力
在KAIST上预训练,迁移到其他数据集(零样本或少样本微调):
| 目标数据集 | 零样本mAP | 10-shot mAP | 全量微调mAP |
|---|---|---|---|
| FLIR | 51.2% | 68.7% | 76.4% |
| M3FD | 48.9% | 65.3% | 73.1% |
对比基线(ImageNet预训练):
- 零样本:M-SpecGene +15.3%
- 10-shot:M-SpecGene +8.9%
结论:M-SpecGene具有强大的跨数据集泛化能力,尤其在数据稀缺(零样本、少样本)场景下优势显著。
6. 讨论与分析
6.1 为什么CMSS度量有效?
CMSS的成功源于其理论简洁性与实践有效性的结合:
- 理论合理性:信息论角度,信息熵与像素方差存在关联;CMSS通过标准差近似捕获了信息密度差异
- 计算高效:无需复杂模型,单次前向计算即可获得
- 自适应性:不同场景、不同样本的CMSS值不同,允许样本级自适应掩码
然而,CMSS也存在局限:
- 仅考虑低层统计特征,未捕获高层语义信息
- 对噪声敏感,需预处理去噪
未来可探索基于深度特征的信息密度估计方法。
6.2 GMM建模的必要性
为什么不直接用CMSS线性映射到掩码比例?
GMM带来的优势:
- 非线性映射:CMSS与最优掩码比例关系可能非线性,GMM通过混合分量捕获复杂映射
- 鲁棒性:GMM对异常值不敏感,避免极端CMSS导致不合理掩码
- 可解释性:每个高斯分量可对应一类场景(如”RGB主导”、”平衡”、”热红外主导”)
消融实验证实,GMM相比简单线性映射提升约1.8%,验证了其必要性。
6.3 与特定任务方法的对比
M-SpecGene在多数任务上超过特定任务SOTA,但在某些任务上仍有差距(如显著性检测在某些指标上与最优方法持平)。原因分析:
优势来源:
- 通用表示:预训练学习的特征具有良好的可迁移性
- 数据增强:预训练利用了多个数据集,见过更多样化的场景
- 正则化效应:大规模预训练避免下游任务过拟合
仍存在差距的原因:
- 某些任务特定设计(如显著性检测的边界细化模块)在微调时未充分利用
- 预训练目标(重建)与某些任务目标(如跟踪的时序建模)存在gap
未来可探索多任务联合预训练或更任务相关的预训练目标。
6.4 计算效率分析
预训练开销:
- 800 epoch,8卡V100,约120小时
- 相比ImageNet预训练(300 epoch,约80小时)稍长,但考虑到多模态处理,开销可接受
下游微调开销:
- 各任务微调时间在2-8小时,与从头训练相当
- 推理速度:ViT-Base约35 FPS(单卡V100),满足实时性要求
与特定任务轻量级方法相比,M-SpecGene计算量较大,但通过一次预训练支持多任务,总体效率更高。
6.5 模态偏置的量化分析
为验证M-SpecGene确实缓解了模态偏置,设计以下实验:
方法:在测试时分别屏蔽一个模态,观察性能下降程度。若模型对某模态过度依赖,屏蔽该模态后性能将大幅下降。
| 方法 | 完整双模态 | 仅RGB | 仅热红外 | RGB下降 | 热红外下降 |
|---|---|---|---|---|---|
| 从头训练 | 72.4% | 68.1% | 51.2% | -4.3% | -21.2% |
| ImageNet预训练 | 76.9% | 73.5% | 54.7% | -3.4% | -22.2% |
| RGBT联合MAE | 79.8% | 75.2% | 59.6% | -4.6% | -20.2% |
| M-SpecGene | 83.7% | 77.3% | 71.9% | -6.4% | -11.8% |
观察:
- 所有基线方法在屏蔽热红外后性能暴跌20%+,而M-SpecGene仅下降11.8%
- M-SpecGene的RGB分支下降幅度反而更大(6.4% vs. 3-4%),说明模型更平衡地利用两模态
- 单独使用热红外时,M-SpecGene仍能达到71.9%,远超其他方法(51-59%),证明热红外分支被充分训练
结论:M-SpecGene成功实现了模态平衡,避免了对RGB的过度依赖。
7. 局限性与未来工作
7.1 当前局限性
预训练数据规模
相比单模态视觉(ImageNet 1.2M),RGBT数据仍较稀缺(~150K)。虽然GMM-CMSS提高了数据效率,但更大规模数据仍可能带来进一步提升。
计算成本
ViT架构的自注意力机制计算复杂度为 ,在高分辨率图像上开销较大。未来可探索线性复杂度的Transformer变体(如Linformer、Performer)。
CMSS度量的简化假设
当前CMSS基于像素标准差,未考虑语义信息。在某些极端场景(如单色背景 + 低温目标),CMSS可能失效。
预训练-微调gap
某些任务(如目标跟踪)需要时序建模,而预训练仅在静态图像上进行,导致迁移效果受限。
7.2 未来研究方向
7.2.1 扩展到更多模态
RGBT仅是多光谱视觉的一个子集,未来可扩展到:
- RGB-Depth-Thermal(三模态融合)
- 多光谱卫星图像(可见光 + 多个红外波段)
- 医学影像(CT + MRI融合)
GMM-CMSS框架可推广到多模态场景,为每对模态计算信息密度差异。
7.2.2 视频预训练
引入时序维度:
- 在RGBT视频数据上进行时空掩码建模
- 学习运动、遮挡、光照变化等时序模式
- 提升在目标跟踪、动作识别等视频任务上的性能
7.2.3 可学习的信息密度估计
用神经网络替代手工设计的CMSS:
- 端到端学习信息密度估计器
- 联合优化掩码策略与重建目标
- 自适应不同数据分布
7.2.4 轻量化与移动端部署
针对资源受限场景:
- 知识蒸馏:用M-SpecGene教师模型训练轻量学生模型
- 模型剪枝与量化
- 神经架构搜索(NAS)自动设计高效架构
7.2.5 开放世界泛化
当前模型在预定义类别上表现优异,但对开放世界(novel categories)的泛化能力有限。未来可探索:
- 零样本RGBT检测(结合视觉-语言模型如CLIP)
- Few-shot学习(元学习框架下快速适应新类别)
- 持续学习(不断吸收新数据而不遗忘旧知识)
8. 结论
本文提出M-SpecGene,首次尝试构建面向RGBT多光谱视觉的通用基础模型。针对RGBT数据的信息不平衡问题,创新性地提出跨模态结构稀疏性(CMSS)度量,并基于此设计GMM-CMSS渐进式掩码策略,实现灵活、平衡、以目标为中心的自监督预训练。
大规模实验证明,M-SpecGene在11个数据集和4类下游任务(目标检测、语义分割、显著性检测、目标跟踪)上均取得优异性能,超过任务特定设计的SOTA方法。更重要的是,M-SpecGene将此前分散的逐任务研究统一到一个预训练-微调范式下,为多光谱视觉研究提供了新的方向。
从方法论角度,M-SpecGene展示了如何针对物理多模态数据的特性(信息不平衡)设计自监督学习策略,这一思路可推广到其他多模态场景。从实践角度,M-SpecGene降低了RGBT应用的开发门槛——无需从头设计复杂融合架构,仅需在预训练模型上微调即可获得强大性能。
随着RGBT数据的持续积累和计算资源的提升,基础模型范式有望成为多光谱视觉的主流方案。未来工作将聚焦于扩展模态类型、引入时序建模、提升开放世界泛化能力,推动多光谱视觉向更通用、更鲁棒的方向发展。