【论文阅读 CVPR 2024 RSDet_去除再选择:一种用于 RGB - 红外目标检测的由粗到精融合视角】
[TOC]

题目:Removal then Selection: A Coarse-to-Fine Fusion Perspective for RGB-Infrared Object Detection
会议:Computer Vision and Pattern Recognition(CVPR)
论文链接:Link
代码(假开源):Zhao-Tian-yi/RSDet
年份:2024
1. 研究背景与动机
1.1 RGB–IR 目标检测的需求
传统目标检测大多依赖可见光(RGB)图像,在弱光、逆光、夜间、遮挡等复杂场景下容易失败。而红外(IR)图像通过热辐射信息可以在低照度环境下保持较好的目标轮廓,天然与 RGB 形成互补。因此,RGB–IR 联合检测被广泛用于:
- 智能监控、安全巡检
- 自动驾驶与无人系统
- 远程遥感、边防安防等
如何有效融合 RGB 与 IR 的互补特性,是多模态目标检测的核心问题之一。
1.2 现有融合策略及局限
现有 RGB–IR 检测方法主要采用以下两类融合策略(对应图 1 中 (a)(b)):
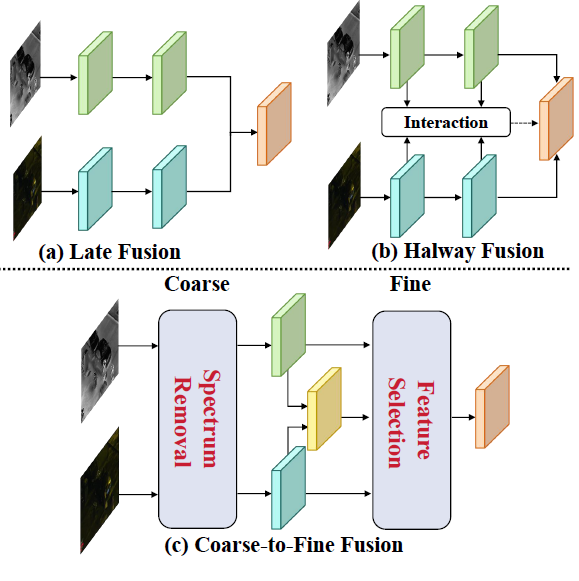
图 1. 现有 RGB–IR 特征融合结构与本文提出框架的对比。
Late Fusion(晚期融合)
- 独立提取 RGB、IR 特征
- 在检测头前对特征做简单相加或拼接
- 缺乏显式的跨模态交互,难以充分挖掘互补信息,性能较差
Halfway Fusion(中途融合)
- 在 backbone 中部或多尺度层面插入模态交互模块
- 如 MBNet、动态跨模态模块等,通过注意力或交互模块增强两模态的互补性
- 这类方法显式建模互补信息,但基本忽略了各模态内部大量冗余特征的负面影响
关键问题:
大多数方法只关注“如何更好地融合”,而没有首先解决“要融合的内容本身是否已经被净化”。冗余信息在传播过程中会不断放大,导致跨模态互补学习受到干扰,融合结果难以充分发挥两模态优势。
1.3 认知启发:由粗到细的信息处理
人类大脑在处理多模态信息时,往往遵循“先粗后细”的选择性注意过程:
- 粗:对输入信息做初步筛选,抑制明显无关或噪声信息
- 细:在剩余信息上进行精细分析与选择,提取当前任务所需的关键信息
Treisman 的衰减模型(Attenuation Theory)认为,信息在进入工作记忆之前,会先经过一层“衰减滤波”,无关信息被强烈抑制,有关信息则以较高强度保留下来,用于进一步精细加工。
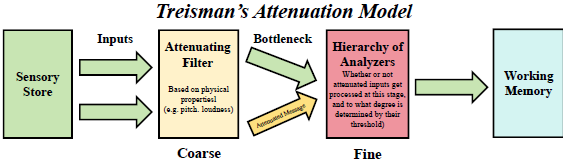
图 4. Treisman 衰减模型示意图。
作者借鉴这一认知过程,将其映射到 RGB–IR 特征融合上,提出**“由粗到细”(Coarse-to-Fine)特征净化与融合视角**:
- Coarse(粗):在频域粗粒度去除模态内部冗余光谱信息
- Fine(细):在特征域通过专家混合机制精细选择不同尺度的有用模态特征
1.4 论文主要贡献
结合引言与方法部分,论文的主要贡献可概括为:
提出由粗到细的 RGB–IR 特征融合视角
先在频域对各模态进行冗余光谱去除,再在特征层面进行动态特征选择,从认知角度解释多模态融合的流程。
冗余光谱去除模块(RSR)
在频域对图像幅度谱进行动态滤波,抑制模态内的冗余、高频噪声成分,保留与检测任务相关的有效频段。
动态特征选择模块(DFS)
引入**尺度感知专家混合(mixture of scale-aware experts)**结构,通过门控网络与路由器在多尺度 RGB–IR 特征之间进行动态路由,实现跨模态、跨尺度的精细特征选择。
构建 先去除后选择检测器 Removal then Selection Detector(RSDet)
将“去除–选择”的由粗到细融合策略嵌入 Faster R-CNN,形成完整检测框架,并在 KAIST、FLIR-aligned、LLVIP 三个公开数据集上取得新的 SOTA 性能,特别是在小目标、严重遮挡与极低照度场景下优势明显。
2. 方法概览:由粗到细融合策略
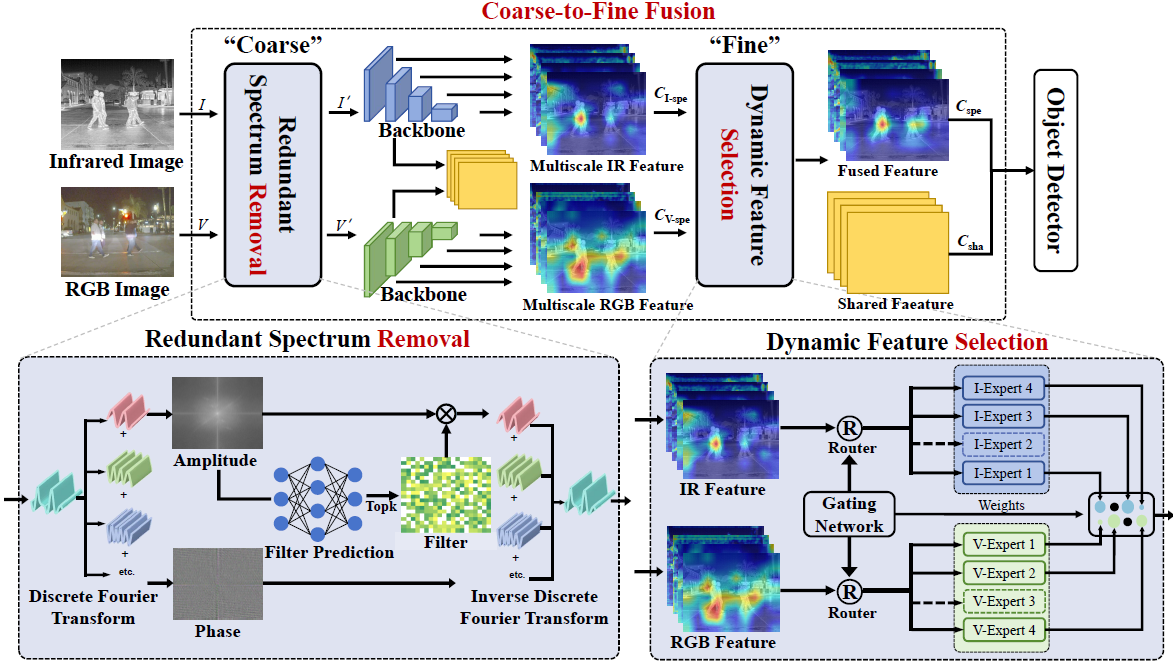
图 3. 由粗到细融合策略的整体框架。上半部分为整体流程,下半部分分别展示 RSR 与 DFS 两个核心模块。
2.1 整体流程
给定一对配准好的 RGB 图像 和红外图像 ,RSDet 的整体流程如下:
频域冗余去除(RSR,粗)
- 将 经离散傅里叶变换(DFT)映射到频域:
- 基于幅度谱预测模态自适应的动态滤波器
- 在频域进行逐点相乘抑制冗余光谱,逆变换回空间域,得到“净化后”图像
共享–特定表示学习
- 以 ResNet 为 backbone,引入共享–特定(Shared–Specific)结构:
- 共享分支:提取模态无关的共享特征
- RGB 特定分支:从 提取模态特定特征 (多尺度)
- IR 特定分支:从 提取模态特定特征 (多尺度)
- 以 ResNet 为 backbone,引入共享–特定(Shared–Specific)结构:
动态特征选择(DFS,细)
- 将多尺度模态特定特征 送入 DFS 模块
- DFS 通过尺度感知专家混合(MoE)和路由器,在不同尺度上选择更可靠的模态特征,得到融合后的模态特定特征
最终融合特征
- 将 DFS 输出的特定特征 与共享特征 相加,得到最终融合特征:
该融合特征 随后被送入标准的目标检测头(RPN + R-CNN)进行检测。
2.2 Coarse vs. Fine 的直观对比
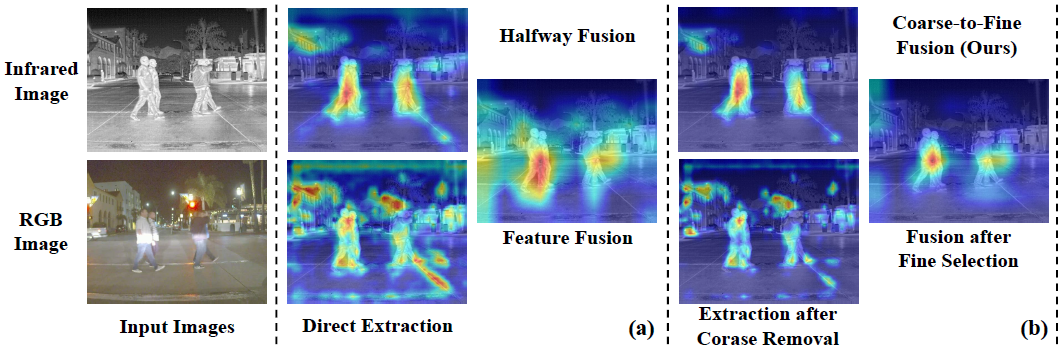
图 2. 由粗到细融合方法的有效性示例。
(a) 传统 Halfway Fusion:RGB 背景噪声抑制了最终融合特征;
(b) 本文方法:先去除冗余光谱,再在特征层面选择有用模态信息。
- 在 Halfway Fusion 方案中,网络直接对原始 RGB–IR 特征做交互,RGB 中大量背景干扰信息会被传播到最终的融合特征中。
- 在 RSDet 中,RSR 模块在频域优先抑制掉部分背景与高频噪声,再由 DFS 从“已经净化的模态特征”中选择任务相关的尺度与模态,从而显著提升检测质量。
3. 冗余光谱去除模块(RSR)
3.1 设计动机
- 图像中的冗余信息不仅存在于空间域,也体现在频域谱分布上。
- 频域具有天然的全局建模能力:通过逐点乘法即可在整幅图上统一抑制某一频段特征。
- 直接在空间域做粗粒度过滤较难解耦目标与背景的紧耦合特征,而在频域中通过滤波器可以更直接地削弱某些频率构成的干扰。
因此,作者提出在频域设计一个动态光谱滤波器,自适应去除 RGB 与 IR 模态内部的冗余成分。
3.2 频域变换与幅度编码
给定 RGB 图像 与 IR 图像 ,首先对其进行离散傅里叶变换(DFT):
其中 可分解为幅度谱与相位谱。RSR 模块只利用幅度信息预测滤波器,而保留相位信息,以尽量不破坏图像结构。
对于两种模态,分别设计轻量编码器 对幅度谱进行编码,得到嵌入向量:
- 中的每个元素可视为某块区域频谱的重要性评分。
- 这一步将二维频域图划分为若干 patch,并映射到一维评分空间。
3.3 Top-K 与软 / 硬滤波器
为了在保留有效谱成分的同时抑制冗余信息,引入 Top-K 操作选出最重要的频谱区域:
根据 Top-K 之外元素的处理方式,滤波器分为两类:
软滤波器(Soft Filter):
- 非 Top-K 元素被压缩到 范围内,而非直接置零
- 能在抑制冗余的同时避免信息完全丢失,表现更稳定
硬滤波器(Hard Filter):
- 非 Top-K 元素直接置为 0
- 更激进,可能带来更强的噪声抑制,也更容易损失细节
在实验中,作者在 FLIR 数据集上比较了不同 K 与滤波器类型的组合,发现当 软滤波器 + 时获得最优性能(见表 III)。
将一维嵌入通过最近邻插值重塑回频域尺寸,得到滤波器:
图 5 给出了学习到的滤波器与滤波后幅度谱的可视化示例:

图 5. 学习到的滤波器 、 以及滤波前后幅度谱与图像的可视化。
可以观察到滤波器主要抑制了部分高频噪声区域,而目标区域幅度变化较小。
3.4 频域滤波与逆变换
得到滤波器后,在频域进行逐元素相乘:
随后通过逆离散傅里叶变换(IDFT)返回空间域,得到经过冗余光谱去除的图像:
中间结果的可视化表明:
- 目标区域在 RSR 处理前后变化极小
- 被抑制的信息主要集中在背景区域
- 图像整体信噪比(SNR)有所提升

图 7. RSR 模块在 FLIR(左)与 LLVIP(右)数据集上的中间输出可视化。绿色框为目标,红色框为背景,可见背景区域被显著模糊化而目标保持清晰。
4. 动态特征选择模块(DFS)
4.1 设计思路:尺度感知专家混合
在完成频域粗过滤后,RGB 与 IR 特征仍然存在以下难点:
- 不同尺度目标在两模态中的显著性差异较大
- 某些尺度上 RGB 更可靠,另一些尺度上 IR 更可靠
- 简单相加或注意力往往难以同时处理多尺度 + 多模态 + 动态路由
DFS 的核心思想是:
在每一个尺度上,构建一组针对该尺度的RGB 专家与IR 专家,通过门控网络 + Router 实现对不同模态特征的动态选择,形成尺度感知的 MoE 结构。

图 6. 各尺度专家输出特征与融合特征的可视化。不同专家关注不同尺度的目标,融合后的 对目标区域具有更强响应。
4.2 门控网络:从全局统计到权重分配
对经过 backbone 提取的多尺度模态特定特征 (尺度索引为 ),首先做全局平均池化并展平:
门控网络 将两个模态的统计特征拼接后映射到权重空间,并通过 Softmax 得到规范化权重:
- 为可学习参数, 为专家数量(按尺度划分)。
- 反映该尺度下 IR / RGB 特征的重要性。
4.3 路由器:门控到二值路由
为了在保持可训练性的同时提高决策清晰度,引入阈值路由器 将连续权重转化为“使用 / 不使用”二值门控:
- 若两模态权重均高于阈值 ,则同时保留
- 若一方低于阈值,则仅保留权重较高的一方
- 这样既可以突出主导模态,又避免完全忽略另一模态的有用信息
4.4 尺度感知专家网络与融合
对每个尺度与每个模态,构建小型专家网络 (由两个卷积块组成),对门控后的特征进行进一步变换:
最终,将所有尺度的专家输出按权重进行加权求和并级联,得到多模态特定融合特征 :
从图 6 的可视化可见:
- 不同专家聚焦不同尺度目标(从小物体到大物体)
- 每个专家依据当前场景在 RGB / IR 中选择更可靠的模态特征
- 最终融合特征在目标区域呈现更清晰、更集中的响应,背景抑制更好
5. 去除与选择检测器(RSDet)
5.1 与 Faster R-CNN 的集成
RSDet 在检测框架上采用标准的两阶段检测器 Faster R-CNN,主要改动在 backbone 特征提取部分:
- 用“RSR + Shared–Specific + DFS” 替代原有单模态 ResNet backbone
- RPN、RoI Pooling / RoIAlign、R-CNN 头部结构均保持不变
因此,RSDet 可看作在特征层面进行多模态由粗到细融合的通用模块,与主流两阶段检测框架兼容性较好。
5.2 共享–特定表示与互信息损失
为显式区分模态共享信息与模态特定信息,作者引入共享–特定表示学习,并通过互信息(Mutual Information, MI)损失进行监督:
- 共享特征:
- IR 特定特征:
- RGB 特定特征:
通过最大化共享特征与各模态特定特征之间的互信息,鼓励:
- 共享分支捕获两模态共同信息
- 特定分支在保留共享部分的基础上学习模态专有差异
互信息损失定义为:
在具体实现中,作者利用交叉熵(CE)与 KL 散度(KL)对互信息进行近似最大化:
5.3 总体损失函数
检测部分采用与 Faster R-CNN 相同的损失:
- RPN 损失:
- 边界框回归损失:
- 分类损失:
最终总损失为:
其中 为互信息项与检测项之间的平衡系数。
6. 实验设置
6.1 数据集
KAIST 多光谱行人检测数据集
- 原始数据集标注存在问题,后续工作对训练集与测试集标注进行了修正
- 训练集:8,963 对 RGB–IR 图像对
- 测试集:2,252 对图像对(使用改进标注)
- 划分设置:
- 尺度:near / medium / far(按行人高度分段)
- 遮挡:none / partial / heavy
- 光照:day / night
- 评估设置:All / Reasonable(本文采用更具挑战性的 All 设置)
FLIR-aligned 数据集
- 含昼夜场景的 RGB–IR 配对图像,原始 FLIR 数据存在配准误差,故使用对齐版本
- 图像对总数:5,142
- 训练:4,129
- 测试:1,013
- 类别:person / car / bicycle(原始“dog”类实例过少,已在清理过程中移除)
LLVIP 低光多模态检测数据集
- 严格配准的 RGB–IR 配对数据,场景多为极暗、低照度环境
- 图像对总数:15,488
- 训练:12,025
- 测试:3,463
6.2 评估指标
对数平均漏检率
- 用于 KAIST 数据集
- 在 9 个对数均匀采样的 FPPI(每图像假阳性数)点上计算平均漏检率
- 数值越低表示性能越优
平均精度均值(mAP)
- 用于 FLIR-aligned 与 LLVIP 数据集
- :IoU=0.5 时三类的平均 AP
- :IoU 从 0.5 到 0.95(步长 0.05)上的平均 AP
6.3 实现细节
- 实现平台:mmdetection 工具箱,GPU 为 NVIDIA GeForce RTX 3090
- 检测框架:Faster R-CNN,backbone 为 ResNet-50
- 优化器:SGD,动量 0.9,权重衰减
- 训练策略:
- FLIR-aligned & KAIST:训练 12 epoch,初始学习率
- LLVIP:初始学习率
- 输入分辨率:为了方便 DFS 模块设计,将各数据集图像分辨率统一为 LLVIP 的分辨率
- 数据增强:仅使用概率 0.5 的随机水平翻转,未使用复杂增强策略
7. 消融实验与可视化分析
7.1 模块级消融:RSR 与 DFS 的贡献

表 I. 在 FLIR、LLVIP(mAP,%)及 KAIST(,%)上的模块消融实验结果(IoU=0.7)。
- 单独引入 RSR:
- 在三数据集上均取得稳定提升,证明频域去冗余的有效性
- 单独引入 DFS:
- 在多尺度、多模态融合方面带来更明显的增益
- 同时使用 RSR + DFS(完整 RSDet):
- 在所有指标上表现最佳
- 说明“先去除再选择”的级联是相互增益的,而非简单叠加
7.2 DFS 与其他融合模块的比较

表 II. 在 FLIR 数据集上的融合模块对比(统一 Faster R-CNN + ResNet-50,公平设置)。
- 基线:Two-Stream Faster R-CNN(简单特征相加)
- 对比方法:CMX、CFT 等代表性 RGB–X / RGB–IR 融合模块
- 结果表明:
- DFS 相比 Two-Stream 仅增加约 3.91M 参数,却带来 的显著提升
- 与第二优融合方法相比,参数减少约 2.37 亿,FLOPs 降低 93G,但在 、、mAP 上仍保持优势
- 说明 DFS 在性能–复杂度折中上具有良好优势
7.3 RSR 滤波器设计:硬 / 软滤波与 K 值
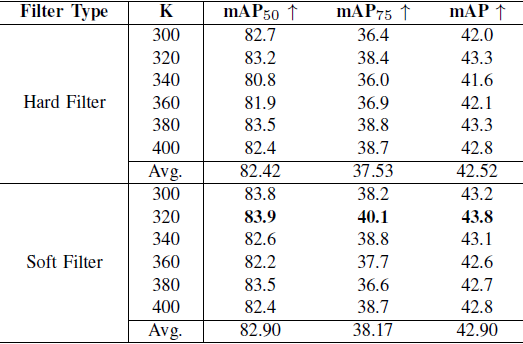
表 III. RSR 中不同滤波器类型与 Top-K 值在 FLIR 数据集上的对比。
- 当 时等价于“不过滤”(图像被划分为 400 个 patch)
- 在不同 K 下,软滤波器的整体 mAP 均略优于硬滤波器
- 最优配置为:软滤波器 +
- 平均性能(Avg. mAP)也表明软滤波器在稳定性方面更具优势
7.4 中间结果可视化
7.4.1 RSR 模块:目标与背景的差异
如图 7 所示(见第 3 节),RSR 模块主要作用于背景区域,使背景变得更加模糊或均匀,而目标区域基本保持不变。SNR 的定量分析进一步证明 RSR 能提高信噪比,对检测任务有积极作用。
7.4.2 共享、特定与融合特征

图 8. DFS 模块在 FLIR 数据集上的特征融合可视化结果。特征被叠加在原始图像上。
- :共享特征
- :IR 特定特征
- :RGB 特定特征
- DFS 输出的融合特征在目标区域显著增强,且部分原本在共享特征中不显著的目标被凸显出来。
7.4.3 t-SNE:RSR 对特征解耦的影响
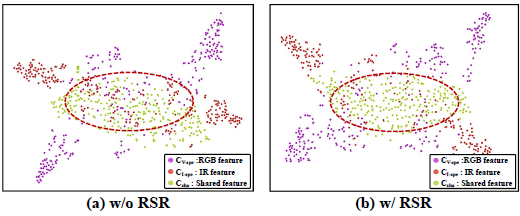
图 9. t-SNE 可视化:有 / 无 RSR 时共享与特定特征的分布差异。
- 无 RSR:共享特征与模态特定特征在嵌入空间中混合程度较高,DFS 难以从中筛选特定模态所需信息
- 加入 RSR 后:混合区域数量明显减少,特征簇之间的可分性增强,有利于 DFS 进行更精确的动态特征选择
8. 与最先进方法的比较
8.1 KAIST 数据集(行人检测)
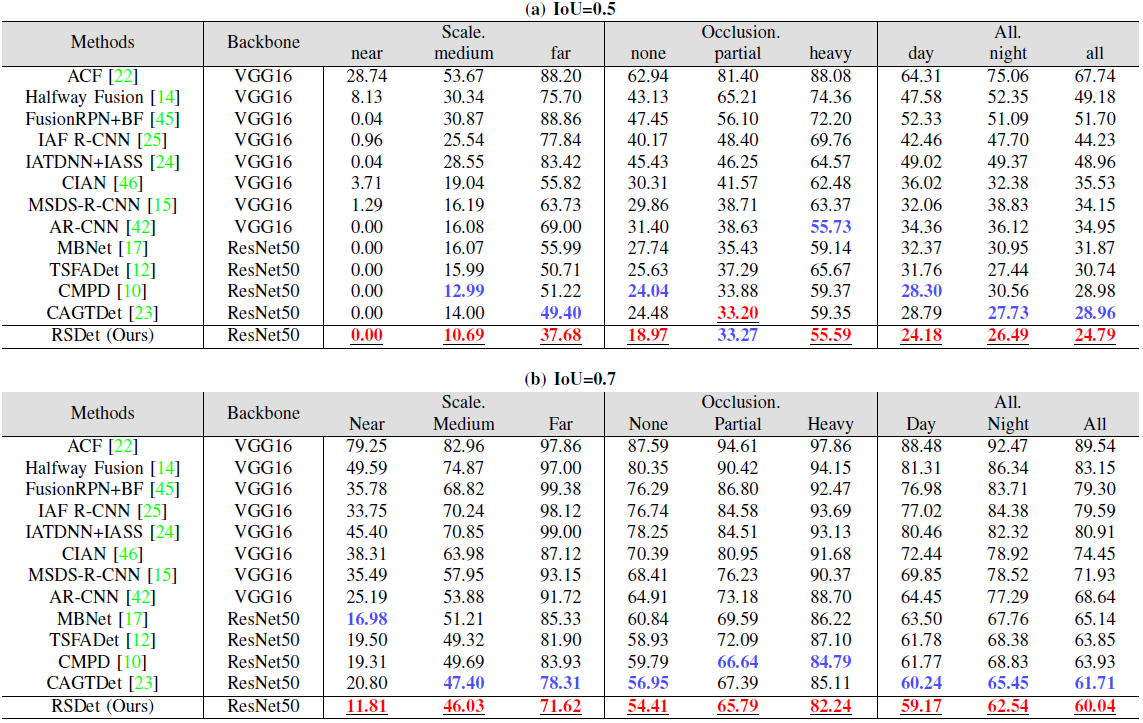
表 IV. KAIST 数据集 “All” 设置下不同尺度、遮挡程度与光照条件的 (%,IoU=0.5 与 0.7)。
在 IoU=0.5 下:
- RSDet 在 All / Day / Night 三个总体设置上均取得最优漏检率
- 在 near / medium / far、none / heavy 等绝大多数子集上表现最好
- 尤其在 far 子集上,相比第二优方法约提升 11.72%,说明其对远距小目标具有显著优势
在 IoU=0.7 下:
- 所有方法在 near 子集下原本 ,随着 IoU 提升,漏检率均有上升
- 其他方法漏检率上升区间约为 16.98%–25.19%,而 RSDet 仅上升 11.81%,显示更高定位精度与鲁棒性
MR–FPPI 曲线(图 10)进一步表明:
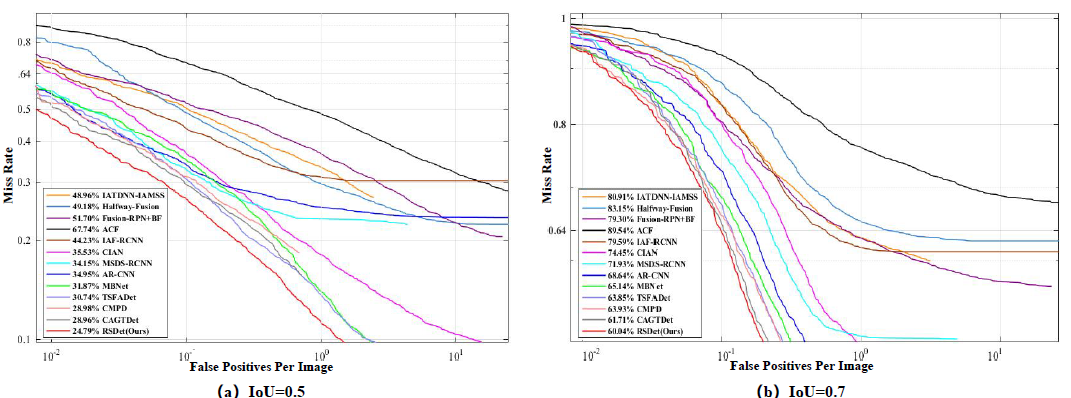
图 10. KAIST “All” 设置下 RSDet 与其他方法的 MR–FPPI 曲线对比。
- RSDet 在全范围内拥有最低的漏检率曲线
- 在低 FPPI 区域仍能保持显著优势,兼顾高精度与低误检
- 曲线较为平滑,说明模型在不同阈值下表现稳定
8.2 FLIR 数据集
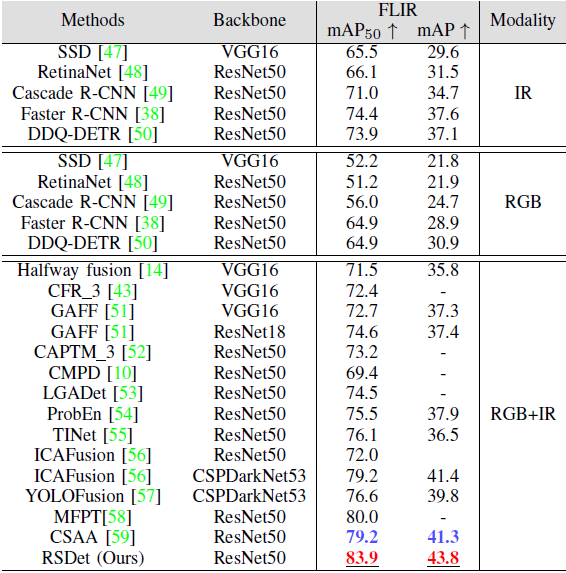
表 V. FLIR 数据集上不同方法的 与 mAP 对比。
- 单模态 RGB / IR 方法整体性能低于多模态融合方法
- RSDet 在 RGB–IR 方法中取得 83.9% 与 43.8% mAP:
- 比第二优 RGB–IR 方法分别高出约 4.7%()与 2.5%(mAP)
- 说明由粗到细融合策略在城市交通等复杂场景中具有明显优势
8.3 LLVIP 数据集(低光条件)
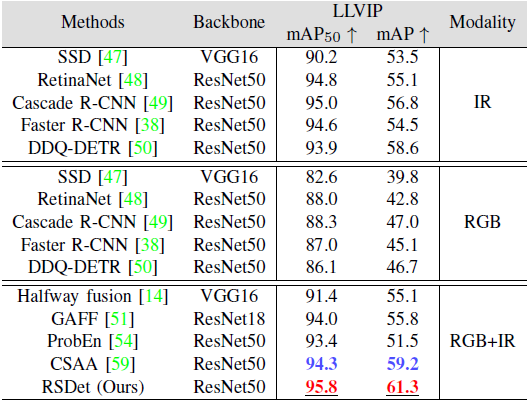
表 VI. LLVIP 数据集上不同方法的性能对比(mAP,%)。
在 LLVIP 极低照度场景中,通常出现以下现象:
- RGB 模态质量显著下降,RGB–IR 融合方法反而受到 RGB 噪声干扰
- 许多现有 RGB–IR 方法性能甚至不如单 IR 模态检测器
RSDet 在 LLVIP 上实现:
- ,mAP = 61.3%
- 相比第二优 RGB–IR 方法,分别提升 1.2% 与 2.1%
这说明:
- RSR 有效抑制了低质量 RGB 特征对 IR 的干扰
- DFS 能够在低照度条件下更倾向于选择 IR 特征,从而稳定提升多模态检测性能
9. 总结与思考
9.1 方法优点
认知理论支撑的由粗到细融合视角
- 将 Treisman 衰减模型中的“先衰减后精细加工”映射到多模态特征融合流程,提供了较为明确的理论动机。
频域冗余光谱去除(RSR)的可解释性与通用性
- 操作于输入图像层面,与下游检测器结构解耦,具有较好的可插拔性。
- 滤波器可视化与 SNR 指标均表明其主要抑制背景与噪声,而尽量保留目标区域。
动态特征选择(DFS)的尺度感知能力
- 通过门控网络 + Router + 专家混合,在多尺度、多模态上实现动态路由,能够显式选择更可靠的模态与尺度。
- 相比复杂的跨模态注意力模块,DFS 在参数量与 FLOPs 上更为经济,性能–效率折中良好。
共享–特定表示与互信息约束
- 引入显式的共享–特定分解,有助于避免模态特定信息被过度“平均化”,保留 RGB 与 IR 的互补优势。
实验验证充分
- 在三大主流 RGB–IR 检测数据集(KAIST、FLIR-aligned、LLVIP)上均取得 SOTA 性能。
- 消融实验、滤波器设计比较、可视化分析较为完整,支持提出方法各组件的有效性。
9.2 可能的局限与改进方向
频域操作的计算与实现复杂度
- RSR 需要对整幅图像进行 DFT/IDFT 操作,虽然在当前分辨率下仍可接受,但在更高分辨率或实时系统中可能成为瓶颈。
- 后续可探索局部频域变换或可学习的小波/变换替代,降低计算开销。
滤波器粒度与自适应性
- 当前滤波器以固定 patch 划分与 Top-K 选择为主,仍然较为粗糙。
- 可尝试引入任务自适应的频率划分或更细粒度的频域注意机制,以捕获更复杂的细节差异。
与 Transformer / 单阶段检测器的兼容性
- 论文主要在 Faster R-CNN + ResNet-50 框架下验证。
- 在通用性方面,可进一步探索与 Transformer-based 检测器(如 DETR 系列)或单阶段检测器的结合效果。
路由机制与阈值超参数
- DFS 中的阈值 需人工设定,不同数据集可能需要调节。
- 后续可考虑引入可学习阈值或连续门控(如 Gumbel-Softmax)以减轻手工超参数依赖。
扩展到更多模态与任务
- 当前工作聚焦于 RGB–IR 双模态目标检测。
- 从方法本身看,RSR 与 DFS 的设计具有一定通用性,潜在可扩展到 RGB–Depth、SAR–Optical 甚至多模态语义分割、跟踪等任务,值得进一步研究。
10. 小结
本文提出的 RSDet 从“先在频域去除冗余信息,再在特征域进行动态选择”这一由粗到细的视角重新审视 RGB–IR 特征融合,分别在输入层与特征层引入 RSR 与 DFS 两个关键模块,并结合共享–特定表示学习与互信息损失,构建了一套完整且具有解释性的多模态检测框架。大规模实验结果表明,该方案能够有效抑制模态冗余、增强互补融合,在高难度场景下显著优于现有方法,为后续多模态检测与多模态频域建模提供了有价值的思路。