【论文阅读 | Inf. Fusion 2025 | MS2Fusion:多重光谱状态空间特征融合】
[TOC]

题目:Multispectral State-Space Feature Fusion: Bridging Shared and Cross-Parametric Interactions for Object Detection
期刊:Inf. Fusion(Information Fusion)
论文链接:Link
关键词:Multispectral Object Detection(多光谱目标检测), State Space Model(状态空间模型), Shared-Parameter(共享参数), Cross-Parameter Interaction(跨参数交互).
代码:GitHub
年份:2025
摘要
现代多光谱特征融合用于目标检测面临两个关键限制:
- 过度偏好局部互补特征而非跨模态共享语义,这对泛化性能产生不利影响;
- 感受野大小与计算复杂度之间的权衡,成为可扩展特征建模的关键瓶颈。
感受野大小:模型中单个神经元(或特征图上的单个像素)在原始输入图像上能够 “感知” 到的区域大小
为解决这些问题,基于状态空间模型(SSM),提出了一种新颖的多光谱状态空间特征融合框架,称为MS2Fusion,该框架通过双路径参数交互机制实现高效且有效的融合。
具体而言:
第一个交叉参数交互分支继承了交叉注意力在挖掘互补信息方面的优势,并结合了SSM中的跨模态隐藏状态解码;
第二个共享参数分支通过SSM中的参数共享,利用联合嵌入探索跨模态对齐,以获取跨模态的相似语义特征和结构;
最后,对这两条路径进行联合优化。通过SSM在统一框架中融合多光谱特征,使MS2Fusion能够兼具功能互补性和共享语义空间。
得益于双分支SSM的设计,MS2Fusion同时继承了计算效率和全局感受野,显著提升了多光谱目标检测的性能。实验表明,MS2Fusion在强大的基线模型上持续表现更优:
- 在目标检测(FLIR)中,mAP@0.5提升了3.3%;
- 在RGB-T语义分割(MFNet)中,mIoU提高了2.8%;
- 在显著目标检测(VT5000)中,MAE降低了0.7%。
值得注意的是,无需进行特定任务的修改,MS2Fusion就在多个多光谱感知任务上取得了新的最先进结果,展现出卓越的泛化能力。
引言
多光谱目标检测优势
近年来多光谱目标检测得到了越来越多的关注,这得益于其通过融合多个光谱波段(如RGB和热波段(即IR))的信息所实现的鲁棒性能。
单模态缺陷
RGB图像通常具有高分辨率,颜色丰富和纹理特征细腻的特点。但在弱光、恶劣天气或遮挡等复杂场景下,其性能会急剧下降。相比之下,热图像能够有效克服这些环境限制,但在颜色和纹理细节方面存在明显不足。当前通用的单模态目标检测方法难以很好地应对上述挑战。然而,多光谱特征融合为在这类具有挑战性的条件下提供可靠的目标检测解决方案开辟了道路。

图1:RGB图像(左)和热成像图像(右)的优缺点;(a)两种模态提供互补信息,它们的融合能够实现更稳健的目标检测;(b)双模态共享特征变得至关重要,因为两种模态中没有一种具有绝对优势。(例如,纹理和热辐射等模态特定特征变得模糊,而物体轮廓和结构等跨模态一致特征有助于检测)
如图1a所示,现有研究普遍认为,当一种模态不足时,互补特征发挥着关键作用。例如,当热成像物体缺乏清晰轮廓时,RGB图像能提供具有区分性的颜色和纹理线索;而当RGB成像受到低光照或遮挡影响时,热成像图像则能提供热特征。
然而,如图1b所示,在两种模态均表现出较弱区分性特征的场景中(例如,RGB图像中的纹理模糊和热成像图像中的低对比度),仅靠互补信息无法解决问题。在这些情况下,跨模态一致的形状和结构模式等共享特征变得至关重要,因为它们能够捕捉模态不变的表征,以实现可靠的检测。因此,作者推测,一个强大的多光谱目标检测框架应该动态地利用互补特征和共享特征,以应对各种来自现实世界的挑战。
互补特征:指不同光谱模态(如 RGB 与热成像)各自具备、可相互补充的独特信息。
共享特征:不同光谱模态间共有的、具备模态不变性的信息,通常对应物体的通用语义或结构属性,如物体的轮廓、形状、整体结构等。
先前研究的不足
先前的研究主要集中于跨模态的互补特征学习,往往忽视了对模态间共享特征表示或固有结构相似性的探索。
概括:重互补而轻共享,导致了泛化能力不足
此外,现有方法通常采用单一的融合策略来直接组合多模态输入,忽略了自适应或分层融合机制的潜在优势。这些方法没有充分探索或利用跨模态共享特征,忽视了提升单模态特征性能的潜在作用。这种融合模式在跨模态整合过程中常常会压制较弱但具有判别性的特征,导致大量信息丢失。
概括:融合策略单一,没有自适应机制
对于多光谱目标检测而言,共享特征表示在多模态融合中起着关键作用。它不仅能减轻跨模态差异,还能增强单模态特征,从而在复杂环境中显著提高特征表达能力和检测鲁棒性。
CNN与Transformer之缺陷
大多数主流方法采用CNN或Transformer进行特征融合。尽管这些方法有效,但现有的基于CNN的方法由于感受野有限,往往难以捕捉跨模态的更广泛上下文信息。另一方面,尽管基于Transformer的方法在建模全局依赖关系方面表现出色,但随着输入序列变长,其性能可能会下降,并且随着模型复杂度的增加,计算成本也会更高。这些因素限制了它们在资源受限环境中的实用性,凸显了在多光谱目标检测中需要更高效的融合策略。
概括:感受野有限,上下文有限,输入越大性能越低
现阶段状况
多光谱目标检测领域近年来取得了一些进展,但现有方法仍主要侧重于学习跨模态的互补特征,忽视了对共享特征表示和固有结构相似性的探索。
大多数现有方法采用单一且直接的融合策略,这往往会抑制具有辨别力但较弱的特征,并导致大量有效信息丢失。
基于CNN的方法在捕捉跨模态上下文时受限于感受野,而基于Transformer的技术则存在计算效率低下的问题,且在处理长序列时性能会下降。
在语音识别和图像压缩中,特征表示的效率直接决定了系统性能——这一原则同样适用于多光谱检测。因此要增强系统性能即需要提高特征表示的效率。
这些局限性凸显了对一种更具适应性和效率的融合范式的需求,这种范式不仅要弥合模态差异,还要通过共享表示增强单模态特征,最终提高在复杂环境中的鲁棒性。
MS2Fusion的提出
序列建模领域的最新进展表明,基于SSM的方法通过将特征压缩为紧凑的隐藏状态而表现出色,能够以恒定时间进行全序列处理,实现高效推理。Mamba通过选择性状态空间增强了这一点,动态保留与任务相关的特征。Vision Mamba(Vim)进一步证明了其在视觉任务中的有效性,同时提升了效率和性能。
序列建模领域:专注于处理具有时序或空间顺序数据(如文本序列、图像像素序列、多模态特征序列等)的技术领域,其核心目标是通过建模数据间的顺序依赖关系,实现对数据特征的有效提取、压缩与利用。
受此启发,本文作者提出了MS2Fusion,这是一个新颖的框架,它能同时利用跨模态的互补特征和共享特征,同时克服卷积神经网络(CNN)和Transformer在多光谱特征融合方面的局限性。
MS2Fusion的优势体现
据图分析
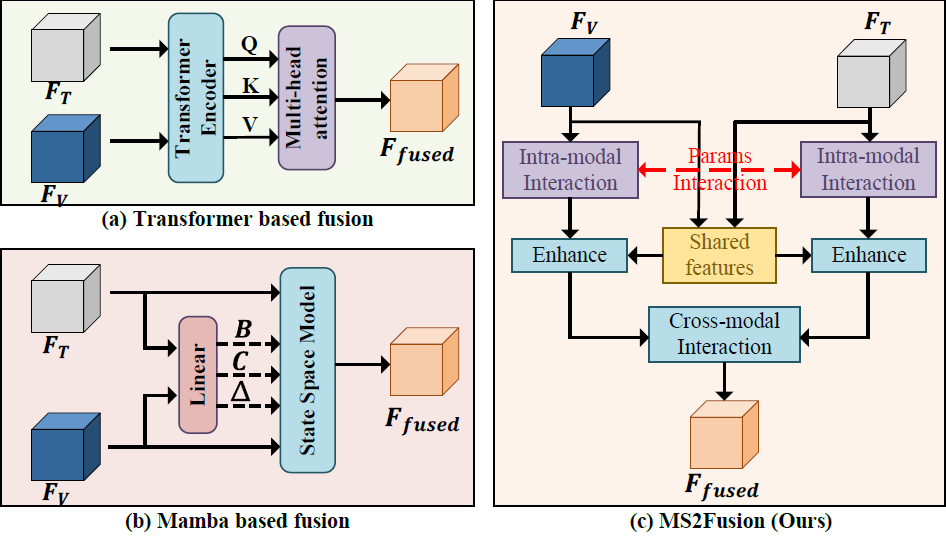
这张图比较三种多模态特征融合方法 (主要用于红外图像 () 与可见光图像 () 的融合):
(a) Transformer-based fusion
- 原理:将 () 和 () 输入到 Transformer 编码器,通过 多头注意力机制 (Multi-Head Attention) 实现信息交互。
- 特点:能有效捕捉两种模态的互补特征,但计算开销较大。
- 优点:融合充分,性能较好。
- 缺点:注意力机制成本高,且可能对对齐和噪声敏感。
(b) Mamba-based fusion
- 原理:直接将 () 和 () 输入线性层生成状态空间模型 (SSM) 的参数 (, , )。
- 特点:融合过程简洁,但缺乏细粒度的模态交互。
- 缺点:容易出现模态错位(misalignment)与特征冗余(redundancy)。
模态错位(misalignment):不同模态(例如红外图像和可见光图像)之间信息不对应、空间或语义不对齐的情况。两种模态“看”的不是同一个位置或语义点,融合错了对象。
特征冗余(redundancy):指不同模态中存在重复或相似的特征信息,导致融合后的表示中有大量“重复内容”。即两种模态提供了“重复的信息”,融合后没增加有效信息量,反而增加噪声。
(c) MS2Fusion(作者提出的方法)
步骤:
- 对每个模态内部先进行 Intra-modal Interaction(模态内交互) → 加强自身特征;
- 提取 Shared features(共享特征);
- 再进行 Cross-modal Interaction(模态间交互) → 实现深层融合;
- 输出统一融合特征 ()。
特点:通过先内后外的双层交互机制(模态内→模态间),获得更好的模态对齐与特征统一。
优势:融合更稳健、信息更充分,减少特征重复与模态偏差。
简单总结:Transformer融合注重全局注意力、Mamba融合侧重线性高效计算,而MS2Fusion通过“模态内增强 + 模态间共享”双阶段策略,实现了更精确、鲁棒的多模态特征融合。
通过本图2与实验数据即可得出MS2Fusion的优势
图2显示,基于Transformer的方法(a)和现有的Mamba解决方案(b)未能充分利用跨模态共享特征。相比之下,MS2Fusion方法(c)通过三个关键组件明确地对互补性和共享性的跨模态交互进行建模:
- 跨参数状态空间模型 (CP-SSM):通过在特定模态的状态空间之间交换输出矩阵来促进隐式的特征互补,从而在保留特定模态特征的同时实现跨模态特征丰富;
- 共享参数状态空间模型 (SP-SSM):通过参数共享学习一个统一的特征空间,对齐异构模态分布,以提取能够增强单一模态特征的、有区别性的共享表示;
- 特征融合状态空间模型 (FF-SSM):引入一种双向输入机制以扩展状态空间的有效感受野 (ERF),在减轻特征衰减的同时,实现跨模态信息的自适应融合。
有效感受野分析(ERF)也可表明MS2Fusion有效性

图3:基于CNN的融合方法(a)、基于Transformer的融合方法(b)以及所提出的MS2Fusion方法(c)的有效感受野可视化对比。定量分析表明,与其他方法相比,MS2Fusion实现了显著更广泛的感受野覆盖。
由图3可得知,与CNN和Transformer相比,MS2Fusion实现了更出色的空间覆盖范围,成功地将局部细节与全局语境相结合。
简单来说,MS2Fusion模块在保持高计算效率的同时,有效解决了CNN在建模长距离依赖关系方面的限制。实验表明(依据下表数据),与Transformer和CNN基线相比,MS2Fusion均能以更低的计算成本和参数量实现更高的检测精度(mAP50分别提升8.3和9.0个点),且处理速度与CNN相当,远快于Transformer。这些证据表明MS2Fusion成功打破了多光谱目标检测中传统的效率-精度权衡,确立了新的SOTA性能。
表1:不同多光谱特征融合方法的比较(YoloV5框架,FLIR数据集)
| 模型 | GFLOPs | Params (M) | FPS | mAP@0.5 | mAP@0.75 | mAP |
|---|---|---|---|---|---|---|
| CNN | 190.3 | 159.7 | 30.8 | 74.3 | 23.8 | 32.5 |
| Transformer | 421.9 | 440.6 | 19.2 | 75.0 | 24.1 | 33.4 |
| MS2Fusion | 140.8 | 130.3 | 29.7 | 83.3 | 33.0 | 40.3 |
MS2Fusion的优势来源
MS2Fusion引入了一种新颖的状态空间框架。其CP-SSM捕捉了隐含的特征互补性,而SP-SSM增强了共享表示,在特定模态学习和跨模态学习之间实现了最佳平衡。
出于将全局上下文建模与计算效率相结合的需求,FF-SSM机制独特地实现了Transformer级别的感受野,同时保持了类CNN的效率。这一突破解决了多模态系统中性能与计算成本之间长期存在的权衡问题。
MS2Fusion架构提供灵活的多模态集成,支持各种检测框架和骨干网络。它能无缝处理RGB、热成像和其他模态,无需更改架构即可在不同视觉任务中广泛应用。
MS2Fusion在基准数据集上实现了最先进的性能,包括RGB-T目标检测、语义分割和显著目标检测,验证了其在多光谱图像感知方面的有效性。
相关工作
目标检测
- 主流方法:主要分为两大类:
- 两阶段检测器 (如 Faster R-CNN):先生成候选区域,再进行分类和边界框回归,通常精度较高。
- 单阶段检测器 (如 YOLO、SSD):直接在图像上进行检测,速度更快。
- 边界框预测机制:
- **基于锚点(Anchor-based)**方法:利用预定义的锚点进行回归调整。
- **无锚点(Anchor-free)**方法(如 FCOS):直接预测边界或中心,简化流程,效率更高。
- 新兴的基于 Transformer 的方法:
- DETR:引入 Transformer 实现完全端到端检测,将检测视为集合预测问题,消除了锚点和 NMS 等人工设计组件。但存在计算成本高和收敛慢的问题。
- 本文方法的优势:为验证所提方法(MS2Fusion,结合上下文推测)的有效性,选择了 YOLOv5 和 CoDetr 进行对比实验,结果显示该方法具有线性时间复杂度 (高效率)和全局感受野 (捕获更丰富上下文信息)两大优势。
多光谱目标检测
- 早期方法:侧重于平衡特征集成,例如循环融合模块 (Cyclic Fusion Module) 显式建模模态间的互补性和一致性。
- 注意力机制的引入:通过 引导注意力特征融合 (GAFF) 等方法,利用自适应的模态内和跨模态注意力动态加权特征,提高了融合性能。
- 基于 Transformer 的架构:跨模态融合 Transformer (CFT) 和 CMX 等利用自注意力机制捕获跨模态的长距离依赖和全局上下文;后续的 ICAFusion 和 INSANet 等变体则通过参数共享或专用光谱注意力块优化了效率和灵活性。
- 解决特定挑战的创新方法:
- DAMSDet 使用可变形交叉注意力处理模态不对齐和动态互补特性。
- MS-DETR 引入参考约束融合改进 RGB-热成像对齐。
- 轻量级设计,如 CPCF 模块,结合通道和块级交叉注意力实现高效融合。
- TFDet 采用融合-精修范式以自适应感受野抑制假阳性。
- MMFN 提出了一个全面的分层融合框架,整合了局部、全局和通道级交互。
- 本文方法的区别:所提出的方法采用一种新颖的状态空间模型 (SSM) 进行特征融合,这与以往使用 CNN 或 Transformer 进行特征融合的方法不同。
Mamba
- Mamba 模型:
- Mamba 是一种选择性结构化状态空间模型,专为高效的长序列建模设计。
- 它通过结合全局感知场和动态加权,克服了 CNN 的局限性,实现了与 Transformer 相当的高级建模能力,但避免了 Transformer 典型的二次复杂度。
- Mamba 在视觉领域的应用:
- VMamba:一种视觉状态空间模型,引入了交叉扫描模块 (CSM) 来提高跨维度扫描效率,在计算机视觉任务中性能超越了 CNN 和 ViT。
- VM-UNet:将 Mamba 集成到 UNet 框架中用于医学分割,利用视觉状态空间块捕获广泛的上下文信息。
- Mamba 还被应用于多模态语义分割,通过暹罗编码器和创新融合机制,以线性复杂度增强了全局感受野覆盖。
- 本文提出的 MS2Fusion:
- 受上述进展启发,本文基于 Mamba 动态状态空间提出了 MS2Fusion。
- 该方法旨在有效利用模态间的共享特征和互补性,从而在降低模型复杂度的同时,提高目标检测的精度。
引言总结
研究问题
多光谱目标检测(RGB + 热红外)能在复杂场景下保持鲁棒性,但现有方法存在两大痛点:
- 偏重互补特征,忽略共享语义,导致泛化能力不足;
- 感受野与效率权衡难 —— CNN 看得近、Transformer 看得远但太慢。
论文核心思想
作者提出 MS2Fusion(Multispectral State-Space Feature Fusion) 框架,利用**状态空间模型(SSM)**实现高效的多模态特征融合。它通过双路径结构:
- 一条学习互补特征(不同模态的信息互补)
- 一条学习共享特征(模态间一致的语义)
最终,融合结果既具有跨模态互补性,也具有共享语义一致性。
主要贡献
- 提出 双路径状态空间特征融合框架 MS2Fusion;
- 将 Mamba 动态状态空间结构引入多模态特征建模;
- 同时实现 Transformer 级感受野 + CNN 级效率;
- 在多任务上取得 SOTA 性能(检测、分割、显著目标识别)。
整体组件概览
MS2Fusion 总体框架流程详解
整个网络包含三个阶段:
- 特征提取阶段:
- 两个独立主干网络分别提取 RGB 与红外特征;
- 跨模态融合阶段:
- 将三层特征(P3, P4, P5)分别送入 MS2Fusion 模块;
- 检测阶段:
- 使用 YOLOv5 或 CoDetr Head 生成检测结果。
融合公式如下:
其中 和 分别为两模态特征,输出 为融合结果。
关键创新点
MS2Fusion 流程的优势在于它通过双路径(CP-SSM+SP-SSM)机制实现了对多光谱特征的高效且全面的融合:
- 利用 SSM: SSM 模型能够有效地建模长程依赖关系 (大感受野),同时保持与 CNN 相当的计算效率,打破了传统架构的局限性。
- 双路径优势:
- CP-SSM: 捕捉互补特征。专注于互补性,确保两个模态的独特信息得到有效利用。
- SP-SSM: 学习共享语义。专注于共享语义,提高了模型的泛化能力和对齐度。
- 联合优化: 以上两路径使得MS2Fusion模型能够兼顾功能互补性和共享语义空间。
也就是说:MS2Fusion 同时让模型“看到不同”和“理解相同”。
方法
状态空间模型(SSM)
SSM(状态空间模型)本身并不是本文作者发明的模块,它起源于控制理论,并在 Mamba 模型中被引入深度学习。
它的最大优势是:能像 Transformer 一样捕捉全局关系(具有大感受野),但计算复杂度只有线性级别(也就是和 CNN 一样高效)。
本文所提出模型 MS2Fusion 的创新点是:把 SSM 结构应用到多模态特征融合中,并设计了三种变体(CP、SP、FF)来分别建模互补信息与共享语义。这使得模型在保持高效率的同时,具备了强大的跨模态理解能力。
SSM结合了循环神经网络(RNNs)和卷积神经网络(CNNs)的优势,能够高效处理长依赖关系。它通过状态方程将输入序列(x(t))转换为中间状态(h(t)),然后通过输出方程生成输出(y(t))。SSM通常表示为一个线性常微分方程:
为了使状态空间模型(SSM)适应深度学习,需将其离散化如下:
离散化后,SSM使用卷积操作进行并行计算。为了克服参数固定的问题,SSM引入了动态调整机制,使模型能够灵活处理复杂数据并改进长序列建模。
如图4所示,状态空间模型(SSM)通过由三项关键操作组成的结构化转换对输入序列进行转化处理。
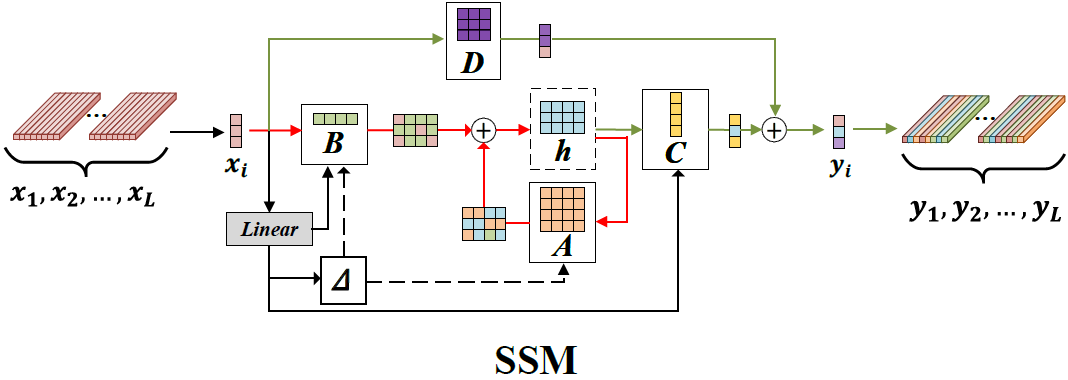
图4:SSM(状态空间模型),其中红色、绿色和黑色的线分别对应于公式 (2) 的方程。
SSM 是什么?
可以把 SSM 想成一个有记忆的滤波器:
- 每一时刻(或者每一个像素位置)都有一个「隐藏状态」
h,就像大脑里当前记着的东西 - 当前输入
x(图像的一小块特征)会和前面记住的h一起,算出新的h - 然后根据这个新的
h和当前x,算出输出y(更新后的特征)
论文里连续时间的 SSM 一般写成类似这样:
状态变化 = A × 状态 + B × 输入
输出 = C × 状态 + D × 输入
- A、B、C、D:可以理解成四张「参数表」,告诉模型:
- 以前的记忆(h)是如何影响现在
- 当前输入(x)是如何影响现在
- 输出 y 怎么从记忆和输入里“读”出来
因为我们在电脑里是一步一步处理序列(像一串像素),所以会把上面的「连续方程」离散化成:
> y_k = \overline{\mathbf{C}} \cdot h_k + \mathbf{D} \cdot x_k **SSM(State Space Model)** 是一种“记忆+预测”模型:
- 输入:序列特征(如图像 patch 序列)
- 输出:同维度特征
- 核心:四个矩阵 控制信息流动:
- A: 控制“记忆前面内容”;
- B: 决定“新信息如何进入”;
- C: 决定“输出什么特征”;
- D: 帮助防止梯度消失。
(1) 核心扫描算子:SelectiveScan
1 | import selective_scan_cuda_core as selective_scan_cuda // 公式二调用 |
此处代码对应公式(2)。
u对应论文里的输入序列 xₖdelta对应 Δ(时间步长)A, B, C, D就是 SSM 参数- 输出
out对应 y 序列
(2) 单模态 1D SSM:代码里的 SSM / SS2D
1 | def forward(self, x: torch.Tensor): |
对应关系(图4 & 式(2)):
- 论文中 Linear(·) 生出 Δ、B、C
对应代码中self.x_proj(...)+torch.split(... dt, B, C ...) - 论文中的 A、D
对应代码中self.A_log通过A = -exp(A_log)得到 A,self.D就是 D 参数 - 论文中的「沿序列扫描」
对应代码中selective_scan(x, dt, A, B, C, D, ...)
这个就是最基本的 单模态 Mamba/SSM 单元。
Mamba 的创新在于:这些矩阵是动态生成的,因此模型能根据输入自动调节“记忆与更新”的比例。
MS2Fusion 把这一机制应用到多模态特征上,实现了:
- 线性复杂度(高效率);
- 全局感受野(强语义建模能力)。
所提出的模型架构
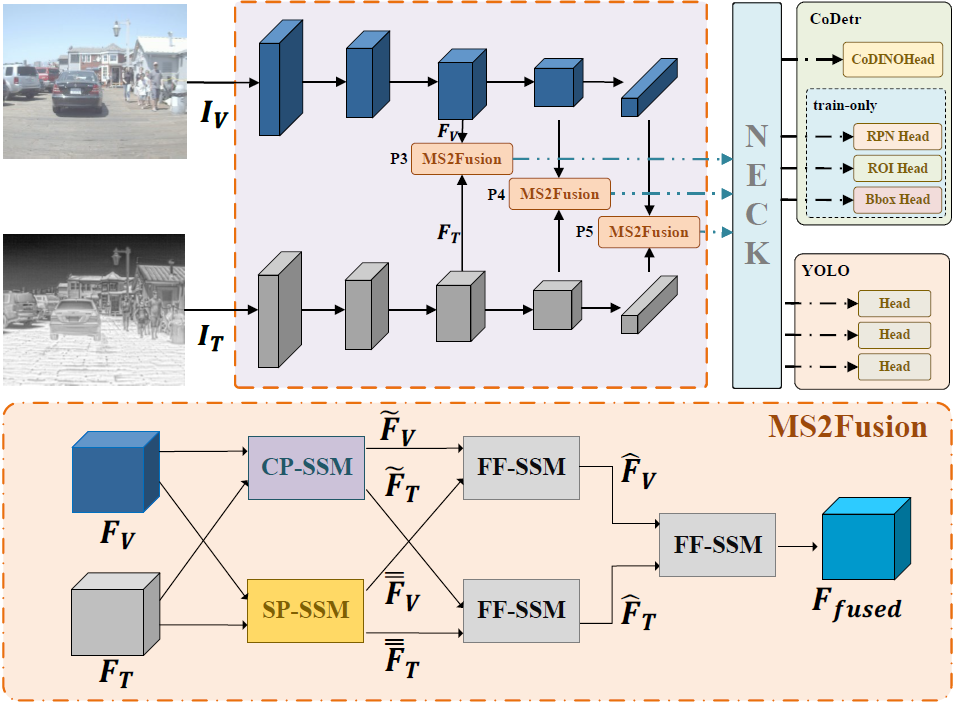
图5:模型架构概述。 该模型由三个主要阶段构成:(1) 使用两个主干网络进行特征提取;(2) 通过 MS2Fusion 模块对 、 和 层的特征进行跨模态特征融合;(3) 通过颈部(Neck)和头部(Head)层生成检测结果。
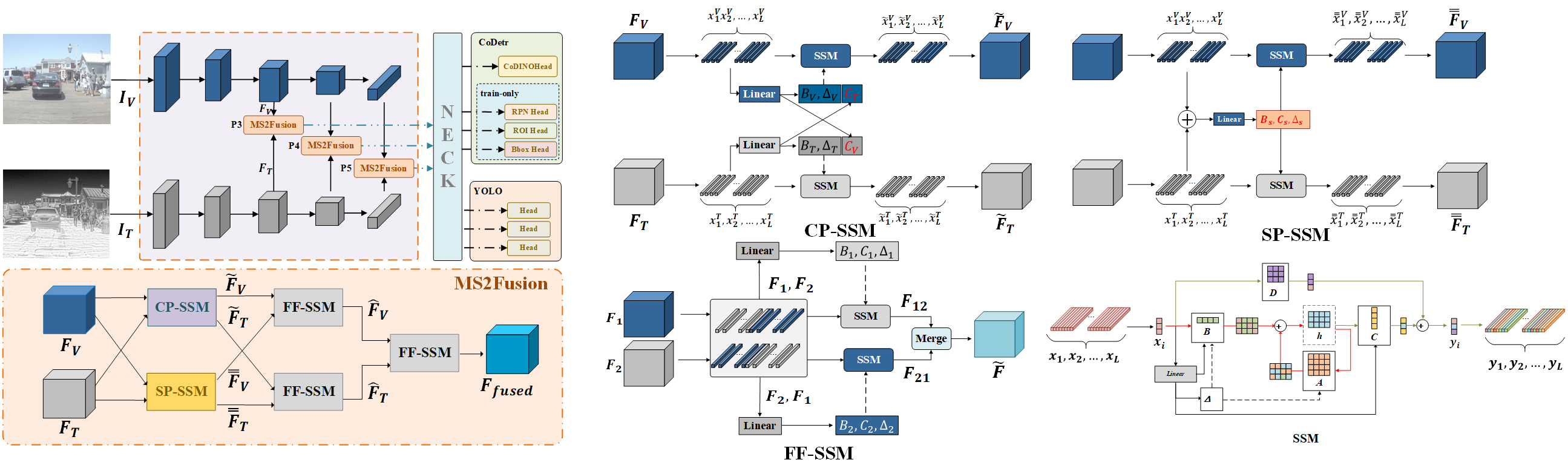
多光谱状态空间特征融合(MS2Fusion)
如图5的下半部分所示,MS2Fusion模块由三个核心组件构成:跨参数状态空间模型(CP-SSM)、共享参数状态空间模型(SP-SSM)和特征融合状态空间模型(FF-SSM)。
下面对这几个模块进行分析。
在 common.py 里,真正对应 MS2Fusion 的模块名叫 SSF(Shared & Cross SSM Fusion,可以理解成 S³Fusion)。
简化代码如下:
1 | class SSF(nn.Module): |
SSF.forward:
1 | def forward(self, x): |
对应论文式(3):
- =
- =
- = 模块里的 + 整套
- 输出 就是 ,接着会被送进 YOLOv5 的 neck/head 继续预测
CP-SSM 模块
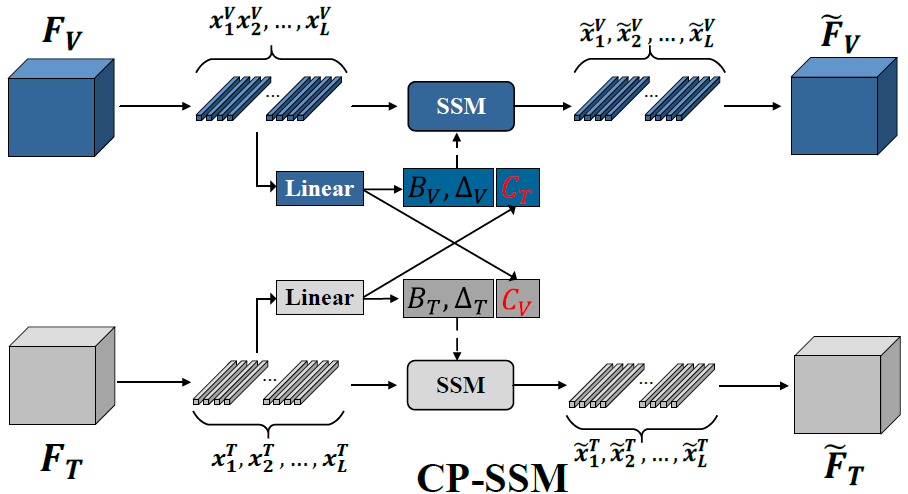
图 6 CP-SSM模块的细节 跨参数状态空间模型
图注: CP-SSM 模块的细节图。特征图 (, ) 首先通过行和列扫描被重塑为序列 (, ),并通过一个线性层(Linear layer)生成参数 、 和 。其次,作者通过交换两个分支的 矩阵来执行跨模态互补特征的交互。最后,通过SSM模块进行跨模态互补特征交互,以生成输出 (, )。
目标: 挖掘 RGB 与热成像间的互补特征。
思路:
- RGB 与热红外各自进入 SSM;
- 在计算时交换参数 C(相当于互换“视角”);
- 让 RGB 学到热红外的“温度信息”,热红外学到 RGB 的“纹理信息”。
在仓库中,此模块相关代码位于common.py
在类DBISSF_Attention.forward中
1 | def forward(self, x_rgb, x_share_rgb, x_e, x_share_e): |
CP-SSM 的关键是:
- RGB 分支用自己的一套 , , ,但输出 的时候用 红外那边的
- 红外分支用自己的 , , ,但输出 时用 RGB 的
公式(4) 就是在写这个「只交换 C」的过程。
对应关系:
- 图6里的两条分支(RGB 和 T 模态) 👉 ,
- 公式(4) 里各自的 Aᵢ, Bᵢ, Dᵢ 👉 , , 和 , ,
- 互换 C:
- RGB 分支用
- 红外分支用
这就是 CP-SSM 的“跨模态参数交互”。
注意:
- 上面这一段 的输出,就是论文中 CP-SSM 那条“互补特征路径”。
- 稍后 DBISSF_SS 会把这些结果 reshape 回 B×C×H×W 的二维特征。
SP-SSM 模块
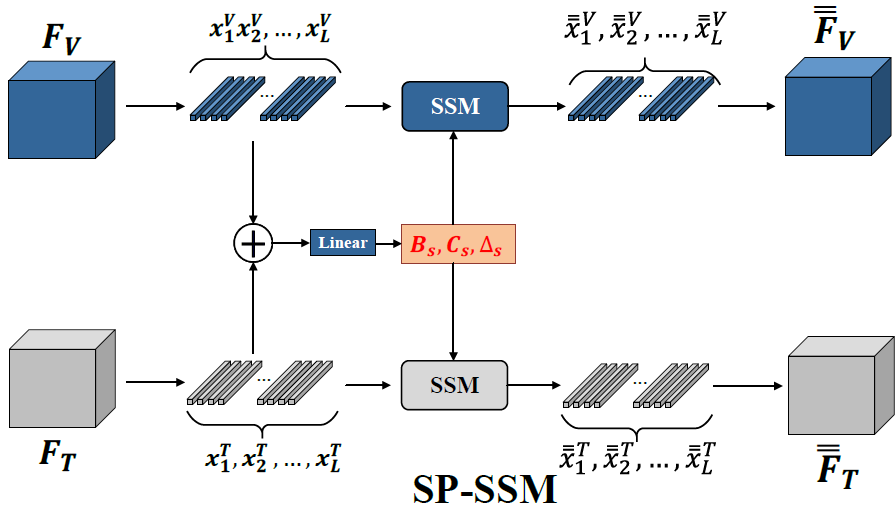
图 7 SP-SSM模块的细节及流程叙述
图注: SP-SSM模块的细节图。SP-SSM模块从具有共享参数的状态空间模型(SSM)中提取两种模态(RGB和热红外)的共享特征。输入特征 和 被组合以生成参数 、 和 ,同时输出特征 和 由这两个SSM进行重建。
具体过程由公式描述:
其中, 是共享特征, 是状态空间模型。 是从加权融合特征中获得的参数。
SP-SSM模块构建了一种层次化的特征共享架构,通过参数共享和特征重建实现跨模态表示对齐。如图7所示,该模块的流程由两个精心设计的阶段组成:
在参数共享阶段,模块采用粗粒度的加法特征融合方法对RGB和热红外特征进行初步整合。然后,通过一个线性网络动态生成三组关键的共享参数。这些参数不仅编码了双模态的共同特征模式,而且保留了模态特定的调整能力。
在特征重建阶段,这些共享参数被注入到两个模态的SSM中。这种设计创建了一个双流耦合架构:一方面,共享参数约束了两种模态在状态空间中的演化轨迹,驱动异构特征收敛到共享特征空间;另一方面,每个模态保留了独立的初始化状态,确保了模态特定信息的完整性。通过这种共享参数计算范式,模块能够提取出不受光照条件和环境干扰等因素影响的深度共享特征。
简而言之:
SP-SSM 的目的:抓住两个模态共同的语义。
方法是:
先把两路特征相加:
= +用这个 去生成一套共享参数 (, , )
然后把这套共享参数用在 、 两个分支上,跑同一套 SSM:
方法:
- 将 RGB 与热特征先相加(或拼接)成联合特征;
- 使用参数共享的 SSM 处理这两种输入;
- 因为参数相同,模型会倾向学习“共性信息”——比如物体轮廓、形状等。
还是在类DBISSF_Attention.forward中,刚才看到share分支
1 | # share 输入:x_share_rgb, x_share_e |
对应关系:
- 论文里 = + 对应
torch.add(x_share_rgb, x_share_e) - 论文里 生成 , , 对应
self.x_proj_share(...)+torch.split(... dt_share, B_share, C_share ...) - 论文里「同一套 SSM 同时作用在两路」 对应 两个
selective_scan调用:- 一个输入
x_share_rgb - 一个输入
x_share_e
使用的都是同一组(A_share, B_share, C_share, D_share, dt_share)
- 一个输入
DBISSF_SS
把 CP-SSM 和 SP-SSM 套在 2D 特征上(扫描方向)
刚才只是序列层面(L 维度)的 CP/SP,需要再放回到 2D 特征图上,这部分对应图6 底下那种「按 H×W 扫描」的结构。
在 DBISSF_SS.forward 里大致是这样:
输入是
x_rgb, x_e,形状 B×C×H×W用 1×1 卷积变换到适合 SSM 的通道数:
x_rgb_conv,x_e_conv再得到 share 分支
x_share_rgb_conv,x_share_e_conv把 H×W 摊平成一条长序列 L = H×W
可能还会做 CrossScan:既沿着行扫、又沿着列扫,再加正向+反向(对应图6 中多方向扫描)
喂给
CMA_ssm(也就是DBISSF_Attention)如果
scan=True,再用CMA_ssm2沿着另一个维度再扫一遍(更丰富的空间关系)最后把结果 reshape 回 B×C×H×W
1 | class DBISSF_SS(nn.Module): |
这一大块就是把式(4)(5) 落到实际的二维特征上。
FF-SSM 模块
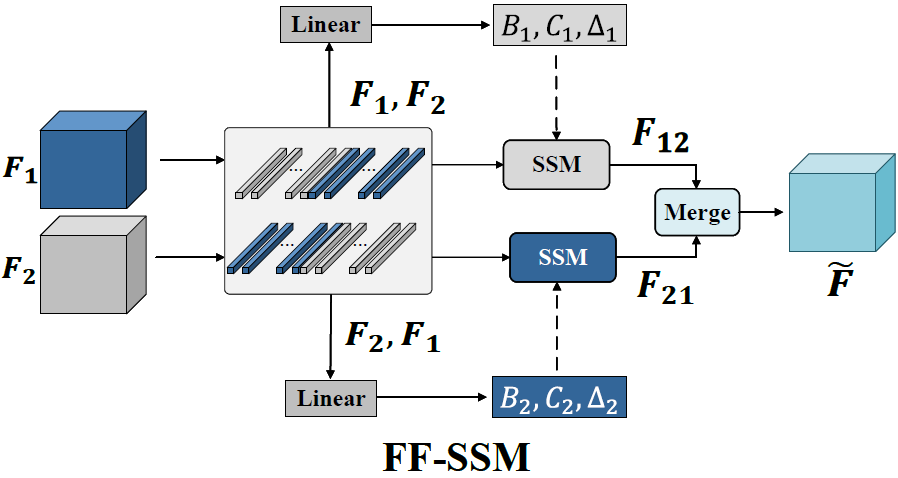
图注: FF-SSM 模块的细节图。该模块通过将 和 以两种不同顺序组合来实现特征融合。在顶部分支中,输入特征以 1-2 的顺序(例如 )组合形成拼接特征,然后通过一个线性层(Linear layer)生成 、 和 参数,随后通过 SSM 执行跨特征交互。最终,将 和 合并(merge)生成融合特征图 。
模块流程叙述:
FF-SSM 模块旨在解决 Mamba 固有的特征遗忘问题,同时实现彻底且自适应的跨模态特征融合。它通过引入双向架构,结合互补的前向和反向处理路径来系统性地弥补单向建模的局限性。
输入特征: 模块接收来自 CP-SSM 输出的特征图 和 (例如,RGB 和热红外互补特征)。
双向异构序列构建(Bidirectional Sequence Construction): 模块采用双向异构序列构建策略,将 和 以两种不同顺序进行拼接:
- 前向路径 (Top Path): 序列为 。
- 反向路径 (Bottom Path): 序列为 。
参数生成:
- 前向路径: 拼接序列 通过线性变换层 生成状态空间模型参数 。
- 反向路径: 拼接序列 通过另一个线性变换层 生成状态空间模型参数 。
状态空间处理与特征交互:
- 前向 SSM: 参数 和序列 输入 SSM () 得到输出特征 。
- 反向 SSM: 参数 和序列 输入 SSM () 得到输出特征 。
- 作用: 反向路径 专门用于捕获在前向传播中可能发生的特征损失,通过方向自适应参数生成来补偿单向建模的局限性。
最终融合(Adaptive Fusion): 模块通过一个合并函数 () 将来自双向 SSM 路径的输出特征 和 进行融合,生成最终的融合特征图 。
目标: 这种双路径机制能够更全面地捕获长距离跨模态依赖关系,动态地缓解特征遗忘,同时在不牺牲 Mamba 线性复杂度的前提下,确保更丰富、更精确的特征表示,显著提高检测精度。
数学表达:
尽管CP-SSM模块能够捕获模态间隐式的互补关系,但它在特征融合层面上仍存在局限性。为了解决Mamba固有的特征遗忘问题,同时保持其计算效率,作者提出了一个结合互补前向 () 和反向 () 处理路径的双向架构。
这种创新设计通过方向自适应参数生成系统地弥补了单向建模的局限性,其中反向路径专门用于捕获前向传播中可能发生的特征损失。与传统Transformer因分块操作导致信息丢失不同,作者的方法不仅保持了Mamba原有的序列依赖和线性复杂度的优势,而且通过反向序列补偿显著增强了特征保留。双路径机制能够更全面地捕获长距离跨模态依赖关系,同时动态地缓解特征遗忘,在不牺牲效率的情况下实现了鲁棒的序列建模。
具体来说,给定CP-SSM输出的特征图 和 ,该模块采用双向异构序列构建策略:以不同顺序 ( 和 ) 对特征进行拼接。这种设计不仅扩展了模型的感受野,还增强了特征表示的多样性。
在实现中,特征首先被展开并拼接成两个方向序列,然后通过线性变换层生成相应的状态空间模型参数 ( 和 )。最后,通过融合来自双向SSM路径的输出特征 ( 和 ),模块实现了彻底的跨模态特征交互和自适应融合,显著提高了检测精度。FF-SSM模块有效地保留了两种模态内的细节信息,确保了更丰富、更精确的特征表示,这在公式 (6) 中被描述:
其中 表示图4中的SSM, 是特征图。
简而言之:
有了 CP-SSM 和 SP-SSM,我们得到两种特征:
- F₁:互补信息(差异)
- F₂:共享信息(共性)
FF-SSM 想干的是:
把 F₁、F₂ 再“来回搅拌”,既考虑「先看 F₁ 再看 F₂」,也考虑「先看 F₂ 再看 F₁」,最后得到一个融合特征 F_fused。
式(6) 的大致意思是:
- 把 (F₁, F₂) 作为一对输入,喂进一个线性层,得到一组 (Δ₁, B₁, C₁)
- 把 (F₂, F₁) 再喂一次,得到 (Δ₂, B₂, C₂)
- 用这两组参数跑两次 SSM,得到两个方向的输出 F₁₂ 和 F₂₁
- 再把 F₁₂ 和 F₂₁ 结合起来就是 F_fused
图8 就是把这些步骤画成了一个带两路输入、两路输出再融合的结构。
CMSSF + CM_Attention
CMSSF 是一个「Concat Mamba 2D 融合模块」:
1 | class CMSSF(nn.Module): |
CM_Attention 的核心是 forward_corev2_multimodal:
1 | class CM_Attention(nn.Module): |
真正实现“式(6)”的是 cross_selective_scan_multimodal_k2:
1 | def cross_selective_scan_multimodal_k2(x_rgb, x_e, x_proj_weight, x_proj_bias, |
对应关系(图8 & 式(6)):
- 图8 里「两路输入 F₁/F₂、正向/反向」 👉 这里的
CrossScan_multimodal生成两条序列(正向与反向)。 - 图8 里「两次 Linear 生成不同参数」 👉 这里一次
x_fuse里已经含有两路信息([RGB, E] 的拼接),通过x_proj_weight+dt_projs_weight把它们变成多组 (Δ,B,C);不同的 k 维度相当于式(6) 中“不同组合(F₁F₂ / F₂F₁)”的效果。 - 图8 里「两次 SSM 再融合」 👉 这里的
SelectiveScan.apply(...)输出ys,然后CrossMerge_multimodal.apply(ys)把它们合成y_rgb, y_e两个结果(相当于 F₁₂ 与 F₂₁ 的融合)。
在 SSF.forward 里,FF-SSM 被用了 三次:
x_fuse_rgb -> self.cm_fusion_rgb(...):融合「RGB 互补特征 + RGB 共享特征」x_fuse_e -> self.cm_fusion_e(...):融合「E 互补特征 + E 共享特征」[x_rgb, x_e] -> self.cm_fusion(...):最后再融合「融合后的 RGB 与 融合后的 E」
这整体就是论文里 FF-SSM 的那一整套“前后双向、模态间来回流动”的过程。
损失函数
由MS2Fusion模块生成的融合特征被送入颈部网络(Neck)和检测头(Detection Head),整个流程以端到端的方式进行优化。在本文中,作者分别在基于YOLOv5和Co-Detr的两种检测框架中对MS2Fusion进行了评估。
YOLO 框架下的总损失函数
在YOLO框架中,总损失函数可以表示为:
其中:
- 是**定位损失** (Localization Loss)。
- 是**置信度损失** (Confidence Loss)。
- 是**分类损失** (Classification Loss)。
- 超参数 、 和 用于调整各项损失的权重,这些权重保持了基线模型的默认设置。
CoDetr 框架下的总损失函数
CoDetr框架采用了一个多任务损失函数,该函数由四个组成部分构成:一个主要的CoDINOHead 和三个辅助检测头(包括RPN头、ROI头和Bbox头)。
总损失函数可以表示为:
其中:
- 是**质量焦点损失** (Quality Focal Loss)。
- 是 **损失**。
- 是 **GIoU损失**。
- 是**交叉熵损失** (Cross-Entropy Loss)。
- 是**焦点损失** (Focal Loss)。
- 超参数 为各项损失项的加权因子。
实验
本章节详细介绍了MS2Fusion模型所进行的系列实验,包括实验设置、SOTA(State-of-the-art)比较、泛化能力测试、消融研究和定性分析。
数据集和评估指标
数据集:
本文在四个多光谱目标检测数据集上进行了评估:
- FLIR (aligned): 包含5,142对RGB-T图像,分为4,129对训练集和1,013对测试集
- LLVIP: 包含15,488对RGB-T图像,12,025对用于训练,3,463对用于测试,主要标注热成像图像
- M3FD: 包含4,200对RGB-T对齐图像,涵盖多种条件和六个类别,按8:2划分训练/测试集
- VEDAI: 包含3,640个目标实例(9个类别)的航拍图像,共1,210张1024x1024图像,包含RGB和NIR(近红外)通道,按9:1划分训练/测试集
评估指标:
- AP (Average Precision): 标源于精确率-召回率(PR)曲线下的面积,该曲线以召回率为横轴、精确率为纵轴
- mAP (mean Average Precision): 所有类别的AP加权平均值。实验中,mAP@0.5(IoU阈值为0.5)是主要指标。该指标的值越高,表明性能越好
实验设置
- 硬件: Intel i7-9700 CPU, 64GB RAM, Nvidia RTX 3090 GPU (24GB)
- 软件: PyTorch
- 超参数: 消融研究使用60个epoch,批量大小(batch size)为4,使用SGD优化器,初始学习率为0.01,动量0.937,权重衰减0.0005,余弦学习率衰减
- 输入尺寸: 训练时为640x640,测试时为640x512
- 数据增强: 使用Mosaic(马赛克)增强
SOTA比较
实验在YOLOv5(速度快、精度稍低)和CoDetr(速度慢、精度高)两个框架上进行。YOLOv5检测器的推理速度更快,但精度较低;而CoDetr的检测精度更高,但推理速度较慢。
FLIR 数据集比较
表2: FLIR-align 数据集比较
(‘-’ 表示缺失值. ‘‡’ 符号表示使用CoDetr框架的实验结果,输入图像被调整为640×640像素的固定分辨率)
| 方法 | mAP@0.5 | mAP | 自行车 | 汽车 | 人 |
|---|---|---|---|---|---|
| MMTOD-CG | 61.4 | - | 50.3 | 70.6 | 63.3 |
| MMTOD-UNIT | 61.5 | - | 49.4 | 70.7 | 64.5 |
| CMPD | 69.4 | - | 59.9 | 78.1 | 69.6 |
| CFR | 72.4 | - | 57.8 | 84.9 | 74.5 |
| GAFF | 72.9 | 37.5 | - | - | - |
| BU-ATT | 73.1 | - | 56.1 | 87.0 | 76.1 |
| BU-LTT | 73.2 | - | 57.4 | 86.5 | 75.6 |
| UA_CMDet | 78.6 | - | 64.3 | 88.4 | 83.2 |
| CFT | 78.7 | 40.2 | - | - | - |
| CSAA | 79.2 | 41.3 | - | - | - |
| ICAFusion | 79.2 | 41.4 | 66.9 | 89.0 | 81.6 |
| CrossFormer | 79.3 | 42.1 | - | - | - |
| MFPT | 80.0 | - | 67.7 | 89.0 | 83.2 |
| MMFN | 80.8 | 41.7 | 65.5 | 91.2 | 85.7 |
| RSDet | 81.1 | 41.4 | - | - | - |
| MiPa | 81.3 | 44.8 | - | - | - |
| UniRGB-IR | 81.4 | 44.1 | - | - | - |
| CPCF | 82.1 | 44.6 | - | - | - |
| GM-DETR | 83.9 | 45.8 | - | - | - |
| Fusion-Mamba(yolov5) | 84.3 | 44.4 | - | - | - |
| Fusion-Mamba(yolov8) | 84.9 | 47.0 | - | - | - |
| TFDet | 86.6 | 46.6 | - | - | - |
| DAMSDet | 86.6 | 49.3 | - | - | - |
| Ours | 83.3 | 40.3 | 74.9 | 89.8 | 85.1 |
| Ours‡ | 87.8 | 49.7 | 79.6 | 93.4 | 90.2 |
分析: 如表2所示,MS2Fusion在YOLOv5框架下达到83.3%的mAP@0.5,在CoDetr框架下达到87.8%的mAP@0.5,均取得了SOTA性能,分别比当前最优方法提升了2.2%和6.7%。尤其在“人”和“自行车”这两个非热源和小目标类别上增益明显。
LLVIP 数据集比较
表3: LLVIP 数据集比较
| 方法 | mAP@0.5 | mAP |
|---|---|---|
| DIVFusion | 89.8 | 52.0 |
| GAFF | 94.0 | 55.8 |
| CSAA | 94.3 | 41.3 |
| ECISNet | 95.7 | - |
| RSDet | 95.8 | 61.3 |
| UniRGB-IR | 96.1 | 63.2 |
| UA_CMDet | 96.3 | - |
| CPCF | 96.4 | 65.0 |
| Fusion-Mamba(yolov5) | 96.8 | 62.8 |
| Fusion-Mamba(yolov8) | 97.0 | 64.3 |
| MMFN | 97.2 | - |
| GM-DETR | 97.4 | 70.2 |
| TFDet | 97.9 | 71.1 |
| DAMSDet | 97.9 | 69.6 |
| MiPa | 98.2 | 66.5 |
| Ours | 97.5 | 65.5 |
| Ours‡ | 98.4 | 70.6 |
分析: 如表3所示,MS2Fusion在LLVIP数据集上同样表现出色,YOLOv5框架下mAP@0.5达到97.5%,CoDetr框架下达到98.4%,优于传统的CNN和Transformer方法。
M3FD 数据集比较
表4: M3FD 数据集比较
| 方法 | mAP@0.5 | mAP | People | Bus | Car | Motorcycle | Lamp | Truck |
|---|---|---|---|---|---|---|---|---|
| DIDFuse | 79.0 | 52.6 | 79.6 | 79.7 | 92.5 | 68.7 | 84.7 | 68.8 |
| SDNet | 79.0 | 52.9 | 79.4 | 81.4 | 92.3 | 67.4 | 84.1 | 69.3 |
| RFNet | 79.4 | 53.2 | 79.4 | 78.2 | 91.1 | 72.8 | 85.0 | 69.0 |
| ReC | 79.5 | - | 79.4 | 78.9 | 91.8 | 69.3 | 87.4 | 70.0 |
| U2F | 79.6 | - | 80.7 | 79.2 | 92.3 | 66.8 | 87.6 | 71.4 |
| DAMSDet | 80.2 | 52.9 | - | - | - | - | - | - |
| TarDAL | 80.5 | 54.1 | 81.5 | 81.3 | 94.8 | 69.3 | 87.1 | 68.7 |
| DeFusion | 80.8 | 53.8 | 80.8 | 83.0 | 92.5 | 69.4 | 87.8 | 71.4 |
| CDDFusion | 81.1 | 54.3 | 81.6 | 82.6 | 92.5 | 71.6 | 86.9 | 71.5 |
| IGNet | 81.5 | 54.5 | 81.6 | 82.4 | 92.8 | 73.0 | 86.9 | 72.1 |
| SuperFusion | 83.5 | 56.0 | 83.7 | 93.2 | 91.0 | 77.4 | 70.0 | 85.8 |
| Fusion-Mamba(yolov5) | 85.0 | 57.5 | 80.3 | 92.8 | 91.9 | 73.0 | 84.8 | 87.1 |
| MMFN | 86.2 | - | 83.0 | 92.1 | 93.2 | 73.7 | 87.6 | 87.4 |
| Fusion-Mamba(yolov8) | 88.0 | 61.9 | 84.3 | 94.2 | 92.9 | 80.5 | 87.5 | 88.8 |
| Ours | 89.4 | 59.7 | 85.6 | 93.7 | 93.9 | 82.4 | 90.8 | 89.9 |
| Ours‡ | 91.4 | 65.6 | 89.8 | 95.0 | 94.7 | 88.2 | 88.3 | 92.4 |
分析: 如表4所示,MS2Fusion在M3FD数据集上表现出显著优势,YOLOv5框架提升3.2% (mAP@0.5),CoDetr框架提升5.2% (mAP@0.5)。特别是在摩托车等高热源物体上提升明显,显示了其有效融合热成像特征的能力。
VEDAI 数据集比较
表5: VEDAI 数据集比较
| 方法 | mAP@0.5 | Car | Truck | Pickup | Tractor | Camper | Ship | Van | Plane |
|---|---|---|---|---|---|---|---|---|---|
| ICAFusion | 76.6 | 88.0 | 67.5 | 80.9 | 74.9 | 78.3 | 56.9 | 69.8 | 96.7 |
| MidFusion1 | 77.4 | 88.2 | 84.9 | 81.7 | 68.4 | 72.2 | 71.0 | 53.6 | 99.5 |
| MidFusion2 | 78.9 | 89.2 | 78.8 | 87.6 | 66.2 | 73.2 | 62.5 | 73.9 | 99.5 |
| Input Fusion1 | 80.0 | 88.7 | 77.7 | 79.5 | 72.3 | 75.7 | 78.6 | 72.1 | 95.7 |
| Input Fusion2 | 80.5 | 89.1 | 84.9 | 78.7 | 84.2 | 70.1 | 69.9 | 68.8 | 98.4 |
| YOLOFusion | 81.6 | 91.7 | 78.1 | 85.9 | 71.9 | 78.9 | 71.7 | 75.2 | 99.5 |
| Ours | 80.2 | 89.5 | 75.6 | 84.2 | 81.6 | 75.9 | 61.8 | 76.4 | 97.0 |
| Ours‡ | 84.2 | 93.3 | 78.9 | 88.5 | 85.8 | 80.6 | 65.5 | 83.6 | 97.1 |
分析: 如表5所示,在VEDAI(航拍)数据集上,MS2Fusion (CoDetr) 达到了84.2%的mAP@0.5,取得了SOTA性能。这表明模型即使没有针对小目标检测进行专门优化,该模型依然能有效关注小目标的多模态特征,在无人机图像应用中表现出鲁棒性。
泛化到其他多模态任务
RGB-T 语义分割
- 评估指标: 平均交并比 mIoU (Mean Intersection over Union),是语义分割模型常用的评估指标,它通过计算预测分割与真实分割的交并比来衡量模型性能
- 数据集: MFNet (1,569对图像, 8类) 和 SemanticRT (11,371对图像, 13类)
表6: MFNet 数据集比较
| 方法 | mIoU | Car | Person | Bike | Curve | Car Stop | Guardrail | Color Cone | Bump |
|---|---|---|---|---|---|---|---|---|---|
| PSTNet | 48.4 | 76.8 | 52.6 | 55.3 | 29.6 | 25.1 | 15.1 | 39.4 | 45.0 |
| RTFNet | 53.2 | 87.4 | 70.3 | 62.7 | 45.3 | 29.8 | 0.0 | 29.1 | 55.7 |
| FuseSeg | 54.5 | 87.9 | 71.7 | 64.6 | 44.8 | 22.7 | 6.4 | 46.9 | 47.9 |
| AFNet | 54.6 | 86.0 | 67.4 | 62.0 | 43.0 | 28.9 | 4.6 | 44.9 | 56.6 |
| ABMDRNet | 54.8 | 84.8 | 69.6 | 60.3 | 45.1 | 33.1 | 5.1 | 47.4 | 50.0 |
| FEANet | 55.3 | 87.8 | 71.1 | 61.1 | 46.5 | 22.1 | 6.6 | 55.3 | 48.9 |
| GMNet | 57.3 | 86.5 | 73.1 | 61.7 | 44.0 | 42.3 | 14.5 | 48.7 | 47.4 |
| EGFNet | 57.5 | 89.8 | 71.6 | 63.9 | 46.7 | 31.3 | 6.7 | 52.0 | 57.4 |
| DPLNet | 59.3 | - | - | - | - | - | - | - | - |
| CMX | 59.7 | 90.1 | 75.2 | 64.5 | 50.2 | 35.3 | 8.5 | 54.2 | 60.6 |
| CRM-RGBT-Seg | 61.4 | 90.0 | 75.1 | 67.0 | 45.2 | 49.7 | 18.4 | 54.2 | 54.4 |
| MFNet(baseline) | 63.5 | 92.6 | 82.1 | 78.2 | 89.6 | 24.1 | 1.2 | 46.2 | 94.2 |
| MS2Fusion-MFNet | 66.3 | 94.4 | 82.5 | 81.0 | 89.9 | 34.7 | 0.0 | 49.7 | 98.3 |
分析: 如表6所示,在MFNet数据集上,MS2Fusion (MS2Fusion-MFNet) 取得了66.3%的最佳mIoU,相比基线提升了2.8%。在凸起和曲线类别上提升尤为明显,这表明MS2Fusion能有效利用跨模态的共享特征(如局部几何特征),显著提升这两个类别的分割性能。
表7: SemanticRT 数据集比较
| 方法 | mIoU | CarStop | Bike | Bicyclist | Mtcycle | Mtcyclist | Car | Tricycle | TrafLight | Box | Pole | Curve | Person |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSTNet | 68.0 | 71.1 | 62.3 | 58.5 | 47.3 | 55.2 | 85.4 | 44.2 | 75.7 | 83.0 | 71.7 | 62.2 | 72.2 |
| RTFNet | 75.5 | 79.6 | 68.0 | 67.4 | 63.7 | 61.6 | 90.4 | 66.0 | 78.3 | 85.9 | 78.0 | 67.2 | 78.9 |
| EGFNet | 77.4 | 78.6 | 71.3 | 70.9 | 68.4 | 66.1 | 90.5 | 71.5 | 80.4 | 85.4 | 76.5 | 66.9 | 83.7 |
| ECM | 79.3 | 80.2 | 75.0 | 75.5 | 71.4 | 70.4 | 90.3 | 74.0 | 85.9 | 85.6 | 77.2 | 68.3 | 85.0 |
| MFNet(baseline) | 77.8 | 75.3 | 77.1 | 63.2 | 71.1 | 57.3 | 97.9 | 66 | 85.9 | 89.5 | 82.4 | 85.0 | 83.2 |
| MS2Fusion-MFNet | 78.8 | 75.3 | 77.7 | 66.3 | 72.3 | 59.4 | 97.9 | 68.2 | 86.0 | 89.6 | 81.8 | 84.6 | 86.7 |
分析: 如表7所示,在SemanticRT数据集上,MS2Fusion (MS2Fusion-MFNet) 同样表现优异,mIoU达到78.8%,相比基线提升1.0%,且与SOTA方法 (ECM) 仅相差0.5%,证明了其在多光谱特征融合上的鲁棒性和多功能性。
RGB-T 显著性目标检测 (RGB-T SOD)
- 评估指标: 平均绝对误差 MAE (↓越低越好), F度量 adpF (↑越高越好), S度量 S-Measure (S↑), E度量 E-Measure (adpE↑)
- 数据集: VT821, VT1000, VT5000
- 基线模型: MSEDNET
表8: VT821, VT1000 和 VT5000 数据集比较
(↓ 表示值越小越好, ↑ 表示值越大越好)
| 方法 | VT821 | VT1000 | VT5000 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S↑ | adpE↑ | adpF↑ | MAE↓ | S↑ | adpE↑ | adpF↑ | MAE↓ | S↑ | adpE↑ | adpF↑ | MAE↓ | |
| MTMR | 72.5 | 81.5 | 66.2 | 10.9 | 70.6 | 83.6 | 71.5 | 11.9 | 68.0 | 79.5 | 59.5 | 11.4 |
| M3S-NIR | 72.3 | 85.9 | 76.4 | 14.0 | 72.6 | 82.7 | 71.7 | 14.5 | 65.2 | 78.0 | 57.5 | 16.8 |
| SGDL | 76.5 | 84.7 | 76.1 | 8.5 | 78.7 | 85.6 | 76.4 | 9.0 | 75.0 | 82.4 | 67.2 | 8.9 |
| PoolNet | 75.1 | 73.9 | 57.8 | 10.9 | 83.4 | 81.3 | 71.4 | 6.7 | 76.9 | 75.5 | 58.8 | 8.9 |
| R3Net | 78.6 | 80.9 | 66.0 | 7.3 | 84.2 | 85.9 | 76.1 | 5.5 | 75.7 | 79.0 | 61.5 | 8.3 |
| CPD | 82.7 | 83.7 | 71.0 | 5.7 | 90.6 | 90.2 | 83.4 | 3.2 | 84.8 | 86.7 | 74.1 | 5.0 |
| MMCI | 76.3 | 78.4 | 61.8 | 8.7 | 88.6 | 89.2 | 80.3 | 3.9 | 82.7 | 85.9 | 71.4 | 5.5 |
| AFNet | 77.8 | 81.6 | 66.1 | 6.9 | 88.8 | 91.2 | 83.8 | 3.3 | 83.4 | 87.7 | 75.0 | 5.0 |
| TANet | 81.8 | 85.2 | 71.7 | 5.2 | 90.2 | 91.2 | 83.8 | 3.0 | 84.7 | 88.3 | 75.4 | 4.7 |
| S2MA | 81.1 | 81.3 | 70.9 | 9.8 | 91.8 | 91.2 | 84.8 | 2.9 | 85.3 | 86.4 | 74.3 | 5.3 |
| JLDCF | 83.9 | 83.0 | 72.6 | 7.6 | 91.2 | 89.9 | 82.9 | 3.0 | 86.1 | 86.0 | 73.9 | 5.0 |
| FMCF | 76.0 | 79.6 | 64.0 | 8.0 | 87.3 | 89.9 | 82.3 | 3.7 | 81.4 | 86.4 | 73.4 | 5.5 |
| ADF | 81.0 | 84.2 | 71.7 | 7.7 | 91.0 | 92.1 | 84.7 | 3.4 | 86.4 | 89.1 | 77.8 | 4.8 |
| MIDD | 87.1 | 89.5 | 80.3 | 4.5 | 91.5 | 93.3 | 88.0 | 2.7 | 86.8 | 89.6 | 79.9 | 4.3 |
| LSNet | 87.2 | 91.0 | 81.4 | 3.6 | 92.1 | 94.9 | 88.1 | 2.3 | 87.5 | 92.0 | 81.7 | 3.7 |
| CAVER | 89.8 | 92.8 | 87.7 | 2.7 | 93.6 | 94.9 | 91.1 | 1.7 | 89.9 | 94.1 | 84.9 | 2.8 |
| DPLNet | 87.8 | 90.8 | 81.0 | 4.3 | 92.8 | 95.1 | 88.1 | 2.2 | 87.9 | 91.6 | 82.8 | 3.8 |
| MSEDNET(baseline) | 87.6 | 89.7 | 80.3 | 3.9 | 92.8 | 93.9 | 86.8 | 2.2 | 88.1 | 91.6 | 82.1 | 3.7 |
| MS2Fusion-MSEDNET | 90.4 | 93.5 | 86.3 | 3.2 | 94.4 | 97.2 | 91.8 | 1.6 | 90.2 | 94.2 | 86.4 | 3.0 |
分析: 如表8所示,MS2Fusion (MS2Fusion-MSEDNET) 在三个RGB-T SOD数据集上均达到了SOTA性能。例如,在VT5000上,MAE指标从基线的3.7降低到3.0;在VT1000上,adpF指标从86.8提升到91.8。MS2Fusion在所有评估指标上均排名第一或第二,展示了其在RGB-T SOD任务中的卓越特征融合能力。
消融研究
所有消融研究均在FLIR数据集和YOLOv5框架上进行。
不同检测框架的影响
表9: 不同骨干网络和检测框架的影响
| 编号 | 框架 | 融合模型 | 人 | 汽车 | 自行车 | mAP@0.5 | FPS |
|---|---|---|---|---|---|---|---|
| 1 | YOLOv5 | Baseline | 83.8 | 88.9 | 67.3 | 80.0 | 43.2 |
| 2 | MS2Fusion | 85.1 | 89.8 | 74.9 | 83.3 (+3.3) | 24.4 | |
| 3 | CoDetr | Baseline | 88.0 | 91.7 | 73.8 | 84.5 | 5.9 |
| 4 | MS2Fusion | 90.2 | 93.4 | 79.6 | 87.8 (+3.3) | 4.8 |
分析: 如表9所示,MS2Fusion模块在YOLOv5和CoDetr两个主流检测框架上,均比基线(add fusion)带来了**3.3%**的mAP@0.5提升。这证明了MS2Fusion具有出色的“即插即用”特性和强大的泛化能力。
不同骨干网络的影响
表10: 不同骨干网络的影响
| 编号 | 骨干网络 | 融合模型 | 人 | 汽车 | 自行车 | mAP@0.5 |
|---|---|---|---|---|---|---|
| 1 | VGG16 | Baseline | 78.9 | 87.7 | 51.2 | 72.6 |
| 2 | MS2Fusion | 79.0 | 87.8 | 53.8 | 73.6 (+1.0) | |
| 3 | ResNet50 | Baseline | 76.8 | 85.7 | 44.6 | 69.0 |
| 4 | MS2Fusion | 80.2 | 88.4 | 52.8 | 73.8 (+4.8) | |
| 5 | CSPDarkNet53 | Baseline | 83.8 | 88.9 | 67.3 | 80.0 |
| 6 | MS2Fusion | 85.1 | 89.8 | 74.9 | 83.3 (+3.3) |
分析: 如表10所示,MS2Fusion在VGG16、ResNet50和CSPDarkNet53三种不同骨干网络上均实现了一致的性能增益,分别提升了1.0%、4.8%和3.3% (mAP@0.5)。这进一步证实了MS2Fusion模块对不同骨干架构的强大泛化能力和兼容性。
不同模块的影响
表11: 不同融合模块的影响
| 编号 | CP-SSM | SP-SSM | FF-SSM | 人 | 汽车 | 自行车 | mAP@0.5 | Params(M) |
|---|---|---|---|---|---|---|---|---|
| 1 | 83.8 | 88.9 | 67.3 | 80.0 | 72.7 | |||
| 2 | ✓ | 83.8 | 89.8 | 72.7 | 82.1 (+2.1) | 84.5 | ||
| 3 | ✓ | 85.6 | 90.4 | 70.6 | 82.2 (+2.2) | 90.4 | ||
| 4 | ✓ | 84.9 | 90.1 | 72.4 | 82.5 (+2.5) | 86.0 | ||
| 5 | ✓ | ✓ | 84.9 | 90.3 | 72.9 | 82.7 (+2.7) | 117.0 | |
| 6 | ✓ | ✓ | 85.5 | 90.0 | 72.5 | 82.7 (+2.7) | 97.8 | |
| 7 | ✓ | ✓ | 85.5 | 90.3 | 72.9 | 82.9 (+2.9) | 103.7 | |
| 8 | ✓ | ✓ | ✓ | 85.1 | 89.8 | 74.9 | 83.3 (+3.3) | 130.2 |
分析: 如表11所示,基线(第1行)mAP为80.0%。
- 单独使用CP-SSM (第2行)提升2.1% mAP,显著提升了“自行车”类别(+5.4%),表明它善于增强模态特定特征
- 单独使用SP-SSM (第3行)提升2.2% mAP,表明提取跨模态共享特征的有效性
- 单独使用FF-SSM (第4行)提升2.5% mAP,表明其异构特征融合的高效性
- 组合使用(第5-7行)均有提升,而集成所有三个模块 (第8行)达到了83.3% mAP的最佳性能(+3.3%),尤其在“自行车”类别上提升了7.6%
- 这证明了CP-SSM(互补)、SP-SSM(共享)和FF-SSM(融合)三者协同作用,实现了模态特异性增强、跨模态泛化和自适应融合的平衡
不同融合层的影响
表12: 在不同层进行融合的影响
| 编号 | P3 | P4 | P5 | 人 | 汽车 | 自行车 | mAP@0.5 |
|---|---|---|---|---|---|---|---|
| 1 | 83.8 | 88.9 | 67.3 | 80.0 | |||
| 2 | ✓ | 83.4 | 88.5 | 71.4 | 81.1 (+1.1) | ||
| 3 | ✓ | ✓ | 85.8 | 90.1 | 70.0 | 82.0 (+2.0) | |
| 4 | ✓ | ✓ | ✓ | 85.1 | 89.8 | 74.9 | 83.3 (+3.3) |
分析: 如表12所示,对比了在不同特征层(P3, P4, P5)应用MS2Fusion模块的效果。
- 仅在P3(浅层)融合(第2行),“自行车”AP大幅提升5.7%,但“人”和“车”略降,总mAP升至81.1%
- 在P3和P4融合(第3行),“人”和“车”的AP反弹,总mAP升至82.0%
- 在P3、P4和P5(深层)全部融合(第4行),达到了最佳平衡,mAP@0.5达到83.3%,并且“自行车”的AP达到74.9%,为所有配置中最高
- 这表明多层次特征融合(浅层细节+深层语义)对于跨模态特征集成至关重要,特别是对“自行车”等挑战性类别
CP-SSM 的讨论
表13: CP-SSM 的微调
| 编号 | 微调 | 人 | 汽车 | 自行车 | mAP@0.5 |
|---|---|---|---|---|---|
| 1 | rows | 85.1 | 89.8 | 74.9 | 83.3 |
| 2 | columns | 64.1 | 90.3 | 72.8 | 82.4 |
| 3 | rows and columns | 85.4 | 90.4 | 70.2 | 82.0 |
| 4 | w/o exchange C | 85.7 | 90.6 | 71.7 | 82.7 |
| 5 | exchange C | 85.1 | 89.8 | 74.9 | 83.3 |
分析: 表13探索了CP-SSM的两个关键设计:
- 扫描方向 (row 1-3): 实验发现,仅按行(rows)扫描(第1行)效果最好(83.3% mAP)。使用多方向扫描(rows and columns,第3行)反而导致性能下降(82.0% mAP),可能是因为它改变了目标特征,不利于检测任务所需的稳定性
- C参数交换 (row 4-5): 对比“不交换C”(第4行,82.7% mAP)和“交换C”(第5行,83.3% mAP),发现交换C参数的机制(即跨模态分支交换隐藏状态投影矩阵)带来了**0.6%**的稳定性能提升。这证明了该设计能有效优化跨特征交互效率
不同输入模态的比较
表14: 不同输入的性能
(V, T 分别表示可见光和热成像。V+T表示双模态输入,V+V或T+T表示单模态输入。)
| 编号 | 模型 | 输入 | mAP@0.5 |
|---|---|---|---|
| 1 | YOLOv5 | V | 67.8 |
| 2 | T | 73.9 | |
| 3 | Baseline | V+V | 61.2 |
| 4 | T+T | 77.8 | |
| 5 | V+T | 80.0 | |
| 6 | Ours | V+V | 68.4 (+7.2) |
| 7 | T+T | 82.1 (+4.3) | |
| 8 | V+T | 83.3 (+3.3) |
分析: 表14展示了MS2Fusion在处理缺失模态时的鲁棒性。
- 在所有输入配置下(V+V, T+T, V+T),Ours(MS2Fusion)均显著优于Baseline(基线)
- 当仅使用热成像(T+T)时(第7行),Ours的性能(82.1% mAP)仅比使用双模态(V+T)时(第8行,83.3% mAP)低1.2%,显示了极强的鲁棒性
- 这表明MS2Fusion能有效利用异构数据的共享空间特征,利用一个可用的模态信息来增强另一个模态的特征
FF-SSM 输入配置分析
表15: FF-SSM 模块的输入配置
| FF-SSM input | mAP@0.5 | person | car | bicycle |
|---|---|---|---|---|
| (V, T) | 83.1 | 85.4 | 90.2 | 73.9 |
| (T, V) | 82.5 | 85.1 | 90.1 | 72.4 |
| ((V, T), (T, V)) | 83.3 | 85.1 | 89.8 | 74.9 |
分析: 表15研究了FF-SSM模块的输入顺序。
- 使用单向输入 (V, T)(第1行)或 (T, V)(第2行)时,mAP分别为83.1%和82.5%,均低于基线(83.3%)
- 这揭示了状态空间模型中存在的特征衰减(遗忘)现象:较早输入的特征在状态传播过程中逐渐被遗忘
- 而使用本文提出的双向架构 ((V, T), (T, V)) (第3行)时,性能恢复并达到最佳(83.3% mAP),“自行车”检测(74.9%)也得到改善
- 如图9(ERF可视化,未显示)所示,双向策略建立了鲁棒的跨模态特征记忆路径,显著扩大了有效感受野(ERF),从而在保持线性复杂度的同时缓解了特征衰减

定性分析
模型统计分析
表16: 模型的统计分析 (释放随机种子进行10次实验)
| Mean(%) | VAR(%) | |||
|---|---|---|---|---|
| mAP@0.5 | mAP | mAP@0.5 | mAP | |
| FLIR | 82.99 | 40.60 | 0.15 | 2.47 |
| LLVIP | 97.41 | 63.46 | 0.03 | 2.31 |
| M3FD | 89.11 | 59.76 | 0.18 | 0.42 |
分析: 如表16所示,通过10次随机种子实验,MS2Fusion表现出极高的稳定性。在FLIR上mAP@0.5方差仅为0.15%,在LLVIP上方差低至0.03%。这表明模型对初始条件变化具有很强的抵抗力,在不同数据分布上保持一致性能。
热图可视化 (图10)
对比Baseline、ICAFusion和MS2Fusion:
- 在停车场(第一行)、夜间街道(第二行)和道路(第三行)等多种场景下,MS2Fusion均表现最佳。
- 优势: (1) 相比CNN基线,MS2Fusion的感受野更广,能捕获更宽的对象区域;(2) 相比Transformer (ICAFusion),它实现了更精确的轮廓拟合;(3) 假阴性率(漏检)最低,尤其是在低光照条件下。

特征融合比较可视化 (图11)
对比P5层的特征图 (Baseline vs MS2Fusion):
- Baseline(简单求和)导致信息丢失或模态冲突。
- MS2Fusion通过其多阶段框架(CP/SP/FF),能选择性保留每个模态中最具辨识度的特征,同时抑制冗余,生成更丰富、更清晰的特征图。
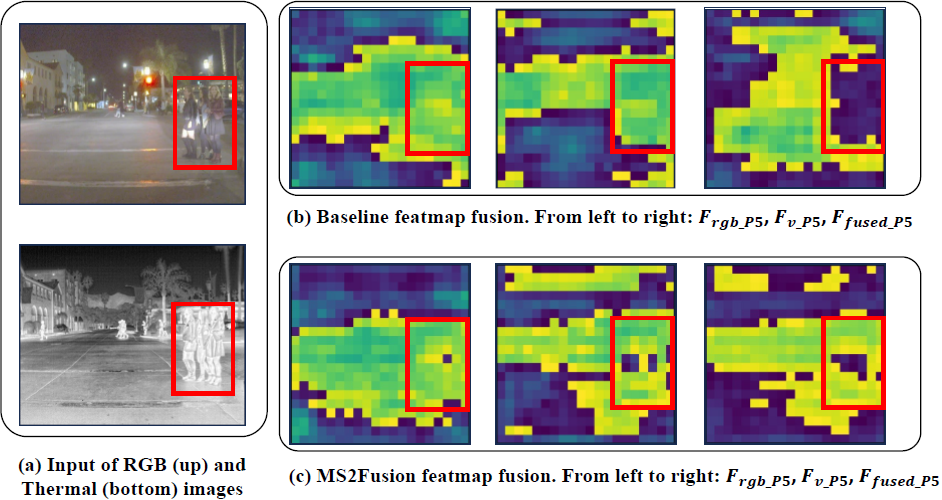
共享和互补特征的可视化分析 (图12)
在低光照条件下可视化CP-SSM和SP-SSM的输出:
- 由于RGB模态特征弱,CP-SSM(互补特征)主要关注模态特定差异(如热梯和纹理)。
- SP-SSM(共享特征)则有效融合了两个模态,生成了跨RGB和热域一致的共享语义表示(如物体轮廓、行人区域)。SP-SSM通过强制语义一致性补偿了可见光谱的退化。

RGB-T 语义分割样本可视化 (图13)
对比Baseline和MS2Fusion的分割结果:
- Baseline在处理行人和车辆边界时表现模糊且存在误分类。
- MS2Fusion在这些挑战区域表现出显著改进,能保持对象轮廓的精细细节和复杂背景下的分割一致性。

RGB-T 显著性目标检测样本可视化 (图14)
对比Ours (MS2Fusion) 和其他SOTA方法:
- 优势: (1) 利用跨模态互补性生成精确的对象边界,噪声干扰最小(第1, 5行);(2) 在遮挡场景中鲁棒性强,保持了完整的物体形态(第2行);(3) 对小物体(第4行)和复杂形状(第3, 6行)具有出色的敏感性。

局限性 (图15)
分析了几个失败案例:
- 远处物体: 当物体距离远且在热图像中不突出(热信号与背景接近)时,模型难以区分物体和背景。
- 遮挡物体: 模型倾向于忽略部分或完全被遮挡的物体,导致漏检。
- 热相似物体的假阳性: 具有与人相似热特征的物体(如第3行)会导致假阳性检测,尤其是在低分辨率图像中,模型难以区分。

结论
本论文提出了**多光谱状态空间特征融合(MS2Fusion)**框架,旨在解决现代多光谱目标检测中存在的两个关键限制:一是过度偏向局部互补特征,而忽略跨模态共享语义,影响了泛化性能;二是感受野尺寸和计算复杂度之间的权衡,是可扩展特征建模的关键瓶颈。
MS2Fusion基于状态空间模型(SSM),通过双路径参数交互机制实现了高效且有效的特征融合。
- **共享参数交互(SP-SSM)**分支:通过在SSM中共享参数,探索跨模态对齐,以获得相似的语义特征和结构。
- **交叉参数交互(CP-SSM)**分支:利用SSM中的跨模态隐藏状态解码,继承了交叉注意力的优势,以挖掘互补信息。
这两种路径在一个统一的框架内通过SSM进行联合优化,使MS2Fusion能够同时享有功能互补性和共享语义空间。得益于这种双分支SSM设计,本方法同时继承了计算效率和全局感受野的优点,显著提高了多光谱目标检测的性能。
实验结果表明,MS2Fusion持续优于现有强大的基线方法:
- 在目标检测(FLIR)任务中,mAP@0.5提高了3.3%。
- 在RGB-T语义分割(MFNet)任务中,mIoU提升了2.8%。
- 在显著性目标检测(VT5000)任务中,MAE降低了0.7%。
值得注意的是,MS2Fusion无需针对特定任务进行修改,即可在多个多光谱感知任务上实现新的最先进(SOTA)结果,充分证明了其卓越的泛化能力。