【论文阅读 | TCSVT 2024 | MMI-Det:探索可见光与红外目标检测的多模态融合】
[TOC]

题目:MMI-Det: Exploring Multi-Modal Integration for
Visible and Infrared Object Detection
期刊:TCSVT(IEEE Transactions on Circuits and Systems for Video Technology)
论文链接:Link
关键词:Multi-spectral object detection(多光谱目标检测), multi-modal integration(多模态融合), image fusion(图像融合), Fourier transformation(傅里叶变换).
代码:开源
年份:2024
摘要
可见光-红外(VIS-IR)目标检测是一项具有挑战性的目标检测任务,其通过融合可见光(RGB)图像数据和红外(IR)图像数据,以提供场景中目标的类别和位置信息。因此,该任务的核心在于融合可见光和红外模态中的互补信息,从而为检测提供更优的目标检测结果。现有方法主要面临对可见光-红外模态信息的感知与融合能力不足,以及难以平衡融合与检测任务优化方向的问题。为解决这些问题,我们提出了MMI-Det,一种用于可见光-红外目标检测的多模态融合方法。该方法能够实现可见光-红外模态中互补信息的良好融合,并输出准确且鲁棒的目标信息。具体而言,为提升模型在可见光-红外图像层面的环境感知能力,我们设计了轮廓增强模块(Contour Enhancement Module)。此外,为从可见光和红外模态中提取互补信息,我们设计了融合聚焦模块(Fusion Focus Module),该模块能够提取可见光和红外模态的不同频率谱特征,并聚焦于不同空间位置的目标关键信息。同时,我们设计了对比度桥接模块(Contrast Bridge Module),以提升在可见光-红外场景中提取模态不变特征的能力。最后,为确保模型能够平衡图像融合与目标检测的优化方向,我们设计了信息引导模块(Info Guided Module),以提升模型训练优化的有效性。我们在公开的FLIR、M3FD、LLVIP、TNO和MSRS数据集上进行了大量实验,与现有方法相比,我们的方法凭借强大的多模态信息感知能力取得了更优的性能。
引言
先前方法
目标检测是计算机视觉领域的一个基本问题。为了确认和定位图像中某些特定类别的实例,目标检测已经被研究了许多年。然而,现有方法主要聚焦于可见光(RGB)下的目标检测,因此这便限制了目标检测的检测范围——难以在夜间准确识别目标。为了实现全天候、动态环境下的目标检测,满足多领域的需求,可见光-红外目标检测因具有更广泛的应用前景而被提出,并日益受到该领域研究者的关注。可见光-红外目标检测需要融合两种模态下目标的互补信息,以感知场景中目标的位置和类别。然而,由于两种模态之间存在较大的异质性差异,如何感知并提取模态间的关键信息成为一个具有挑战性的问题。
可见光和红外线这两种模态的图像之间存在显著差异。为了补充这些差异显著的可见光-红外图像的信息,目前一些可见光-红外(VIS-IR)目标检测方法采用两阶段方法设计模型,此方法可概括为“先融合,后检测”。这些方法通过设计多种图像融合策略生成包含更丰富信息的融合图像,并基于这些融合图像,利用单模态目标检测方法对融合图像中的目标进行检测。然而当前的实现方法将融合与检测划分为两个独立的优化任务,难以保持两个任务的优化方向一致。因此这些方法可能导致更差的检测结果。因此,如何使模型能够充分提取两种模态的互补信息,为后续检测任务提供更丰富的目标特征信息,已成为一个重要问题。
为了解决可见光-红外目标检测中的上述问题,我们尝试设计一种利用多级模态融合的新架构。在本文中,我们提出一种针对可见光和红外目标的多模态融合方法:MMI-Det
主要贡献
我们提出了MMI-Det,一种用于VIS-IR目标检测的新框架。该框架提供了一种联合优化融合与检测任务的解决方案,从而实现了准确且鲁棒的多光谱目标检测结果。在公开数据集(FLIR、M3FD、LLVIP、TNO、MSRS)上进行的大量实验证明了我们的MMI-Det 的有效性,其性能优于先前的方法;
我们提出轮廓增强模块(Contour Enhancement Module),该模块有助于方法感知复杂动态场景中物体的轮廓,并提升目标检测性能;
我们设计了融合聚焦模块(Fusion Focus Module),以使得该方法能够在不同空间区域下感知并融合可见光-红外模态的目标细节信息;
对比度桥接模块(Contrast Bridge Module) 旨在利用对比学习的思想,将可见光-红外数据分离为正负样本对。其能够引导模型提升在可见光-红外场景中感知模态不变特征的能力;
信息引导模块(Info Guided Module) 旨在引导我们的模型在训练过程中更有效地融合两种模态的特征信息。
方法
先前方法
A. 图像融合
目前已经有许多较为成熟的图像融合方法:
- CCAFusion由Li 等人提出,设计了一种基于坐标注意力的跨模态图像融合策略,该策略由特征感知融合模块和特征增强融合模块组成;
- UNFusion由Wang 等人提出,他们引入了一个统一的多尺度密集连接融合网络,使用一个多尺度编码-解码架构来提取和重建多尺度深度特征;
- Laplacian pyramid fusion network由Yao 等人提出利用层级指导来使用像素级的可见性保留的Laplacian 阳光来生成层级可见性地图;
- DATFuse由Tang 等人提出,它引入了一个用于重要特征提取的双注意力残余模块来实现图像融合;
- Unsupervised Image Fusion Network由Xu 等人提出,该网络可通过特征提取和信息测量源图像的重要性;
- Deep Network Cascade Feature Learning Module由Liu 等人提出。他们的方法采用了一种从粗到细的深度架构来从多模态图像中学习多尺度特征;
- Tang 等人受生物视觉系统的启发,深入研究了早期视觉信息处理的建模机制建模。他们的可见光-红外图像融合方法利用了两种模式的优势。他们随后提出了一种光感知渐进式图像融合网络,称为 PIAF融合网络。
然而,尽管上述方法探索了可见光红外图像融合的各种潜力,但这些方法将融合和检测分为两个独立的优化任务,很难保持两个任务的优化方向一致。
这意味着图像融合的最佳区域通常不是物体检测的最佳区域,从而导致图像融合效果不理想。
B. 多光谱目标检测
多光谱目标检测方法采用两阶段训练方式,将融合与检测看作两个独立的任务分别进行优化,这可能导致两者之间的优化目标不一致。研究人员,意识到这一局限性,因此开发了新的多光谱目标检测方法,将图像融合与检测整合到一个统一的框架中。
Wagner等人提出了一种融合-精化(fuse-and-refine)方法,该方法采用循环图像融合方式,通过迭代精化每个光谱特征以提升检测性能;
Fang等人则采用了不同的方法,将Transformer与YOLO检测框架相结合,设计了一种适用于可见光-红外(VIS-IR)检测任务的多光谱检测方法;
Yun等人提出了跨模态与模态内加权交叉融合网络(Infusion-Net),该网络通过利用可见光-红外图像对的优势来增强目标检测性能;
Zhou等人提出了一种可见光-红外特征融合网络,该网络通过双边逆融合提取目标边界,并通过多级融合捕获互补信息。
然而,尽管这些方法将融合与检测任务整合到单一建模框架中,但它们在探索面向检测的可见光-红外模态特征融合方面仍存在不足,且在自主且全面地融合多光谱信息方面尚未得到充分研究。因此,如何使模型充分提取两种模态的互补信息,为后续检测任务提供更丰富的目标特征信息,成为一个重要问题。
C. 基于频率的特征提取方法
频域分析作为图像信号处理领域的基石,在图像分类、纹理提取、图像融合以及超分辨率等众多领域发挥了重要作用。
为解决人脸活体检测问题,Stuchi等人提出了一种基于傅里叶分析的特征提取方法。
Xiao等人设计的FAFusion通过提取可见光-红外图像对中的高频信息来感知物体边缘和纹理细节,从而增强融合图像的细节。
此外,针对图像超分辨率问题,Li等人设计了一种基于频域变换的网络,该网络利用卷积定理将空间域的卷积运算转化为频域的乘积运算。
Fang等人提出了一种基于高频Transformer的网络,用于磁共振图像的超分辨率重建。
尽管上述方法已从不同角度研究了多种基于频率的特征提取方法,但如何在可见光-红外场景中利用频域分析以提升模型在复杂场景中感知物体位置和轮廓的能力仍有待进一步探索和研究。
不足
总而言之,现有方法存在的不足主要聚焦于以下方面:
- 模态信息感知与融合能力不足:可见光(380-780nm)侧重纹理色彩,细节偏多,红外(760nm-1mm)侧重温度差异,注重目标,二者异质性强,现有方法难以充分提取互补特征,甚至融合后会削弱目标判别性。
- 融合与检测任务优化方向失衡:传统 “先融合后检测” 的两阶段方法,将融合和检测视为独立任务,优化目标不一致;“单阶段联合模型” 虽整合两者,但未深入探索 “面向检测的模态融合”,对于多光谱信息的利用不够充分。
本文所提出的方法
A. 整体流程
输入可见光()和红外图像()→ 经轮廓增强模块(CEM)提取目标轮廓 → 经 FOC 模块降维 + Conv/C3 模块增强特征 → 对比桥接模块(CBM)学习模态不变特征信息 → 融合聚焦模块(FFM)融合多模态特征 → 多次循环后经 Detect Head 输出结果 → 信息引导模块(IGM)平衡图像融合与目标检测优化方向 → 检测头输出目标类别与位置
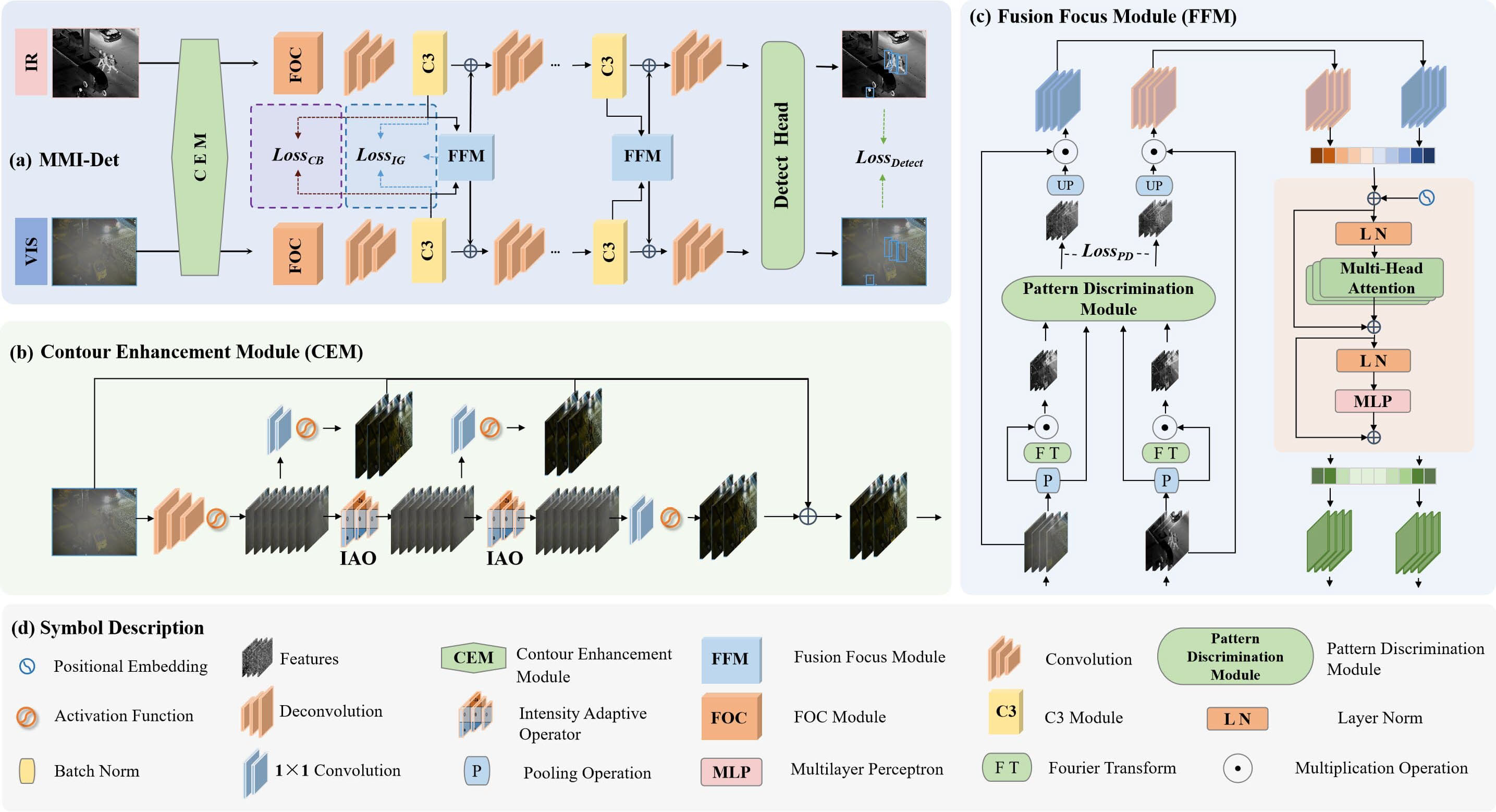
B. 总体结构
- 基于双流YOLOv5框架
轮廓增强模块 Contour Enhancement Module(CEM)
在输入模态上用 2D 卷积和 LeakyReLU 激活函数初步提取并增加特征通道,将传统的固定轮廓增强算子改为强度自适应算子(IAO),通过自适应参数 a 提升模型对复杂动态场景中物体轮廓感知能力,多个 IAO 在不同深度组合并利用残差连接优化,帮助模型浅层整合模态信息。
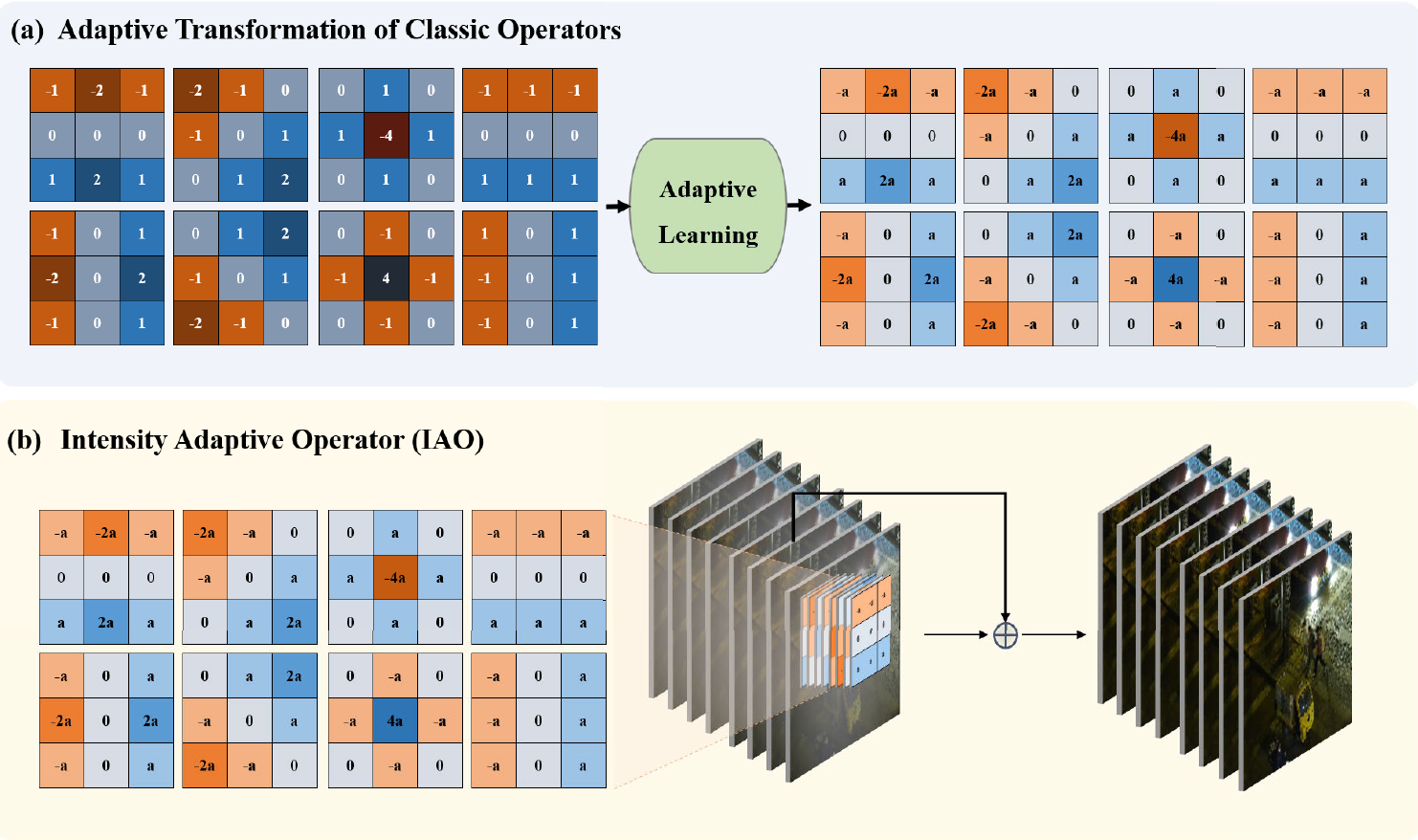
轮廓增强模块。(a) 自适应经典算子变换。该模块的策略:先将经典算子与输入图像进行卷积,再通过自适应学习调整结果。(b) 强度自适应算子,其中8个算子形成一个自适应二维卷积,基于当前环境自适应地增强模型对目标的轮感知能力,直接用强度自适应算子与输入图像卷积,然后将不同深度的特征图经残差连接融合,形成多尺度特征表示,以实现精确的可见光-红外目标检测。
对于输入图像,令V和I分别表示可见光图像和红外图像。则可见光图像的输入可表示为
红外图像的输入可表示为
其中C、H和W分别对应图像的通道、高度和宽度。
在一个批次的训练过程中,共有B幅图像,其中和的数量相同,。输入的可见光-红外图像将首先通过轮廓增强模块(Contour Enhancement Module),如下式所示:
在此,和表示经过CEM处理后的可见光-红外特征。接下来,为了使特征在不丢失过多信息的前提下能够在计算上进行降维,我们引入了FOC,该方法使用切片操作,将高分辨率特征图分割为多个低分辨率特征图。FOC的这种策略性分割以紧凑形式保留了关键空间信息,在促进更快处理的同时,保持了准确目标检测所需的特征完整性。这些FOC模块的输出特征被输入至Conv和C3模块。C3采用多尺度特征融合方法和跨通道信息传递机制来提升特征表示能力。通过将FOC与C3有效结合,网络同时受益于降维和特征丰富性,从而提升了检测性能。需要注意的是,FOC和C3均已在YOLOv5中可用。该过程如下所示:
公式2中的Conv模块和C3模块能够提升模型的特征提取能力。为了引导模型进行有效的训练优化,我们借鉴对比学习的思想设计了对比桥接模块(Contrastive Bridge Module, CBM),并设计了损失函数 :
融合聚焦模块 Fusion Focus Module(FFM)
该模块结合频谱提取、模式判别和 Transformer。
- 频谱提取模块依傅里叶变换提取高低频特征分离细节与背景信息;
- 模式判别模块融合多种特征并通过损失函数促进特征分化与空间注意力生成;
- Transformer 自注意力机制融合互补信息,增强模型对不同模态特征提取融合能力。
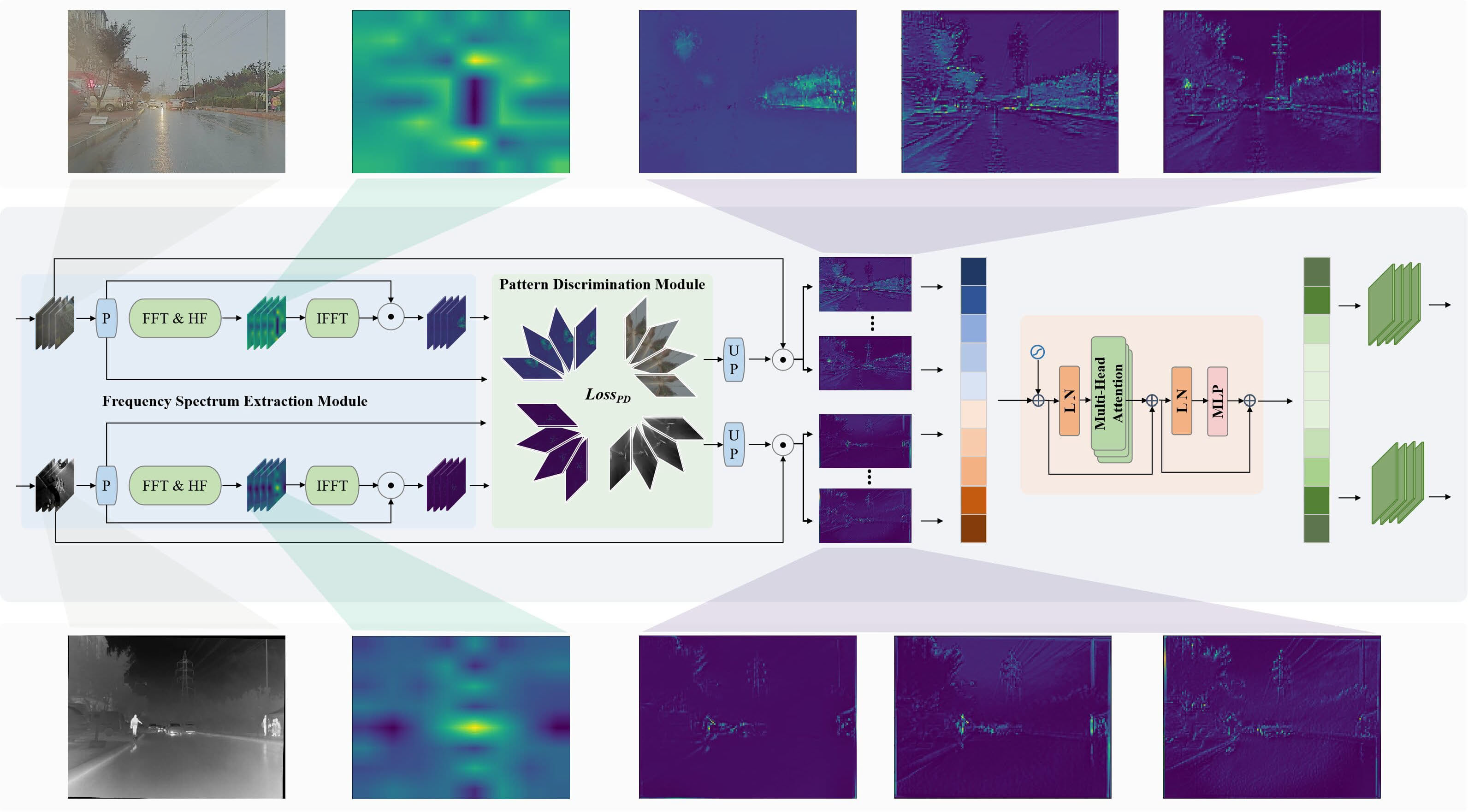
上图展示了融合聚焦模块。FFM 从频谱提取模块开始、提取特征的高频信息以获取物体的细节信息。其在频谱提取模块先将图像从空间域转换到频域,再提取频域中的高频信息,然后通过逆快速傅里叶变换(IFFT)将频域信息转换回空间域。频谱提取模块输出的特征进入此模块,模块内有损失函数用于优化特征的判别能力,还有多个线性层和归一化操作,用于进一步处理特征,通过这些操作增强特征的空间感知能力,使得目标检测准确进行。在特征融合与输出部分,经过模式判别模块处理的特征进入 Transformer 块,在其中可见光和红外特征被合并,最终分别输出可见光和红外特征经过 FFM 处理后的结果。
在这个过程中,可用作损失函数以引导模型学习模态不变信息。经过上述模块后,可见光特征与红外特征被输入至融合聚焦模块(Fusion Focus Module, FFM)。MMI-Det设计了多个FFM用于不同深度的特征融合。具体而言,FFM的结构如下式所示:
FFM 充分融合两种模态特征,并将融合后的特征反馈至两个分支。它们与在各自的分支上的特征相加,并一同被发送至下一个特征提取-融合阶段:
在上式中,相加特征和被传送到后续阶段,我们设计了共组此类阶段,以从不同深度充分提取两种模态中的目标信息。当前阶段的融合特征将被保存为。最终结果通过检测头(Detect Head)输出,如下图所示。相关公式如下:
对比度桥接模块 Contrast Bridge Module(CBM)
一句话概括便是——学习模态不变特征,缩小模态差距
基于对比学习思想,构建正负样本对:将同组 VIS-IR 特征设为正样本(),不同组设为负样本(),用损失优化:让正样本特征距离更近、负样本距离更远,引导模型自主发现模态共性(如目标边界梯度)。即计算样本对距离并构建对比损失函数,引导模型自主发现模态不变信息,提升对复杂场景适应能力。
对比学习机制的工作原理
对比学习机制就像是让机器学会“找不同”和“找相同”。
找不同(负样本对)
1数据准备
我们有可见光图像和红外图像(呈现热量分布的图像)。
从这两种图像里找出不同的东西组成一对,这就是负样本对。比如可见光图像里是个人,红外图像里是辆车,这就是一对负样本。
2学习过程
机器要学习把这对负样本中的特征尽量分得开。想象一下,机器要把可见光里的人和红外里的车看成完全不一样的东西。
这样,机器在处理新的图像时,就能很容易区分出不同的物体了。
找相同(正样本对)
1数据准备
还是从可见光和红外图像里找,不过这次是找相同的东西组成一对,这就是正样本对。比如可见光图像里是个人,红外图像里也是这个人,这就是一对正样本。
2学习过程
机器要学习把这对正样本中的特征尽量拉得近。就好像机器要知道,不管是在可见光里还是红外里,这个人都是同一个人。这样,机器在处理新的图像时,就能很容易认出同一个物体了。
通过不断地这样 “找不同” 和 “找相同”,机器就能更好地理解和处理可见光和红外图像,在目标检测、识别等任务中表现得更好
信息引导模块 Info Guided Module(IGM)
基于 FFM 输入输出的结构相似性和信息熵设计损失函数,通过调整权重因子平衡两者贡献,引导模型有效学习复杂模态信息,平衡图像融合与目标检测优化方向。
由上式可得知, 是由C3模块和FFM模块决定的。简单来说,模块可以在运行时自调节自优化,这尤其体现在多模态融合和目标检测方面。
具体来说,IGM 函数可能会根据这些特征的结构相似性信息熵等指标来计算损失,以确保模型在融合多模态信息时能够有效地平衡图像融合与目标检测的优化方向。
C.总损失函数
通过加权组合各模块损失,实现多任务联合优化:
其中:,(检测损失权重最高,确保检测性能);为 YOLOv5 原检测损失(边界框 + 类别 + 置信度损失)。
实验
论文在 5 个公开数据集(FLIR、M3FD、LLVIP、TNO、MSRS)上做了全面实验,核心结果如下:
1. 定量实验:性能领先
对比单模态(YOLOv5/YOLOv7)、两阶段(如 U2Fusion、SwinFusion)和单阶段(如 CFT、Infusion-Net)方法,MMI-Det 在关键指标(mAP50、mAP)上均最优,以代表性数据集为例:
- FLIR 数据集(驾驶场景):MMI-Det 的 mAP50 达 79.8%,超过 Infusion-Net(79.1%)和 CFT(78.7%);
- M3FD 数据集(多场景):MMI-Det 的 mAP50 达 76.6%,mAP 达 42.7%,且 GFLOPs(229.2)低于 SwinFusion(764.8),兼顾性能与效率;
- LLVIP 数据集(安防场景):mAP50 达 98.9%,mAP75 达 73.5%,在低光场景下表现突出。
2. 消融实验:模块必要性验证
逐一添加模块到基线模型(YOLOv5 双分支),结果证明各模块均有贡献:
- 仅加 CEM:mAP 从 40.8% 提升至 41.2%,验证轮廓增强的作用;
- 加 CEM+FFM:mAP 提升至 42.4%,体现融合模块的核心价值;
- 加全模块:mAP 达 42.7%,且参数(207.6M)和计算量(229.2 GFLOPs)可控,证明模块协同有效性。
3. 定性实验:复杂场景鲁棒性
在雾、烟、远距离重叠等场景中,MMI-Det 优势明显:
- 雾天 / 烟场景:传统方法(如 ICAFusion、UNFuse)易漏检或误检(如将远山轮廓判为行人),MMI-Det 通过 CEM 和 FFM,能准确捕捉目标轮廓;
- 远距离重叠场景:U2Fusion 等两阶段方法因优化失衡漏检,MMI-Det 通过 IGM 平衡任务,实现精准检测。